
데이터로 한국의 2030년 탄소 배출량 목표를 제안한다면
쏘프라이즈에 제출한 글이며, 데이터를 기반으로 한국 탄소배출량의 2030년 감축 목표를 제안할 수 있을까? 라는 질문에 대한 답입니다. 여기 에서도 볼 수 있습니다. 한국의 2030년 탄소배출량 감축 목표를 제안하기 위해 데이터를 살펴봤습니다. [상태 점검] 우선 전반적인 탄소배출량 지표와 인구/경제 성장 면에서 한국과 가장 비슷한 위...
쏘프라이즈에 제출한 글이며, 데이터를 기반으로 한국 탄소배출량의 2030년 감축 목표를 제안할 수 있을까? 라는 질문에 대한 답입니다. 여기 에서도 볼 수 있습니다. 한국의 2030년 탄소배출량 감축 목표를 제안하기 위해 데이터를 살펴봤습니다. [상태 점검] 우선 전반적인 탄소배출량 지표와 인구/경제 성장 면에서 한국과 가장 비슷한 위...
콜모고로프-스미르노프 검정와 바서슈타인 거리를 포함하여 단변량 분포 간의 거리 함수를 다룹니다. Detecting Anomalies Using Statistical Distances / SciPy 2018 를 바탕으로 정리한 내용입니다. 주어진 베이스라인 분포가 있을 때 이를 새로운 데이터의 분포와 비교해서 둘이 다른지 확인하고 싶다고 합시다...
주로 데이터 편향에서 비롯되는 스파크 성능 저하 또는 처참한 실패에 부딪혔을 때, 시도해 볼 수 있는 코드 작성 수준의 스파크 성능 최적화 방법들을 알아보았습니다. 이 글을 쓰게 된 이유 저는 회사에서 일정 시간마다 돌아가는 스파크 배치 잡을 pyspark로 작성하는 일이 많습니다. 며칠 전에 등록한 배치 잡이 실패한 일이 있었는데요. 처음...
Pygame은 다양한 사용자 입력 처리와 사운드, 그래픽 제공을 통해 python으로 간단한 게임을 만들 수 있게 해주는 라이브러리입니다. 이 글은 pygame을 사용하여 처음 작은 게임 하나를 시도해 본 후기로, 처음 사용하는 사람을 위한 소소한 가이드와 함께 시작합니다. 기초만 뽑은 Pygame 가이드 화면 설정 일단 설치하는 것은...
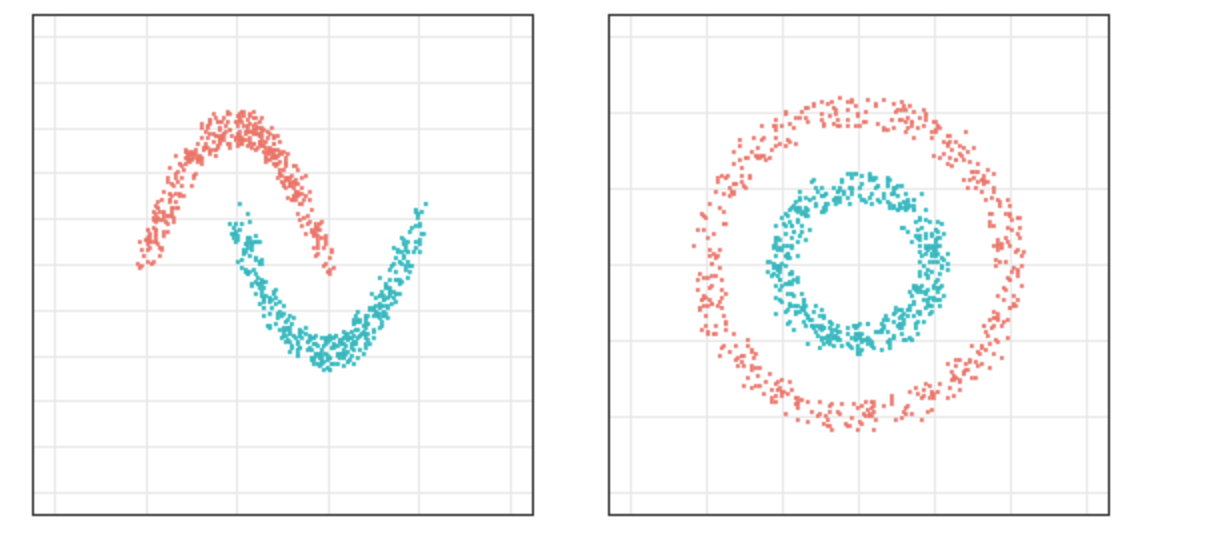
스펙트럴 클러스터링을 어떻게 하는지에 대한 글이며 써보기보다는 이해하기를 목적으로 적었습니다. 뭘까? 스펙트럴 클러스터링은 클러스터링, 즉 군집화 기법의 일종입니다. 클러스터링의 기본 목적은 주어진 라벨 없는 데이터에 대해 비슷한 것끼리 군집으로 묶어주는 것이죠. 비슷한 것들은 같은 군집에 속하고 다른 것들은 다른 군집에 속하도록 합니다. ...

중고차 가격 데이터를 가지고 Koalas를 이용한 UDF 작성과 머신러닝을 해봅니다. Pandas는 보통 데이터 분석을 배울 때 가장 먼저 접하는 도구 중 하나입니다. 자고로 데이터 분석 기초 코스의 맨 첫 줄이라면 타이타닉 데이터셋을 pd.read_csv 로 불러오는 것 아니겠어요? 그렇게 Pandas 데이터프레임이 어떻게 생겼는지 살펴보고...
지난 몇 년 간 자연어처리 분야에서는 BERT, ALBERT, XLNet, ELECTRA처럼 사전훈련된 모델을 다운스트림 태스크를 위해 파인튜닝하는 것이 가장 좋은 성능을 낼 수 있는 선택이었습니다. 이 과정에서 모델은 필연적으로 훈련 데이터에서 특정 단어, 혹은 특정 개념들 간의 강한 상관을 학습하게 됩니다. 그러나 어떤 상관은 잘못 형성되면 사회적...
이 글은 Causal Inference in Statistics: A Primer의 4장 내용을 기반으로 작성하였습니다. 읽기 전에 인과 추론에서의 그래프 모델 소개를 읽고 오시면 쉽습니다. 많은 통계적 연구의 최종적 목적은 가능한 행동의 효과를 예측하는 것입니다. 예를 들면, 산불 발생에 영향을 미치는 데이터를 모으고 싶다 → 어떤 ...
이 글은 Causal Inference in Statistics: A Primer의 2장과 3장 내용을 기반으로 작성하였습니다. 읽기 전에 독립과 조건부독립에 대한 개념과 그래프의 기본 구조 개념 이해가 필요합니다! 구조적 인과 모델 (Structural Causal Model) 인과와 관련된 질문에 답을 하려면, 주어진 데이터를 설명하는 ...
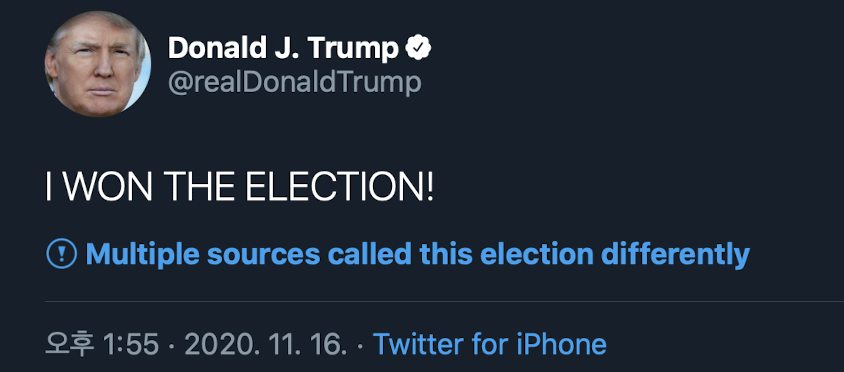
자연어처리 기술에 기반한 자동화된 팩트 체킹(Automated Fact Checking)의 현주소를 알아보고, ACL 2020에 등장한 관련 연구들을 소개합니다. 미국 대선을 볼 때마다 한국 사람으로서 가장 놀라운 점 중 하나는 개표 속도가 아닐까 합니다. 아니 선거가 11월 3일인데 7일에 당선인이 정해지다니! 게다가 (이번에도) 트럼프가 ...