Subset Scanning으로 이상한 부분집합 찾기
데이터 전체의 기댓값과 동떨어진 부분집합을 찾아내는 Subset Scanning 알고리즘의 간단한 접근 방식과 사용법에 대해 알아봅니다. Searching for Anomalous Subsets? All You Need is Scanning- Tanya Akumu / SciPy 2022 및 관련 자료들을 기반으로 작성하였습니다.
어떨 때 필요한가
보통 이상치 탐지(anomaly detection)라고 하면 anomaly는 특정 이상한 데이터 샘플(관측치), 포인트를 의미합니다. 하지만 종종 모델링/분석을 할 때, 전체적인 데이터의 경향성에서 벗어난 관측치 자체가 아니라 특정 피쳐에 따라 구분된 관측치들의 부분집합을 보는 게 유용할 때가 있습니다. 즉 이상한 관측치가 아니라 이상한 그룹과 그 특징을 찾아내는 것인데요. 그러면 그 자체로 분석의 인사이트가 되기도 하고, 모델의 개선 포인트를 찾을 수도 있어요.
예를 들어 우리가 다음과 같이 어떤 나라의 신생아 사망률 데이터를 가지고 있다고 칩시다.

이 나라의 신생아 사망률 평균은 1.5%입니다(전체 평균). 그리고 피쳐가 여러 개가 있습니다(산모의 나이, 출생 몸무게, 산모의 교육 수준 등). 부분집합은 피쳐에 따라서 형성됩니다. 예를 들어 30대 산모가 병원에서 출산한 경우는 전체 데이터 중 하나의 부분집합입니다. 피쳐 목록은 더 길어질 수도 있습니다. 2011년에 10년 이상 교육을 받은 30대 산모가 병원에서 산파와 함께 출산한 경우도 하나의 부분집합입니다. 앞선 집합보단 크기가 더 작겠죠.
어떤 알고리즘이 있어서 이 데이터를 집어넣으면 어떤 부분집합에서 신생아 사망률이 유독 높은지를 알려준다고 칩시다. 그 알고리즘이 바로 오늘 소개할 Subset scanning인데요, 간단하게는 이상함을 판단할 수 있는 기준(scoring function)만 알려주면 가능한 모든 부분집합들을 따져보고 그 값이 가장 높은 부분집합을 돌려줍니다. 그 결과 이 데이터에서는 전문가(의사 또는 산파)와 함께 집에서 출산한 집단이 무려 42.1%의 신생아 사망률을 보였으며(전체 평균에 비해 어마어마하게 높죠?) 전체 신생아 사망건의 거의 절반(49%)를 차지했다고 합니다.
이때 잠깐, 부분집합을 찾는다면 그냥 stratification 해서 그룹별로 비교하면 되지 않아? 라는 생각이 들 수도 있을 것입니다.
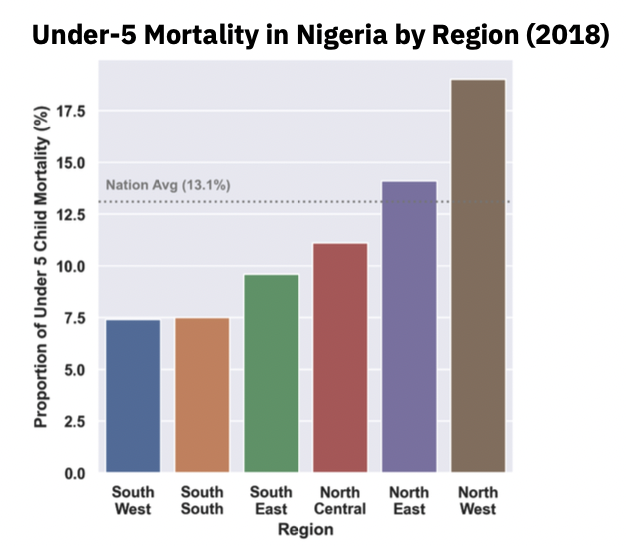
이것은 전형적인 stratification, 즉 그룹별로 나눠서 데이터를 파악하는 접근 방식을 나타내주는 그림입니다. 나이지리아의 5세 미만 사망률의 전국 평균은 13.1%이지만, 지역별로 나눠서 봤더니 North West에서 유독 높고, South West 나 South South는 전국 평균의 절반밖에 되지 않는다! 라고 지역별 경향성을 파악할 수 있죠.
이런 방식은 이해도 시각화도 편하지만 1-2개의 피쳐만 볼 수 있다는 단점이 있습니다. 앞서 언급한 대로 부분집합을 형성하는 조건은 매우 길어질 수도 있기 때문이죠. 만약 지역 하나가 아니라 지역, 부모 소득, 출생 시 몸무게에 따른 그룹을 나눠서 이상한 부분을 찾고 싶다고 말하면 일단 어… 집합이 너무 많은데? 그림을 어떻게 그리지? 라는 생각이 듭니다.
또한 부분집합을 생성하는 1-2개의 피쳐를 선정하는 것에도 한계가 있는데요, 보통 분석가가 생각하기에 이렇게 나누면 차이가 나지 않을까? 라고 하는 가설에 따라 나누게 됩니다(피쳐가 많으면 부분집합의 크기도 같이 늘어나는데 모든 걸 다 해볼 수 없으니 당연한 일입니다). 즉 분석가가 떠올리지 못한 피쳐는 그룹화의 기준이 되지 못하므로, 가설에 대한 검증만 가능할 뿐 전혀 몰랐던 사실을 ‘발견’할 수 있는 방식은 아닙니다.
Subset Scanning이란
그래서 subset scanning이 뭘 하는 건지 조금 더 자세하게 들어가 보면요.
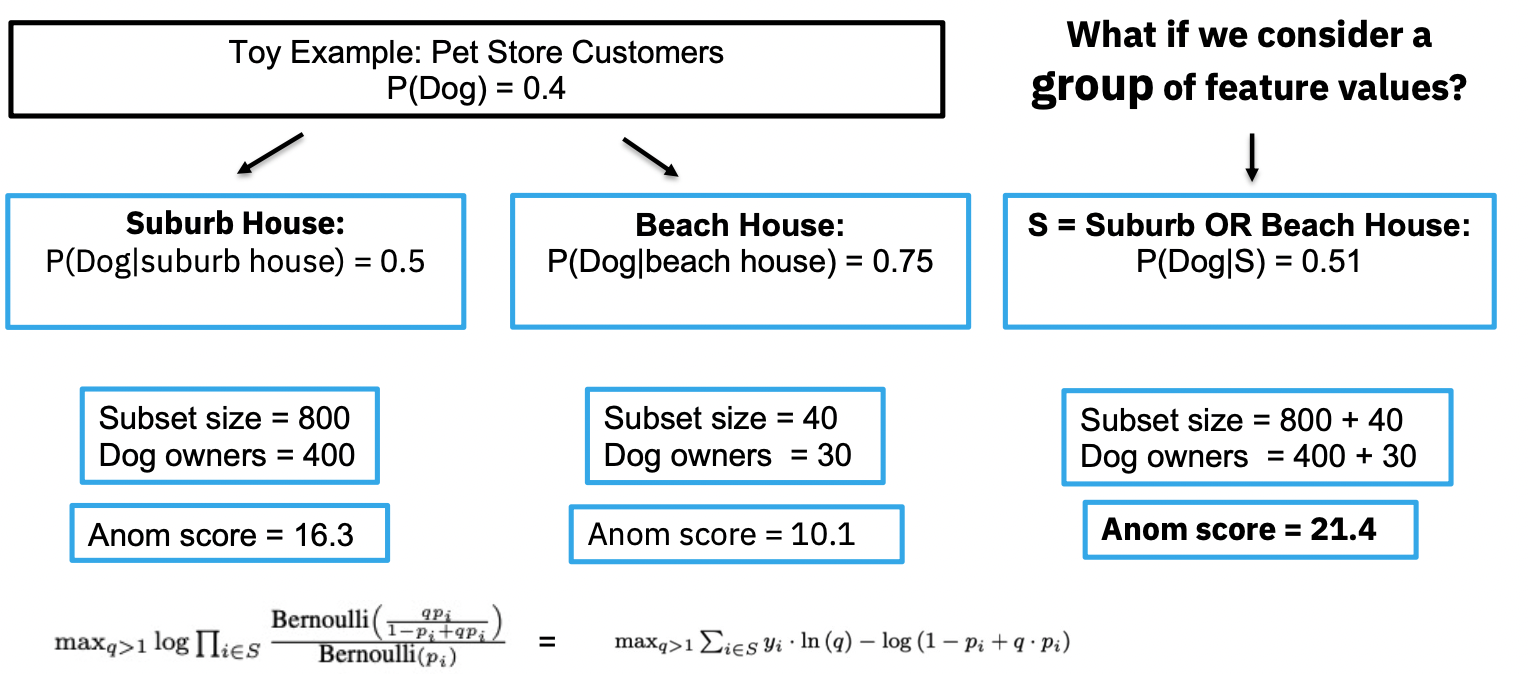
예를 들어, 반려동물 용품을 판매하는 가게가 있는데 전체 손님 중 강아지 손님의 비중을 보고 싶다고 합시다.
 출처: [Searching for Anomalous Subsets? All You Need is Scanning- Tanya Akumu | SciPy 2022 ](https://www.youtube.com/watch?v=tGAqvs9Pqwk) 의 발표자료
출처: [Searching for Anomalous Subsets? All You Need is Scanning- Tanya Akumu | SciPy 2022 ](https://www.youtube.com/watch?v=tGAqvs9Pqwk) 의 발표자료
- 강아지 손님은 전체 손님의 40%다(전체 평균).
- 교외 지역만 놓고 보면 50%고, 해변 지역만 놓고 보면 75%이다. 이때 부분집합의 크기는 굉장히 차이가 난다.
- 특정 공식에 따라서 ‘이상함’의 정도를 정할 수 있다고 보자. 여기서 이상함이란 전체 평균과 많이 떨어진다는 소리이다.
- 좌측 하단에 있는 식인데 접근만 간단히 설명하면
- 모든 부분집합에 대해 전체 odds가 모든 데이터포인트 i에 대해 $\frac{\hat{p_i}}{1-\hat{p_i}}$여야 하는데(영가설) 만약 특정 부분집합이 이상하다면, 그 부분집합에 대해서는 odds가 $q \frac{\hat{p_i}}{1-\hat{p_i}}$ 로 표현될 것($q>1$)
- 각 관측치의 likelihood가 베르누이 분포를 따르며 독립이라고 가정해서 $q$가 가장 큰 케이스를 score로 만든 것이 저 식
- 좌측 하단에 있는 식인데 접근만 간단히 설명하면
- 이 점수에 따르면 교외 지역의 강아지 손님 비중은 해변 지역의 강아지 손님 비중보다 조금 더 이상하다(16.3 > 10.1).
- 특정 공식에 따라서 ‘이상함’의 정도를 정할 수 있다고 보자. 여기서 이상함이란 전체 평균과 많이 떨어진다는 소리이다.
- 만약 이 피쳐를 합친 부분집합을 고려한다면?
교외 또는 해변 지역부분집합의 강아지 비중은 51%다.- 주어진 이상함 점수에 따르면, 이 부분집합이 훨씬 더 이상하다(21.4).
이런 식으로 부분집합마다 이상함 점수를 계산한다고 칩시다. 이 동네의 지역(해변, 교외,…) 유형이 N개라고 했을 때 우리가 search space를 뒤지는 데 드는 노력은 $O(2^n)$로 늘어납니다(크기 n인 집합의 멱집합의 크기는 $2^n$).
| 심지어 지역이 아닌 다른 피쳐가 있다면요? 각각 $X_m$개의 서로 다른 값을 지닌 M개의 피쳐가 있는 데이터셋에서는 $\mathrm{\Pi}^M_{m=1}(2^{ | X_m | }-1)$ 의 서로 다른 부분집합을 만들 수 있는데(공집합 빼고)……. 다시 올려서 9개의 피쳐가 있는 신생아 사망률 데이터를 봅시다. 조금 아찔해집니다. |
LTSS (Linear-Time Subset Scanning) 이라는 성질은 이런 계산 부담을 압도적으로 단축해줍니다. 관측할 데이터를 특정 함수에 따라 우선순위가 높은 순으로 정렬해서 가장 높은 그룹만 검증하면 가장 점수가 높은 데이터는 무조건 그들 중 하나에 속하게 되어 있다는 아주 편리한 성질인데요. 만약에 주어진 부분집합에 대해 이상함의 정도를 계산하는 scoring function F가 LTSS라는 성질을 만족하면, 지수적으로 증가하는 수많은 부분집합들이 있을 때도 우리가 실제로 평가해야 하는 부분집합의 개수는 선형적으로만 증가한다고 합니다 ($O(2^n)$이 아닌 $O(n)$).
참고로 조금 전 강아지 손님 예시에서 사용한 scoring function 이 저렇게 다소 복잡하게 생긴 것도 이 LTSS 때문입니다. 다음과 같이 생긴 기댓값 기반 통계량은 베르누이분포를 포함한 모든 지수분포족 확률분포에 대해서 LTSS를 만족하기 때문에 빠른 subset scanning이 가능하거든요.
\[F(S) = \underset {q>1} \max \log\frac{P(\text{Data}| H_1(S))}{P(\text{Data} |H_0)}\]($H_0: x_i \sim \text{Dist}(\mu_i), H_1: x_i \sim \text{Dist}(q\mu_i) )$
이 방식의 장점은 scoring function이 주어진 조건만 만족하는 한 내가 원하는 원하는 기댓값과 점수를 정의할 수 있다는 점입니다. 지금까지는 신생아 사망률도 강아지 비중도 다 전체 평균을 기댓값으로 보고 그 기댓값에서 벗어나는 부분집합을 찾았죠. 하지만 그 기댓값을 평균이 아니라 모델의 성능으로 설정하게 된다면, 우리는 모델의 성능이 유달리 떨어지는 부분집합을 찾게 됩니다. 특정 그룹 또는 특정 그룹의 집합에 대한 모델의 편향(bias) 을 찾음으로써 내 모델이 못하는 부분을 찾아서 필요한 개선점을 발견할 수도 있고, 어쩌면 요즘 흔히 언급되는 편향성 문제들로 치환될 수도 있겠네요.
이어서 Python으로 subset scanning을 해보는 튜토리얼을 다룰 건데요. 위와 같은 확장성으로 인해 이 알고리즘을 지원하는 패키지가 바로 AI의 편향성 관련된 데이터셋, 메트릭, 검증과 완화 알고리즘을 제공하는 오픈소스 툴킷인 AI Fairness 360입니다.
써보자!
- folktables 패키지가 지원하는 미국 소득 데이터를 사용해서 Subset scanning을 써봅니다.

대충 이렇게 생긴 데이터이고요, 여러가지 피쳐(연령대, 결혼여부, 성별, 인종, 직업, 학력… )와 소득을 알 수 있는데요. 5만 달러 이상의 소득을 1로, 미만을 0으로 라벨링하는 예측을 하면서 이상한 부분집합을 찾아봅시다. 이상함의 기준이 되는 기댓값을 두 가지로 나눠서 할 겁니다.
- 소득 변수의 전체 평균 → 평균에서 많이 동떨어진 부분집합 찾기
- 소득 예측 모델의 예측 정확도 → 예측력이 많이 떨어지는 부분집합 찾기
1
from aif360.detectors.mdss_detector import bias_scan
bias_scan 함수는 다음과 같은 옵션을 설정할 수 있습니다.
scoring- 이상함을 판단하는 점수 설정 -
Bernoulli,Gaussian,Poisson,BerkJones - 지금은 1 또는 0 binary이므로
Bernoulli사용
- 이상함을 판단하는 점수 설정 -
overpredicted- 기댓값에서 동떨어진 방향을 설정
- True일 경우 모델이 더 높게 예측한 부분집합(기댓값이 실제 값보다 높은)을, False일 경우 그 반대인 부분집합(기댓값이 실제 값보다 낮음)을 돌려줌
penalty- 부분집합의 복잡도(즉 부분집합을 생성하는 조건의 개수)를 컨트롤하는 일종의 regularization 상수라고 보면 됨
- 이 값이 높아질수록 부분집합의 복잡도를 제한할 수 있고, 단 트레이드오프로 더 이상한(그러나 복잡도가 높은) 부분집합을 포기하긴 해야 됨
- 만약 리턴되는 부분집합이 한 76개의 조건으로 이뤄져 있다면 해석이나 활용이 어려울 것이기 때문에 필요한 옵션
- 부분집합의 복잡도(즉 부분집합을 생성하는 조건의 개수)를 컨트롤하는 일종의 regularization 상수라고 보면 됨
우선 overpredicted 값을 False로 줘서 이상하게 소득이 높은 부분집합을 찾아봅시다.
1
2
3
4
observed = dff['observed']
data = dff.drop(['observed'], axis=1)
privileged_subset = bias_scan(data=data, observations=observed, scoring='Bernoulli', overpredicted=False,penalty=5, num_iters=1)
print(privileged_subset)
1
({'AGEP': ['30 - 50', '50 - 70', '>70'], 'SCHL': ['Bachelor’s degree', 'Doctorate degree', 'Master’s degree', 'Professional degree beyond a bachelor’s degree'], 'WKHP': ['30 - 40', '40 - 50', '50 - 60', '60 - 70', '70 - 80', '80 - 90', '90 - 99'], 'RELP': ['Husband/wife', 'Reference person', 'Unmarried partner']}, 6950.4348)
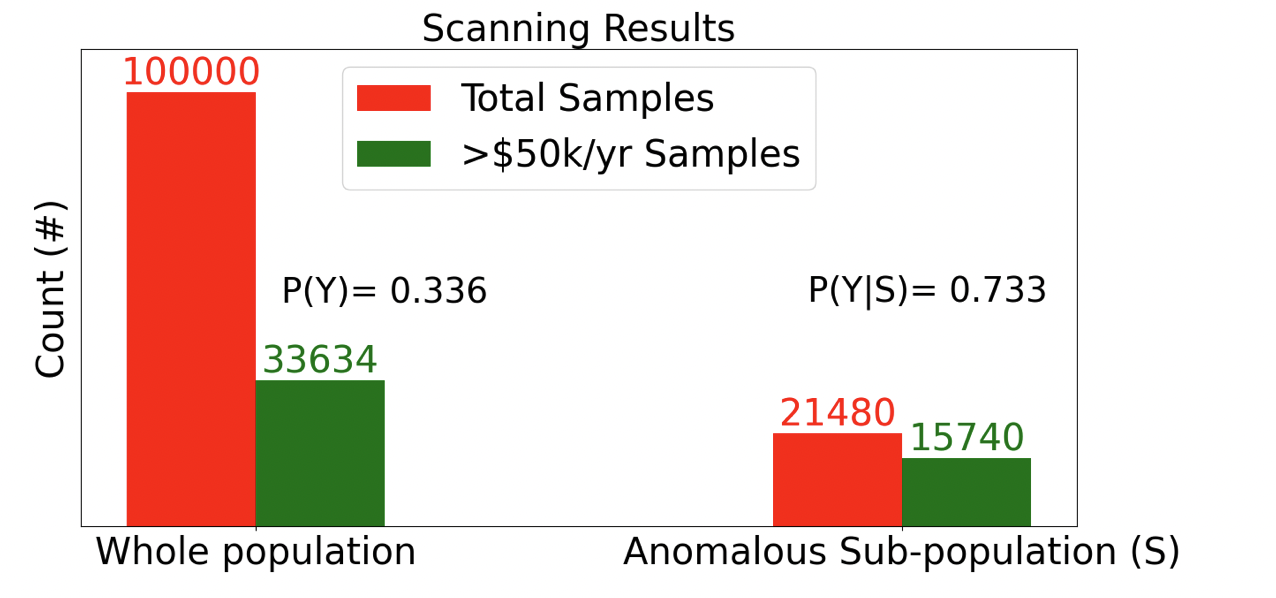
관측치가 1인, 즉 소득이 5만 달러 이상인 사람의 비율은 전체에서 34% 정도이지만, 이 부분집합에서는 73%라는 걸 알 수 있습니다.
반대로 이상하게 소득이 낮은 부분집합도 다음과 같이 확인할 수 있습니다.
1
2
3
from aif360.detectors.mdss_detector import bias_scan
unprivileged_subset = bias_scan(data=data, observations=observed, scoring='Bernoulli', overpredicted=True,penalty=5, num_iters=1)
print(unprivileged_subset)
1
({'AGEP': ['20 - 30', '30 - 50', '50 - 70', 'teen'], 'WKHP': ['0 - 10', '10 - 20', '20 - 30'], 'SCHL': ['1 or more years of college credit but no degree', '12th Grade - no diploma', 'Associate’s degree', 'Bachelor’s degree', 'GED or alternative credential', 'Grade 10', 'Grade 11', 'Grade 6', 'Grade 7', 'Grade 8', 'Grade 9', 'No schooling completed', 'Regular high school diploma', 'Some college but less than 1 year']}, 4862.2218)
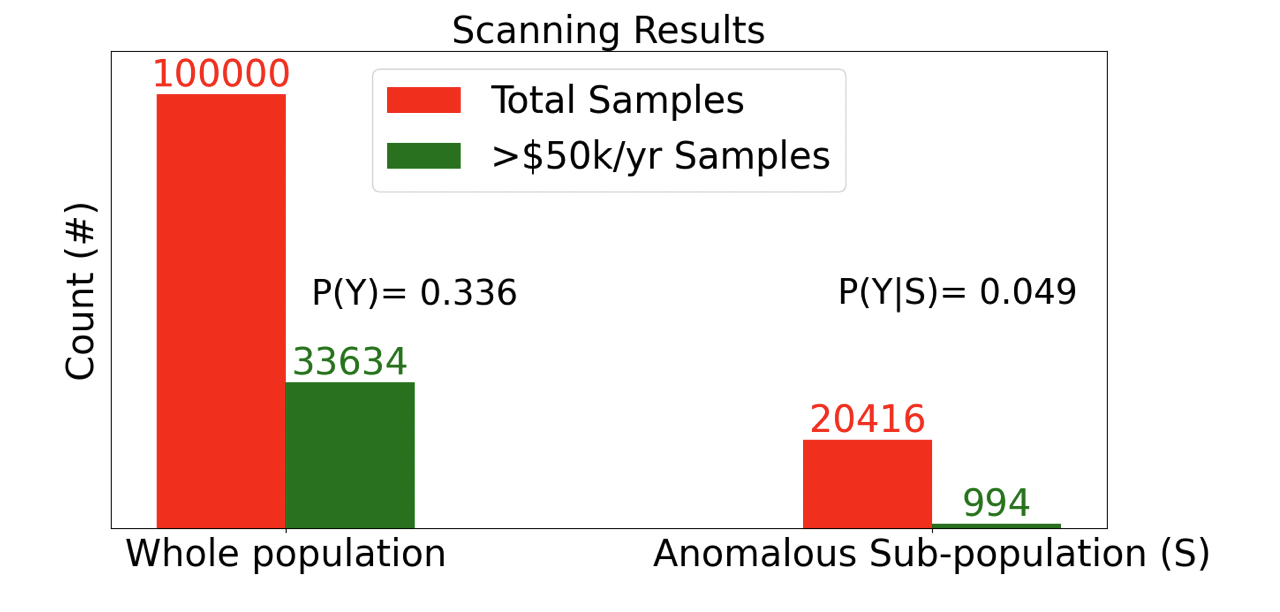
이 부분집합에서 5만 달러 이상을 버는 사람의 비율은 5%가 되지 않습니다.
이번엔 모델이 편향(bias)를 보이는 부분집합을 스캔해봅시다. 이번에는 똑같은 데이터를 사용하되, 2014년 데이터로 훈련시킨 모델을 사용해서 2018년의 소득을 예측할 겁니다. 이때 어떤 부분집합에서 4년간 시간에 따른 차이가 발생해서 모델이 예측을 잘 못하게 되었을까요?
- 간단한 전처리
```python from sklearn.ensemble import GradientBoostingClassifier as GBC from sklearn.ensemble import ExtraTreesClassifier from sklearn.metrics import f1_score, roc_auc_score
def transform_features(X): for feature in X.columns: X[feature] = X[feature].astype(‘category’).cat.codes return X
y_2014 = observed features_2014 = data X_2014 = features_2014.copy() X_2014 = transform_features(X_2014)
y_2018 = dff_2018[‘observed’] y_2018 = y_2018.reset_index(drop=True) features_2018 = dff_2018.drop([‘observed’], axis = 1) features_2018 = features_2018.reset_index(drop=True) X_2018 = features_2018.copy() X_2018 = transform_features(X_2018)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
```python
# 2014 데이터로 모델 훈련
model_2014 = ExtraTreesClassifier()
model_2014.fit(X_2014, y_2014)
preds_2014 = pd.Series(model_2014.predict(X_2014))
# 2018 데이터 예측
preds_2018 = pd.Series(model_2014.predict(X_2018))
# 모델 평가
print('Global Results (2014):')
report(y_2014,preds_2014)
print()
print("Global results (2018): " )
report(y_2018, preds_2018)
1
2
3
4
5
6
7
Global Results (2014):
F1: 0.9800843627598674
AUC-ROC: 0.981938296728055
Global results (2018):
F1: 0.6132120562547977
AUC-ROC: 0.6986709491774388
전체 모델 평가 결과는 위와 같습니다. 2014년 데이터로 훈련 시 2018년이 되면 전체 성능이 상당히 감소한 것을 확인할 수 있습니다.
이제 2018년 실제 데이터와 2014년 모델을 통한 예측값을 비교해서 어떤 부분집합이 가장 이상한지를 스캔해봅니다.
1
2
3
4
subset, _ = bias_scan(data=features_2018, observations=y_2018,
expectations=preds_2018, scoring='Bernoulli',
overpredicted=False, penalty=10, num_iters=1)
print('Anomalous Subgroup:\n', subset)
1
2
Anomalous Subgroup:
{'OCCP': [' First-line supervisors of security workers', 'Accountants and auditors', 'Actors', 'Actuaries', 'Administrative services managers', 'Advertising and promotions managers', 'Advertising sales agents', 'Aerospace engineers', 'Agents and business managers of artists, performers, and athletes', 'Agricultural and food science technicians', 'Agricultural inspectors', 'Air traffic controllers and airfield operations specialists', 'Aircraft mechanics and service technicians', 'Aircraft pilots and flight engineers', 'Animal caretakers', 'Animal control workers', 'Architects, except landscape and naval', 'Architectural and civil drafters', 'Architectural and engineering managers', 'Artists and related workers', 'Athletes and sports competitors', 'Audiologists', 'Automotive body and related repairers', 'Automotive service technicians and mechanics', 'Baggage porters, bellhops, and concierges', 'Bailiffs', 'Bakers', 'Barbers', 'Bartenders', 'Bill and account collectors', 'Billing and posting clerks ', 'Bioengineers and biomedical engineers', 'Boilermakers', 'Bookkeeping, accounting, and auditing clerks', 'Brickmasons, blockmasons, and stonemasons', 'Broadcast, sound, and lighting technicians', 'Budget analysts', 'Bus and truck mechanics and diesel engine specialists', 'Bus drivers, school', 'Bus drivers, transit and intercity', 'Business operations specialists, all other', 'Cabinetmakers and bench carpenters', 'Cardiovascular technologists and technicians', 'Cargo and freight agents', 'Carpenters', 'Carpet, floor, and tile installers and finishers', 'Cement masons, concrete finishers, and terrazzo workers', 'Chemical engineers', 'Chemical technicians', 'Chemists and materials scientists', 'Chief executives', 'Chiropractors', 'Civil engineers', 'Claims adjusters, appraisers, examiners, and investigators', 'Clinical and counseling psychologists', 'Clinical laboratory technologists and technicians', 'Commercial and industrial designers', 'Compensation and benefits managers', 'Compensation, benefits, and job analysis specialists', 'Compliance officers', 'Computer and information research scientists', 'Computer and information systems managers', 'Computer hardware engineers', 'Computer network architects', 'Computer numerically controlled tool operators and programmers', 'Computer occupations, all other', 'Computer programmers', 'Computer support specialists', 'Computer systems analysts', 'Computer, automated teller, and office machine repairers', 'Conservation scientists and foresters', 'Construction and building inspectors', 'Construction equipment operators', 'Construction laborers', 'Construction managers', 'Control and valve installers and repairers', 'Conveyor, dredge, and hoist and winch operators', 'Correctional officers and jailers', 'Cost estimators', 'Counselors, all other', 'Counter and rental clerks', 'Couriers and messengers', 'Court reporters and simultaneous captioners', 'Court, municipal, and license clerks', 'Crane and tower operators', 'Credit analysts', 'Credit counselors and loan officers', 'Customer service representatives', 'Dancers and choreographers', 'Database administrators and architects', 'Dental assistants', 'Dental hygienists', 'Dentists', 'Derrick, rotary drill, and service unit operators, oil and gas', 'Detectives and criminal investigators', 'Diagnostic medical sonographers', 'Dietetic technicians and ophthalmic medical technicians', 'Dietitians and nutritionists', 'Dispatchers, except police, fire, and ambulance', 'Door-to-door sales workers, news and street vendors, and related workers', 'Driver/sales workers and truck drivers', 'Economists', 'Editors', 'Education and childcare administrators ', 'Educational, guidance, and career counselors and advisors', 'Electrical and electronic engineering technologists and technicians', 'Electrical and electronics engineers', 'Electrical and electronics repairers, industrial and utility', 'Electrical power-line installers and repairers', 'Electricians', 'Elementary and middle school teachers', 'Elevator and escalator installers and repairers', 'Eligibility interviewers, government programs', 'Embalmers, crematory operators and funeral attendants', 'Emergency management directors', 'Engine and other machine assemblers', 'Entertainers and performers, sports and related workers, all other', 'Entertainment and recreation managers', 'Environmental engineers', 'Environmental science and geoscience technicians, and nuclear technicians', 'Environmental scientists and specialists, including health', 'Executive secretaries and executive administrative assistants', 'Facilities managers', 'Farmers, ranchers, and other agricultural managers', 'Fashion designers', 'File clerks', 'Financial and investment analysts', 'Financial clerks, all other', 'Financial managers', 'Firefighters', 'First-line enlisted military supervisors', 'First-line supervisors of construction trades and extraction workers', 'First-line supervisors of correctional officers', 'First-line supervisors of farming, fishing, and forestry workers', 'First-line supervisors of firefighting and prevention workers', 'First-line supervisors of housekeeping and janitorial workers', 'First-line supervisors of landscaping, lawn service, and groundskeeping workers', 'First-line supervisors of mechanics, installers, and repairers', 'First-line supervisors of non-retail sales workers', 'First-line supervisors of office and administrative support workers', 'First-line supervisors of police and detectives', 'First-line supervisors of production and operating workers', 'First-line supervisors of retail sales workers', 'Fishing and hunting workers', 'Flight attendants', 'Floral designers', 'Food service managers', 'Forest and conservation workers', 'Fundraisers', 'Gambling services workers', 'General and operations managers', 'Glaziers', 'Graphic designers', 'Grinding, lapping, polishing, and buffing machine tool setters, operators, and tenders, metal and plastic', 'Hairdressers, hairstylists, and cosmetologists', 'Heating, air conditioning, and refrigeration mechanics and installers', 'Heavy vehicle and mobile equipment service technicians and mechanics', 'Home appliance repairers', 'Human resources assistants, except payroll and timekeeping', 'Human resources managers', 'Human resources workers', 'Industrial and refractory machinery mechanics', 'Industrial engineers, including health and safety', 'Industrial production managers', 'Industrial truck and tractor operators', 'Information and record clerks, all other', 'Information security analysts', 'Inspectors, testers, sorters, samplers, and weighers', 'Insulation workers', 'Insurance claims and policy processing clerks', 'Insurance sales agents', 'Insurance underwriters', 'Interior designers', 'Interpreters and translators', 'Judicial law clerks', 'Laborers and freight, stock, and material movers, hand', 'Landscape architects', 'Lawyers', 'Legal secretaries and administrative assistants', 'Legal support workers, all other', 'Licensed practical and licensed vocational nurses', 'Loan interviewers and clerks', 'Locksmiths and safe repairers', 'Locomotive engineers and operators', 'Lodging managers', 'Logisticians', 'Machinists', 'Magnetic resonance imaging technologists', 'Maintenance and repair workers, general', 'Maintenance workers, machinery', 'Management analysts', 'Marine engineers and naval architects', 'Market research analysts and marketing specialists', 'Marketing managers', 'Massage therapists', 'Mechanical engineers', 'Media and communication workers, all other', 'Medical and health services managers', 'Medical records specialists', 'Medical transcriptionists', 'Meeting, convention, and event planners', 'Meter readers, utilities', 'Military officer special and tactical operations leaders', 'Military, rank not specified', 'Millwrights', 'Miscellaneous health technologists and technicians', 'Miscellaneous plant and system operators', 'Models, demonstrators, and product promoters', 'Network and computer systems administrators', 'New accounts clerks', 'Nuclear medicine technologists and medical dosimetrists', 'Nurse practitioners', 'Occupational health and safety specialists and technicians', 'Occupational therapists', 'Occupational therapy assistants and aides', 'Office clerks, general', 'Office machine operators, except computer', 'Operations research analysts', 'Opticians, dispensing', 'Optometrists', 'Orderlies and psychiatric aides', 'Other assemblers and fabricators', 'Other designers', 'Other drafters', 'Other educational instruction and library workers', 'Other engineering technologists and technicians, except drafters', 'Other engineers', 'Other extraction workers', 'Other healthcare practitioners and technical occupations', 'Other healthcare support workers', 'Other installation, maintenance, and repair workers', 'Other life scientists', 'Other life, physical, and social science technicians', 'Other managers', 'Other material moving workers', 'Other mathematical science occupations', 'Other metal workers and plastic workers', 'Other personal appearance workers', 'Other physicians', 'Other production workers', 'Other psychologists', 'Other teachers and instructors', 'Other textile, apparel, and furnishings workers', 'Painters and paperhangers', 'Painting workers', 'Paralegals and legal assistants', 'Paramedics', 'Passenger attendants', 'Payroll and timekeeping clerks', 'Personal care aides', 'Personal care and service workers, all other', 'Personal financial advisors', 'Pest control workers', 'Petroleum, mining and geological engineers, including mining safety engineers', 'Pharmacists', 'Pharmacy aides', 'Pharmacy technicians', 'Photographers', 'Physical scientists, all other', 'Physical therapist assistants and aides', 'Physical therapists', 'Physician assistants', 'Plumbers, pipefitters, and steamfitters', 'Podiatrists', 'Police officers', 'Postal service clerks', 'Postal service mail carriers', 'Postal service mail sorters, processors, and processing machine operators', 'Postsecondary teachers', 'Power plant operators, distributors, and dispatchers', 'Precision instrument and equipment repairers', 'Pressers, textile, garment, and related materials', 'Private detectives and investigators', 'Probation officers and correctional treatment specialists', 'Procurement clerks', 'Producers and directors', 'Production, planning, and expediting clerks', 'Project management specialists', 'Proofreaders and copy markers', 'Property appraisers and assessors', 'Property, real estate, and community association managers', 'Public relations and fundraising managers', 'Public relations specialists', 'Public safety telecommunicators', 'Pumping station operators', 'Purchasing agents, except wholesale, retail, and farm products', 'Purchasing managers', 'Radiation therapists', 'Radio and telecommunications equipment installers and repairers', 'Radiologic technologists and technicians', 'Railroad conductors and yardmasters', 'Real estate brokers and sales agents', 'Receptionists and information clerks', 'Recreation workers', 'Refuse and recyclable material collectors', 'Registered nurses', 'Reservation and transportation ticket agents and travel clerks', 'Respiratory therapists', 'Retail salespersons', 'Roofers', 'Sales and related workers, all other', 'Sales engineers', 'Sales managers', 'Sales representatives of services, except advertising, insurance, financial services, and travel', 'Sales representatives, wholesale and manufacturing', 'School psychologists', 'Secondary school teachers', 'Secretaries and administrative assistants, except legal, medical, and executive', 'Securities, commodities, and financial services sales agents', 'Security and fire alarm systems installers', 'Security guards and gambling surveillance officers', 'Sheet metal workers', 'Ship and boat captains and operators', 'Shuttle drivers and chauffeurs', 'Skincare specialists', 'Social and community service managers', 'Social and human service assistants', 'Social workers, all other', 'Software developers', 'Software quality assurance analysts and testers', 'Special education teachers', 'Speech-language pathologists', 'Stationary engineers and boiler operators', 'Statistical assistants', 'Structural iron and steel workers', 'Structural metal fabricators and fitters', 'Supervisors of personal care and service workers', 'Supervisors of transportation and material moving workers', 'Surface mining machine operators and earth drillers', 'Surgical technologists', 'Surveying and mapping technicians', 'Surveyors, cartographers, and photogrammetrists', 'Tax preparers', 'Technical writers', 'Telecommunications line installers and repairers', 'Tellers', 'Therapists, all other', 'Title examiners, abstractors, and searchers', 'Tool and die makers', 'Training and development managers', 'Training and development specialists', 'Transportation inspectors', 'Transportation security screeners', 'Transportation, storage, and distribution managers', 'Travel agents', 'Tutors', 'Umpires, referees, and other sports officials', 'Underground mining machine operators', 'Urban and regional planners', 'Veterinarians', 'Waiters and waitresses', 'Water and wastewater treatment plant and system operators', 'Web and digital interface designers', 'Web developers', 'Welding, soldering, and brazing workers', 'Wholesale and retail buyers, except farm products', 'Word processors and typists', 'Writers and authors']}
이 그룹이 얼마나 이상한지는 다음과 같이 출력해볼 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def subset_diff(subset,data,y,preds):
y = y.reset_index(drop=True)
to_choose = data[subset.keys()].isin(subset).all(axis=1)
to_choose = to_choose.reset_index(drop=True)
_actual = y.loc[to_choose].copy()
_preds = preds.loc[to_choose].copy()
return _actuals, _preds
actual_2014, preds_2014 = subset_diff(subset,dff_2014,y_2014, preds_2014)
actual_2018, preds_2018 = subset_diff(subset,dff_2018,y_2018, preds_2018)
print('2014 mean outcome: 'np.round(actual_2014.mean(),2))
print('2014 predicted outcome: 'np.round(preds_2014.mean(),2))
print()
print('2018 mean outcome: 'np.round(actual_2018.mean(),2))
print('2018 predicted outcome: 'np.round(preds_2018.mean(),2))
1
2
3
4
5
2014 mean outcome: 0.41
2014 predicted outcome: 0.4
2018 mean outcome: 0.47
2018 predicted outcome: 0.34
이 부분집합에 대해서는 2014년에는 모델 성능이 나쁘지 않았으나, 2018년 데이터 기준으로는 5만 달러 이상 버는 평균 비중을 모델이 실제보다 상당히 낮게 예측하는 편향을 보이고 있다는 사실을 알 수 있습니다.
참고
- 발표영상
- 튜토리얼 코드 및 발표자료
- 논문
- Fast subset scan for spatial pattern detection
- Identifying Significant Predictive Bias in Classifiers (bias detection을 COMPAS 데이터셋에 적용)