데이터와 모델만 있으면 끝인 건가? 에 대한 단상
이번 주에 인턴 면접에 상당한 시간을 쓰면서 새삼스럽게 체감한 사실: 간단한 통계 지식을 물어봤을 때 대답을 못하는 경우가 정말 많다. 이 비율은 어느 정도를 상상하든 그 이상이다! 정말 기초 통계 수업 세번째 시간쯤에서 배우는 내용에 대해서 질문했는데 답을 못해서 식은땀을 흘리시는 분을 보고 나도 식은땀이 났다. 이건 사실 비전공자 전공자(라는 구분...
이번 주에 인턴 면접에 상당한 시간을 쓰면서 새삼스럽게 체감한 사실: 간단한 통계 지식을 물어봤을 때 대답을 못하는 경우가 정말 많다. 이 비율은 어느 정도를 상상하든 그 이상이다! 정말 기초 통계 수업 세번째 시간쯤에서 배우는 내용에 대해서 질문했는데 답을 못해서 식은땀을 흘리시는 분을 보고 나도 식은땀이 났다. 이건 사실 비전공자 전공자(라는 구분...
패스 2회를 썼고, 1회는 그냥 제출에 실패했다. 글또를 꽤 길게 했지만 패스 외의 그냥 제출 실패를 한 적은 없었기 때문에 조금 아쉬웠지만, 여러 가지 이유로 시간과 인지적인 자원 확보가 상당히 힘들었던 상반기였기 때문에 이 정도면 나쁘지 않았다고 평가하고 싶다. 너무 스마트해진 글또…! 또봇이 제출 내역을 보여준다 다짐글에서 다짐을 몇 가지 ...
AI 때문에 인류가 망할 수 있을까? 우리는 지금 뭘 해야 하나? 에 대해서 최근에 읽고 들었던 이야기들을 정리해보았습니다. 몇 달 전 Future of Life Institute에서 낸 공개서한이 큰 화제였습니다. “6개월 동안 우리 다 같이 GPT-4보다 강력한 수준의 AI를 개발하는 것을 멈춰보자”라는 내용이었고, 오늘날의 AI 시스템이...
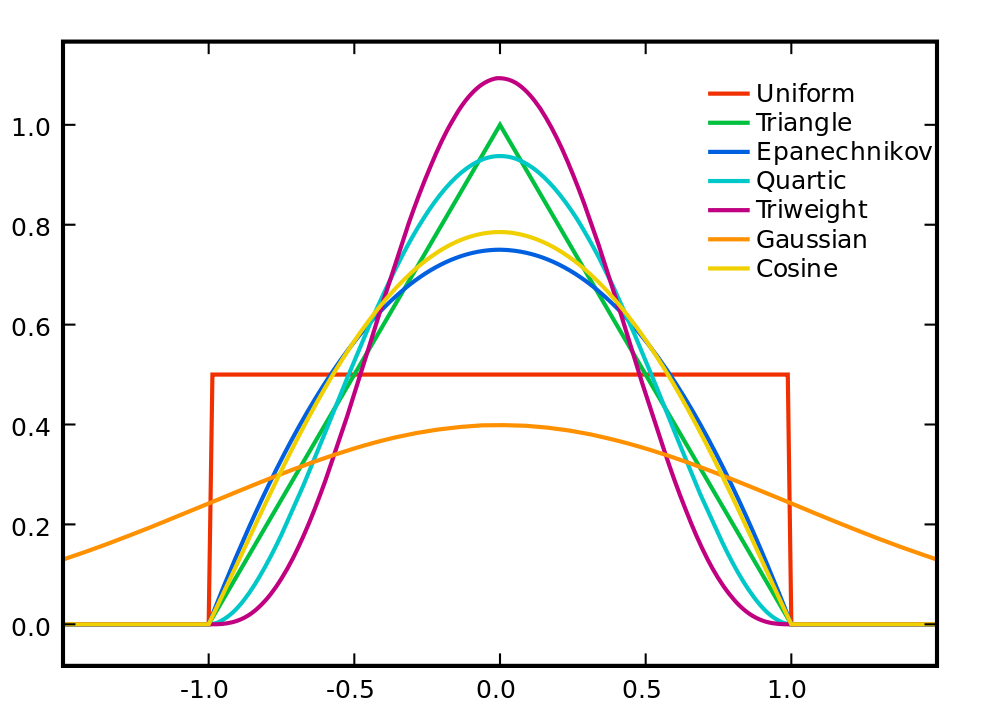
여기저기서 등장하는 커널(Kernel)이란 개념을 쉽게 이해하고자 정리한 내용입니다. 커널 밀도 추정, 커널 회귀, 커널 SVM을 다룹니다. 학습을 할 때, 공통적인 개념이 존재하는데 개념이 아닌 응용부터 배우다 보니 각 응용법이 개별적으로만 인식이 되고, 공통적인 개념 기준으로는 머릿속에서 잘 끼워맞춰지지가 않을 때가 있습니다. 저에겐 바로...
최근에 면접 들어갔다가 나오면서 문득 아 이제 면접관으로 들어가는 것도 좀 익숙해진 것 같다 라는 느낌을 받았다. 그 김에 되짚어 보니, 팀에서 분석가를 뽑는 데 처음 참여하기 시작했던 게 딱 1년 전쯤이었다. 처음에는 서류/과제 검토하고 1차 면접(흔히 말하는 직군 면접 or 기술 면접) 위주로 들어갔었고, 지금은 팀 리더로 전체적인 프로세스에 관여...

GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models (2023) 를 읽어보았습니다. AI가 우리 일자리를 뺏어갈까? 라는 질문은 사실 AI라는 단어가 나오면서부터 계속 화두였습니다. 딱히 신선한 질문은 아니고, 굉장히 오래된 불안거리...
Why do tree-based models still outperform deep learning on typical tabular data? (2022) 를 읽어보았습니다. 오늘은 각종 딥러닝 모델이 정형 데이터에서 결정 트리 기반의 앙상블 모델(이하 트리 모델)에 비해 성능이 떨어지는 현상을 분석하고 3가지 발견을 가능한 원인으로 제시한...
어떤 목적으로 업무 기록을 작성하고, 어떻게 작성하는지에 대해 적은 글입니다. Craft를 사용했지만 다른 어떤 종류의 노트 앱이라도 괜찮습니다. 업무 기록 : 영업편 우선 업무를 왜 기록해야 하는지를 이야기해보겠습니다. 가장 중요한 것은 업무를 기록하는 목적이 무엇인가를 먼저 생각해봐야 한다는 것입니다. 이건 물론 사람마다 다를 수 있고...

머신러닝 모델에서 Data Drift가 무엇이며 어떻게 발견하는지에 대한 글입니다. Drift란 무엇인가 그리스의 철학자 헤라클레이토스는 “같은 강물에 두 번 발을 담글 수 없다”라는 말을 남겼다고 합니다. 강물이 끊임없이 흐르기 때문에 어떤 사람이 똑같은 자리에 서서 두번째로 발을 넣는다 한들 그건 처음과 같은 강물이 아니라는 뜻이죠. 마...
글또 또 한다 4기부터 시작해서 벌써 5기수째다. 4기를 시작할 때 나는 갓 대학원을 졸업하고 인턴을 끝낸, 내가 하고 싶은 일로 취업을 했다는 것에 적당히 신나있는 신입이었는데, 진짜 좀 무서울 정도로 빠르게 3년이 지났다. 그때와 지금 나라는 사람이 본질적으로 많이 바뀌었다고 생각하진 않지만 겉으로 달라진 것들은 있겠다. 우선 일적으로는 주니어라...