스포티파이는 어떻게 유저의 변하는 관심사를 모델링할까
음악 스트리밍 서비스에서 유저의 빠르게 변하는 선호와 장기적인 특성을 동시에 추천 시스템에 활용한 사례를 들여다봅니다.
문제 정의
온라인 콘텐츠의 소비 패턴은 시간에 따라 끊임없이 변화하며, 보통 사용자의 관심사는 단순한 선호도의 누적이 아니라 장기적인 취향과 순간적인 관심이 복합적으로 반영된 결과입니다. 특히 음악 스트리밍 서비스는 더더욱 그런 면이 있는데, 예를 들어 가상의 유저 A는 락 음악을 10대때부터 오랫동안 들어왔고 라이브러리 대부분 다 락이지만, 집중해서 일할 때는 가사가 없는 잔잔한 음악을 듣고, 집안일을 할 때는 신나는 K-Pop을 듣습니다. 또 최근에는 재즈 뮤지션이 나오는 다큐멘터리를 한 편 보고 재즈에 빠지게 되어, 일주일 간 재즈 명반들을 돌려 듣기도 했죠.

이 사람이 특별히 이상한 취향이라기보다는, 대부분의 음악 스트리밍 유저가 이렇게 일시적 변화와 상황적 맥락에 영향을 많이 받을 겁니다. 이런 사용자의 선호도는 느린 변화(Slow Features) 와 빠른 변화(Fast Features) 로 나누어 이해할 수 있습니다. 느린 변화는 사용자의 장기적인 취향을 반영하며, 특정 장르, 아티스트, 혹은 스타일에 대한 지속적인 선호도를 나타냅니다. 반면 빠른 변화는 순간적인 관심과 맥락 을 반영하며, 특정한 시간, 기분, 혹은 외부 환경에 의해 단기적으로 변화하는 소비 패턴을 의미하고요.
기존의 추천 시스템 대부분은 이러한 이중적인 선호도 패턴을 효과적으로 모델링하지 못했습니다. 일반적인 협업 필터링(collaborative filtering) 기반 모델은 느린 변화를 반영하는 데 초점을 맞추고 있어, 사용자의 최근 관심을 즉각적으로 반영하지 못합니다. 반면, 세션 기반 추천(session-based recommendation) 모델은 최신 행동을 중심으로 빠른 변화를 반영할 수 있지만, 사용자의 전반적인 취향을 고려하지 않아 일관성 있는 개인화 추천을 제공하는 데 한계가 있습니다.
Spotify에서 내놓은 Variational User Modeling with Slow and Fast Features는 이런 사용자의 두 가지 특성을 모두 학습하는 VAE(Variational AutoEncoder) 기반의 추천 모델(이름: FS-VAE)을 제안합니다. 나온지 꽤 되긴 했지만(2022년) 온라인 컨텐츠 추천 시스템에서는 꽤 핵심적인 요소를 다루고 있다고 생각해서 읽어보게 되었는데요, 정확히 어떤 구조의 모델인지 한번 들여다보겠습니다.
모델 구조
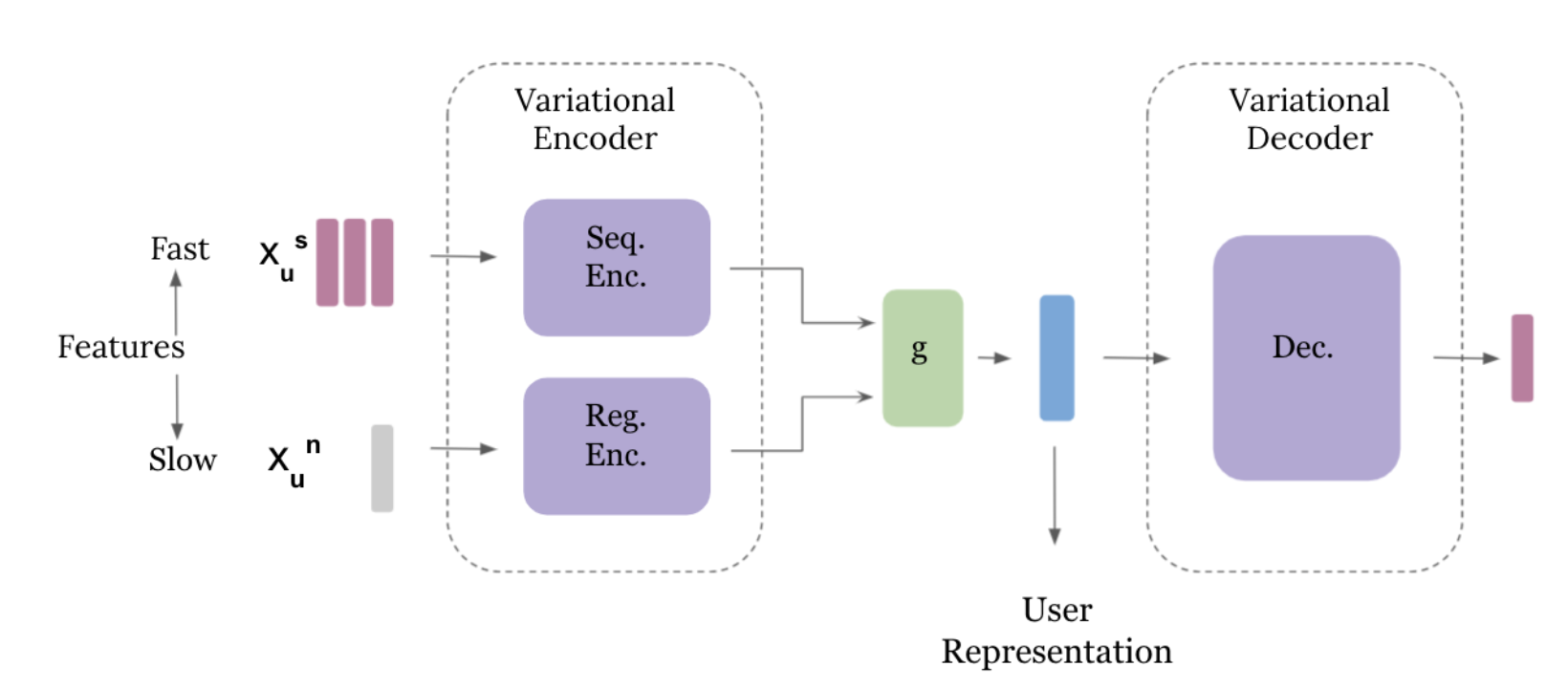
FS-VAE는 2가지의 입력 데이터를 사용합니다.
- Slow Features
- 사용자의 일반적인 음악 선호도를 반영하는 장기적인 특성 (Non-Sequential한 입력)
- 특정 시점에서 변하지 않는 누적된 청취 기록을 포함
- 예) 총 청취 횟수, 좋아요 누른 횟수, 스킵한 곡 수, 다시 들은 곡 수, 재생목록에 추가한 곡 수, 시간대별 청취 패턴 등
- Fast Features
- 사용자의 최근 행동 및 순간적인 관심을 반영하는 특성 (Sequential한 입력)
- 최근 들은 곡들의 시퀀스(그 곡들의 특징 벡터)
- 사용자의 최근 행동 및 순간적인 관심을 반영하는 특성 (Sequential한 입력)
전체 구조는 디코더와 인코더로 이루어졌고 variational inference를 통해 확률적인 잠재 공간을 모델링하는 일반적인 Variational AutoEncoder의 구조를 지니고 있습니다. 기본적인 VAE에 대한 설명은 제가 이전에 작성한 다른 글을 확인해보시면 좋습니다.
특이사항은 Slow Features와 Fast Features를 각각 두 개의 다른 인코더로 나눠서 처리하고 그 두 개의 인코더에서 얻은 latent vector를 결합(concat)해서 최종적인 유저 representation을 얻는다는 것입니다. 디코더는 MLP 층으로 인코더가 얻은 임베딩을 사용하여 사용자가 다음에 들을 곡을 예측하게 됩니다. 또 다른 특이점이 하나 더 있다면 일반적인 VAE의 손실함수는 이렇게 생겼는데요,
\[E_{q_{\Phi}} \log(p(x \vert z)) - KL(q_{\Phi}(z \vert x ) \Vert p(z))\]FS-VAE는 다음과 같이 $\beta$ 라는 하이퍼파라미터를 넣어 KL Divergence의 가중치를 조절하도록 했습니다.
\[E_{q_{\Phi}} \log(p(x \vert z)) - \beta KL(q_{\Phi}(z \vert x ) \Vert p(z))\]이게 어떤 영향이 있냐면, KLD term은 잠재 변수 z의 분포와 우리가 변분 추론으로 가정한 정규분포의 차이가 적도록 하는 regularization term인데요, 이 $\beta$ 를 기본 VAE처럼 1로 하지 않고 0.5 정도의 낮은 값으로 설정하게 되면 모델이 더 약한 제약으로 (자유롭게) 잠재 표현을 학습할 수 있게 되어 새로운 취향을 학습할 확률이 높아집니다. 즉 추천의 다양성이 높아지는 방향으로 조절하는 거죠.
평가
실험은 약 15만 명의 사용자의 28일 간의 청취 기록을 사용해서 학습과 실험을 진행했고, 유저 임베딩에 집중하기 위해서 곡에 대한 임베딩 벡터는 이미 만들어진 벡터를 사용했습니다. (같은 플레이리스트에 얼마나 등장하느냐에 따라서 임베딩이 학습되도록 했다고 하네요.)
평가 과제는 각 사용자의 임베딩 기반으로 다음에 들을 곡을 예측 (Next-item prediction) 하는 것이고, 이때 예측된 곡과 실제 사용자가 들은 곡의 임베딩 간의 거리(L2 Distance, Cosine Distance)를 평가 메트릭으로 사용했습니다. 그 결과 다음과 같이 FS-VAE가 베이스라인 대비 낮은 거리(좋은 성능)을 보였다는 내용입니다.
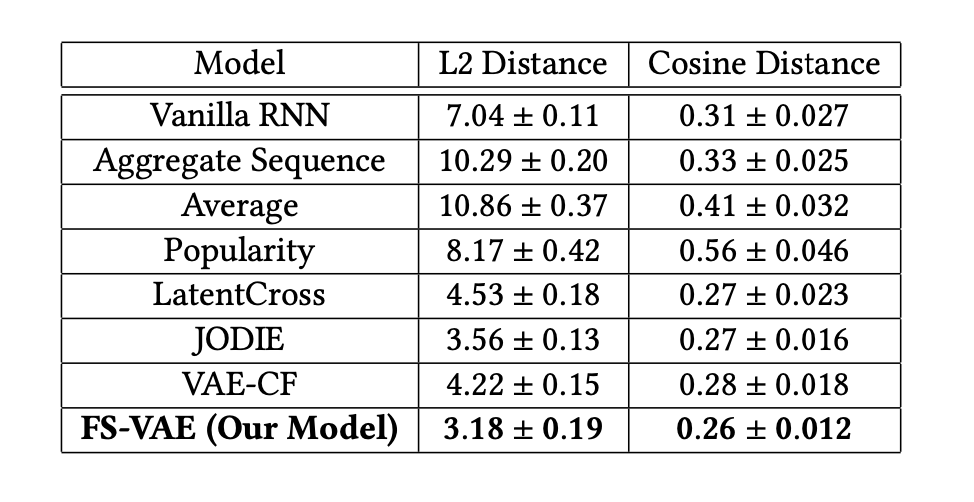
- Aggregate Sequence: 최근 청취한 곡들의 평균 벡터
- Average: 과거 청취한 곡들의 평균 벡터
- Popularity: 그냥 인기 있는 곡 추천
- LatentCross: 시퀀스 피쳐와 context 피쳐를 결합한 RNN 기반 추천 모델
- JODIE: 시퀀스 피쳐와 context 피쳐 기반 임베딩 학습 모델
- VAE-CF : VAE를 사용한 협업 필터링 모델
또 FS-VAE가 시간에 따라 유저 임베딩을 동적으로 변화시킨다는 내용의 플랏도 있는데 사실 이거는 대조군이 average라서(그냥 과거 청취곡의 평균), 그거 대비해서는 어떤 모델이든 바뀌는 게 너무 당연하지 않나 라는 생각이 들어서 패스하겠습니다.
마지막으로 모델 설정을 이것저것 소거해보면서 성능의 변화를 관찰한 내용을 보면,
- Fast Features를 뺐을 때
- Fast Features의 시퀀스를 랜덤으로 섞었을 때
- Slow Features를 뺐을 때
- 변분추론(probablistic model)을 쓰지 않았을 때 (즉, 일반적인 오토인코더를 사용했을 때)
모두 유의하게 제안된 모델보다 성능이 떨어졌고, 가장 영향이 큰 건 Fast Features를 뺐을 때였습니다. 아무래도 이 과제 자체가 당장 짧은 시간 텀 내에 다음 재생될 곡을 예측하는 것이다 보니 Fast Features의 영향도가 큰 것 같지만 어쨌든 양쪽을 다 활용했을 때 가장 성능이 좋았다가 결론이 되겠습니다. 또 기본적인 오토인코더를 썼을 때 (피쳐 변경보다는 영향도가 낮았지만 그래도 어느 정도) 성능이 낮아졌는데, 이는 확률적 샘플링을 통해 유저의 특성을 모델링하는 것이 기존 사용자 취향에 고착되지 않고 어느 정도 새롭고 유의한 추천을 하는 데 의미가 있었다는 사실을 알 수 있습니다.
전반적으로 엄청나게 복잡한 구조나 특별한 아이디어는 아니었지만, 오히려 단순히 장기적/단기적 특성을 함께 추천에 반영하는 것만으로도 좋은 결과를 낼 수 있다는 것을 확인할 수 있었던 실험이었습니다.
참고