인과 추론 3. 개입
이 글은 Causal Inference in Statistics: A Primer의 4장 내용을 기반으로 작성하였습니다. 읽기 전에 인과 추론에서의 그래프 모델 소개를 읽고 오시면 쉽습니다.
많은 통계적 연구의 최종적 목적은 가능한 행동의 효과를 예측하는 것입니다. 예를 들면,
- 산불 발생에 영향을 미치는 데이터를 모으고 싶다 → 어떤 조치를 취하면 산불을 예방할까? 를 알고 싶은 것
- 폭력적인 유튜브 비디오와 아이들에게 미치는 영향을 조사한다 → 유튜브를 못 보게 하면 애들의 공격적 성향을 줄일 수 있을까? 를 알고 싶은 것
물론 간단한 방법은 랜덤하게 통제된 실험을 하는 것입니다. 다른 모든 변수를 고정해놓고 한 변수만 바뀌었을 때 어떻게 되는지 보는 것이죠. 물론 위 두 예시 포함 대부분의 케이스에서 실험은 현실적으로 불가능합니다(산불을 일으키는 변수를 어떻게 마음대로 바꾸겠어요? 인간, 특히 아동을 대상으로 한 실험은 허가를 받기까지 윤리적 허들이 꽤 높습니다). 그래서 우리는 이 “무언가를 하면“의 효과를 관찰 데이터를 가지고 어떻게든 알아내고자 합니다. 이 “하면”이 바로 오늘 다룰 주제, 개입(intervention) 입니다.
아래 좌측 그림과 같은 인과 그래프가 있습니다. 이전 글에서 잠깐 언급했던, 여름에 아이스크림 판매량과 익사자 수가 동시에 올라가는 현상입니다. 또 이 글에 등장하는 전형적인 충돌(collider) 모양 그래프 예시이기도 하죠.
- $X$: 아이스크림 판매량
- $Y$: 익사자 수
- $Z$: 온도
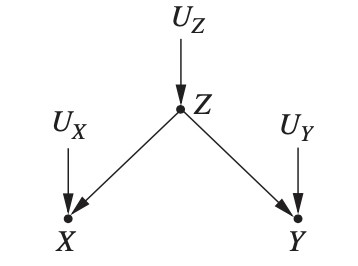
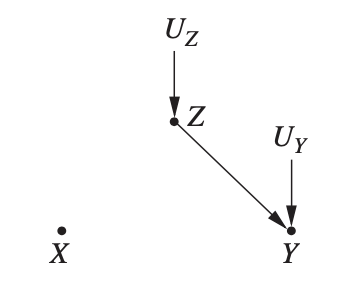
이제 개입을 해 봅시다. 우리가 아이스크림 판매에 대해 개입한다는 것은, 예컨대 갑자기 모든 아이스크림 가게를 억지로 닫아버려서, 아이스크림 판매를 0으로 만들어버린다는 것입니다. 이렇게 하면 해당 변수가 다른 변수(온도)에 의해 변화하는 자연적 경향을 아예 없애서 그래프가 축소됩니다. 그러면 그래프가 우측 그림처럼 바뀝니다. 이제 아이스크림 판매량은 날이 덥든 덜 덥든 상관없이 0입니다. 이 새로운 그래프에서 나타나는 상관을 살펴보면, 익사자 수($Y$)와 아이스크림 판매량($X$)은 완전히 독립인 것으로 나올 겁니다. 반대로 온 도시 사람들에게 하루에 꼭 아이스크림을 3개씩 사먹어! 라고 $X$를 높은 값으로 고정해도 마찬가지로 $X$ → $Y$ 에게 미치는 영향은 없어질 것이고요.
여기까지 읽으면 아니 그걸 어떻게 하는데? 라는 생각이 들 수 있습니다. 물론 현실 세계에서는 갑자기 가게를 다 닫을 수도 없고, 아이스크림 강매 규정을 만들 수도 없지만, 그래프를 잘 조작하면 우리 모델 안에서는 가능합니다.
이렇게 특정 값을 가지도록 한 변수를 $X = x$로 고정하는 경우를 $do(X=x)$로 표기하겠습니다.
이때 잠깐, 어떤 변수에 개입한다는 것은 조건부 확률을 취하는 것과는 다릅니다. 여기서 개입은 어떤 변수의 값을 하나로 고정해버리는 것입니다. 모든 경우에서 $X$가 $x$라는 값만 가지도록 바꾸는 것이죠. 반면 조건부는 어떤 조정도 하지 않은 자연스러운 확률 분포 하에서 $X$가 $x$ 값을 가지는 경우만 보겠다는 것입니다. 이때 바뀌는 것은 실제 시스템이 아니라 그냥 우리의 시야입니다.
- $P(Y=y \vert do(X =x ))$ : 전체 모집단에서 $X$ 값을 $x$로 바꿔버릴 때 $Y$가 $y$일 확률.
- $P(Y=y \vert X =x )$ : 전체 모집단 중 $X$가 $x$ 값을 가지는 부분집합에서 $Y$가 $y$ 일 조건부 확률.
우리는 이런 개입의 개념을 이용해 그래프에 일종의 수술✂️ 을 해봄으로써 상관관계로부터 인과관계를 구분해 풀어낼 수 있게 될 것입니다.
개입의 공식, The Adjustment Formula
사실 아이스크림 예시는 누가 봐도 두 변수가 아무 관계가 없죠. 조금 더 현실적인 예시, 그러니까 X와 Y가 인과 관계가 있는지 실제로 확인이 필요한 예시를 들어 봅시다.
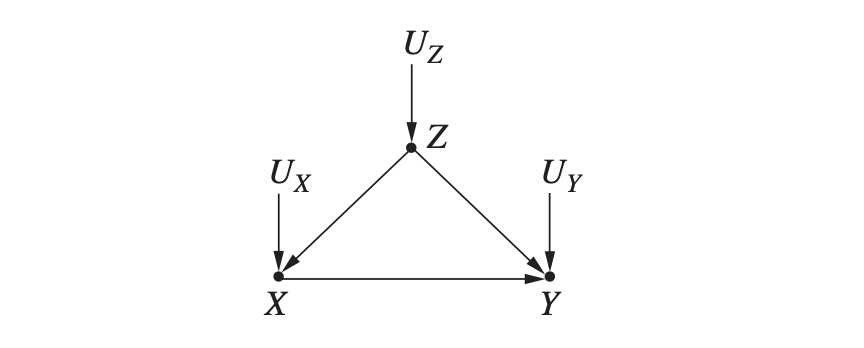
- $X$ : 신약 복용
- $Y$ : 회복
- $Z$ : 성별
이번 그래프는 아래와 같습니다. 성별이 약 복용 여부와 회복 여부에 모두 영향을 주는 가운데, 신약 복용이 병세 회복에 효과가 있는지가 궁금합니다.
가상의 개입 혹은 실험은 이렇습니다. 전체 모집단에 균등하게 약을 투여하는 경우와 아무도 약을 복용하지 않도록 하는 경우의 회복율을 비교하는 것이죠. 이건 $do(X=1)$과 $do(X=0)$으로 표현되고, 우리가 알아내야 하는 것은 $P(Y=1 \vert do(X=1)) - P (Y=1 \vert do(X=0))$ 입니다. 이것을 인과 효과 차이 혹은 평균 인과 효과 (ACE; Average Causal Effect) 라고 합니다. 사실 항상 모든 변수가 1 또는 0 두가지 값만 취하는 것이 아니기 때문에 일반적인 $P(Y=y \vert do (X=x))$ 를 알아내면 좋겠습니다.
다음과 같이 조작된(manipulated) 모델을 만들어서, 이 모델에서 조건부 확률 $P_m(Y=y \vert X =x )$를 구해 보겠습니다. 아까랑 비슷하죠? 성별(Z)의 X로 가는 영향이 싹둑 잘려 있습니다. ✂️
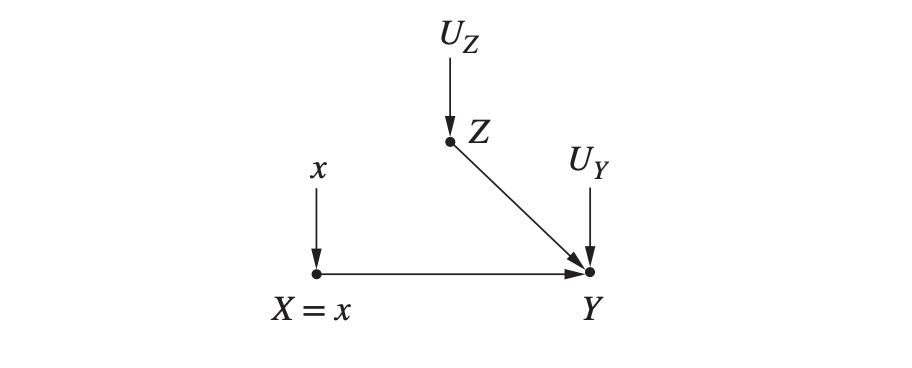
우리의 새로운 확률 분포 $P_m$은 원래 모델(조작 전)의 $P$와 두가지 성질을 공유합니다.
- $P_m(Z=z) = P (Z=z)$ : 성별 변수의 주변 확률 분포 $P(Z=z)$는 개입에 의해 변하지 않는다. 즉 $X$로 향하는 화살표를 없앤다고 해서 남녀 분포 자체가 바뀌는 것이 아니다.
- $P_m (Y=y \vert Z=z, X=x) = P(Y=y \vert Z=z, X=x)$ : $X$ 값과 $Z$ 값에 따른 $Y$의 조건부 확률 분포도 그대로다. $Y$로 향하는 화살표는 모두 그대로 두었기 때문.
그리고 조작된 모델로 바꿨을 때, 중요한 변화는 이렇습니다.
- $Z$와 $X$는 $d$-분리 상태가 된다. 식으로 쓰면, $P_m(Z=z \vert X=x) = P_m(Z=z) = P(Z=z)$. 두번째 등호는 위 2개 공유 성질 중 첫번째 때문.
위 세 가지를 이용하면 우리는 다음과 같이 일반적인 개입의 공식을 구할 수 있습니다.
\[\begin{matrix} P(Y=y\vert do(X=x))&=& P_m(Y=y \vert X=x) \qquad \text{by definition} \\ &=& \sum_z P_m(Y=y \vert X=x, Z=z)P_m(Z=z \vert X=x) \\ &=& \sum_z P_m(Y=y \vert X=x, Z=z)P_m(Z=z) \\ &=& \sum_z P(Y=y \vert X=x, Z =z )P(Z=z) \end{matrix}\]by definition을 제외하고 2~4행은 순서대로 베이지안 정리, $Z$와 $X$가 $d$-분리 상태, 원 모델과 조작된 모델 간의 2개의 공유 성질 때문입니다. 위 세 가지와 차례대로 비교하면 거의 그대로 갖다 쓴 게 보일 거예요.
위 과정은 우리가 알고 싶은 조작된 모델에 대한 정보를 구할 수 없기 때문에 (실질적으로 x 값을 바꿔버리는 실험을 할 수 없기 때문에) 이미 가지고 있는 데이터에서 직접적으로 구할 수 있는 정보를 조작된 모델에 대한 확률로 변환하는 과정입니다. 모든 $z$에 대해 평균적으로 $Y$와 $X$의 관계를 계산하는 것이 곧 $do(X=x)$의 효과를 구하는 것이고, 이것을 Z에 대해 수정한다(adjust) 고 합니다.
실제로 해볼까요? 주어진 데이터는 다음과 같습니다.
남자약을 복용한 사람의 93%가 회복했고 (81/87), 복용하지 않은 사람의 87%가 회복했다 (234/270).여자약을 복용한 사람의 73%가 회복했고 (192/263), 복용하지 않은 사람의 69%가 회복했다 (55/80).전체약을 복용한 사람의 78%가 회복했고 (273/350), 복용하지 않은 사람의 83%가 회복했다 (289/350).
전체를 보면 분명 복용하지 않은 사람의 회복률이 더 높은데, 남자만 혹은 여자만 놓고 보면 약을 복용한 사람의 회복률이 더 높습니다. 유명한 심슨의 역설입니다.
이런 케이스는 데이터 자체만을 보는 게 아니라 데이터가 만들어진 인과 과정을 봐야 한다는 것을 알려 줍니다. 예를 들어 여성 호르몬이 이 병의 예후에 안 좋은 영향을 끼치고, 약을 먹든 먹지 않든 여성이 남성보다 회복하기가 어렵다면? 여성이 남성보다 많이 약을 복용한다면? 그래서 약이 좋지 않은 영향을 끼치는 것처럼 보이는 건, 사실 약을 복용한 사람을 골랐을 때 그 사람은 여성일 가능성이 높고 예후가 안 좋을 가능성도 높다면? 즉 여성인 것이 약 복용과 회복 못하는 것 둘 다의 원인인 것입니다.
수정 공식을 그대로 쓰고 저 숫자들을 넣어보겠습니다. 모든 변수가 binary기 때문에 행이 그렇게 길어지지 않겠죠.
- 공식: $P(Y=1 \vert do(X=1)) = P(Y=1 \vert X=1, Z=1)P(Z=1) + P(Y=1 \vert X=1, Z=0)P(Z=0)$
- 숫자 넣기
- $P(Y=1 \vert do(X=1)) = \frac{0.93(87+270)}{700} + \frac{0.73(263+80)}{700} = 0.832$
- $P(Y=1 \vert do(X=0)) = \frac{0.87(87+270)}{700} + \frac{0.69(263+80)}{700} = 0.782$
- 약물 복용의 효과 ACE 계산하기
- $ACE = P(Y=1 \vert do(X=1)) - P(Y=1 \vert(X=0)) = 0.832-0.782 = 0.05$
양의 ACE로, 약 복용이 회복에 효과가 있음을 보여줍니다. 단순히 전체 회복률 78%와 83%를 비교했을 때(-5%)와는 반대의 결론이죠. 즉 여기서 약 복용($X$)이 회복($Y$)에 미치는 영향에 개입한다는 것은 두 변수에 모두 영향을 미치는 변수인 성별($Z$)에 대해 수정하는 것, 즉 성별 집단을 구분하여 봄으로써 X에 미치는 영향을 떼어놓고 파악하는 것을 의미합니다.
그렇다고 이런 세그먼트화가 늘 좋은 결과를 가져오는 것은 아닙니다. 이번엔 성별 대신 혈압이라는 변수를 보겠습니다.
저혈압약을 복용한 사람의 87%가 회복했고 (234/270) 복용하지 않은 사람의 93%가 회복했다(81/87).고혈압약을 복용한 사람의 69%가 회복했고 (55/80) 복용하지 않은 사람의 73%가 회복했다 (192/263).전체약을 복용한 사람의 83%가 회복했고 (289/350) 복용하지 않은 사람의 78%가 회복했다 (273/350).
사실 숫자는 똑같지만, 이번엔 거꾸로 전체에서는 약이 효과가 있어 보이는데 각 집단 내에서는 안 좋은 것 같아 보입니다. 여기서 중요한 사실은 이 약이 혈압을 낮춤으로써 병세를 완화시키는 약이라는 것입니다. 혈압이 약 복용의 영향을 받는데 혈압에 따른 집단을 구분해서 보면 판단에 오류가 생깁니다.
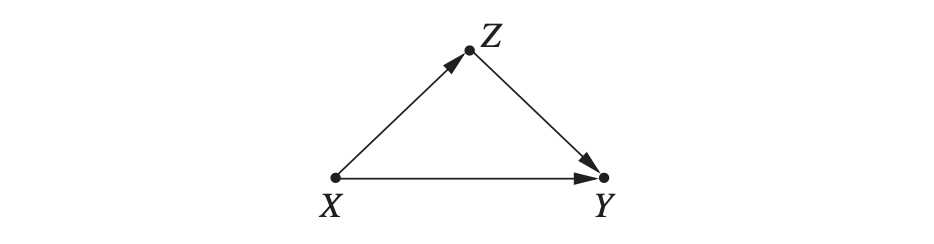
그래프로 보면 이런 경우입니다. 모델 내에서 X의 부모 변수가 없는 걸 확인할 수 있습니다. 이 경우에는 $do(X)$ 를 계산할 때 따로 그래프를 수술할 필요가 없습니다! 그냥 원래 그래프를 그대로 쓰면 됩니다. 즉, 개입(수정 공식)은 항상 필요한 방법이 아닙니다.
언제 어떤 변수에 개입해야 하나?
위에서 다룬 예시를 보면, 어떤 변수 $X$가 다른 변수에 미치는 인과관계를 규명하기 위해 항상 $X$의 부모 변수를 조정해야 하는 것처럼 보입니다. 그러나 가끔 모델에는 있는데 측정치는 없는 부모 변수도 있습니다. 그럼 어떻게 해야 될까요? 대신 다른 변수를 조정하면 될까요? 이 질문은 결국 우리가 실험 없이 관찰 데이터만으로 인과 효과를 계산하려면 어떤 조건이 필요한가, 즉 인과 그래프가 어떤 구조를 하고 있어야 그 자체로 주어진 데이터만으로 인과 효과 계산이 되는가? 라는 질문으로 이어집니다.
개입의 조건: Backdoor Criterion
이걸 판단하기 위해 필요한 기준을 Backdoor criterion이라고 합니다.
DAG $G$ 에서 변수들의 집합 $Z$는 다음 2개 조건을 만족할 때 $(X, Y)$에 대해 Backdoor criterion을 만족한다.
- X의 후손 노드를 포함하고 있지 않다.
- X로 향하는 X와 Y 사이의 모든 경로를 차단한다.
그리고 이 조건을 만족하면, $X$가 $Y$에게 미치는 인과 효과는 $P(Y=y \vert do(X=x)) = \sum_z P(Y=y \vert X=x, Z=z)P(Z=z)$ 처럼 계산할 수 있습니다(조금 전 그 공식과 동일합니다).
X의 부모 변수는 무조건 이 조건을 만족합니다. 즉 부모 변수들은 Backdoor 변수들의 부분집합입니다.
이 로직의 취지(?)는 $X$로 향하는 뒷문을 모두 닫겠다는 것입니다. 자세히는 $Z$에 조건을 걸면서 $X$와 $Y$ 사이에 발생할 수 있는 헷갈리는 경로들을 다 차단하되 X → Y 직접적인 경로는 건드리지 않고 냅두겠다는 것이죠. $Z$를 통해서 $X$와 $Y$ 사이의 관계가 발생할 경우, 그러나 X → Y 와는 상관 없는 영향일 경우 효과를 혼재할 수 있기 때문에 $Z$가 그걸 차단할 수 있다면 $Z$를 수정하면 됩니다. 하지만 만약 그 중 $X$의 후손인 노드가 있다면 $X$의 영향을 받아 $Y$에게 영향을 줄 수 있으므로 그 경우는 수정하지 않습니다.
예를 들어 다음 그래프가 있습니다.
- $X$ : 신약 복용
- $Y$ : 회복
- $W$ : 몸무게
- $Z$ : 사회경제적 지위
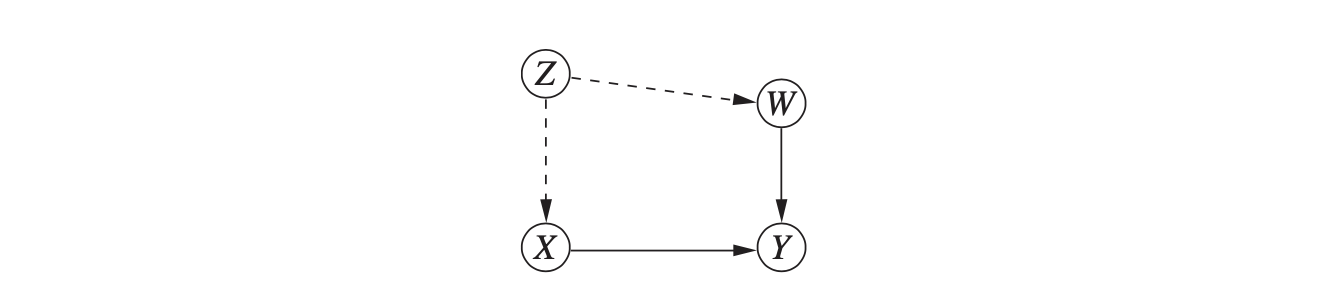
사회경제적 지위가 피험자의 몸무게와 약 복용 여부에 둘 다 영향을 주는데, 이 연구에서는 사회경제적 지위를 조사하지 않았다고 칩시다. 이게 바로 처음 이야기했던 모델에는 있는 부모 변수인데 측정치가 없는 경우 입니다. 이때 $W$는 X ← Z → W → Y 로 충돌부이고, $X$로 향하는 Backdoor 경로를 차단합니다. $X$의 자손 노드도 아니고요. 그래서 Backdoor criterion을 만족하고, 이는 $Z$의 측정치 없이도 $W$ 에 대해 수정함으로써 X → Y 인과를 측정할 수 있다는 의미입니다.
이 조건을 통해 보다 복잡한 그래프에서도 어떤 변수에 대해 개입, 수정할지 찾아낼 수 있습니다. 그리고 개입이 필요 없는 경우도 구분할 수 있죠. 예컨대 아래 그래프는 꽤 복잡해보이지만, X → Y 인과 효과를 계산할 때 $X$에 대해 Backdoor path가 존재하지 않는다는 걸 확인한다면, 수정할 필요 없이 $P(y \vert do(x)) = P (y \vert x)$ 를 그대로 사용하면 된다는 사실을 알 수 있습니다.
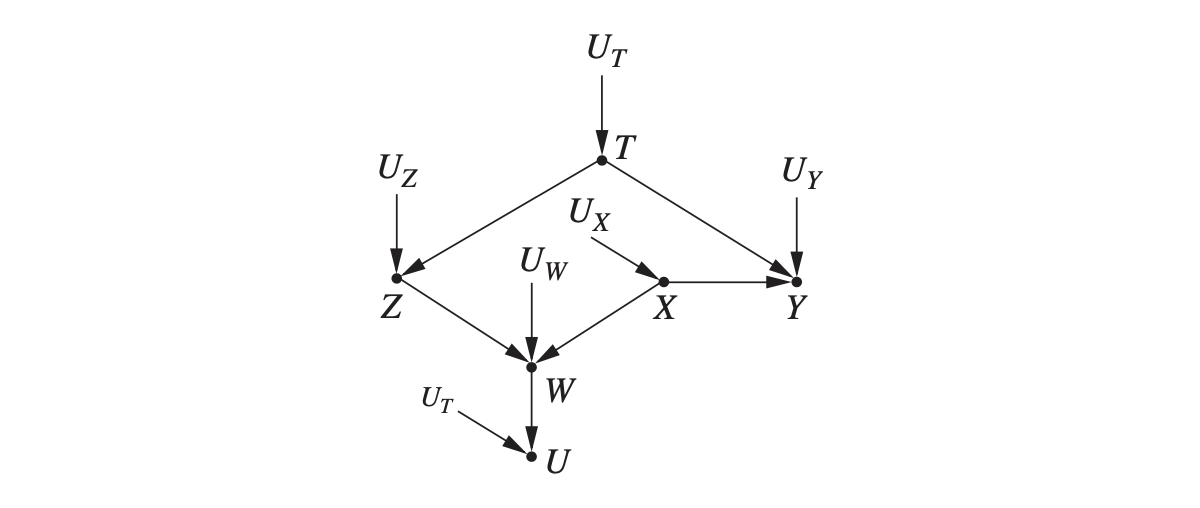
Backdoor 변수가 없을 때: Frontdoor Criterion
그러면 데이터가 없는 부모 변수가 있는데 Backdoor 경로를 차단해줄 수 있는(+ 데이터도 있는) 몸무게 $W$ 같은 변수가 없다면 어떻게 할까요? 이때 필요한 것이 Frontdoor criterion입니다.
굉장히 역사가 깊은 흡연과 폐암의 관계 논쟁을 마지막 예시로 들어 봅시다. 1970년대 이전에 담배 회사들은 흡연과 폐암 간 상관이 있긴 하지만, 그건 특정 유전자형이 암 발병과 흡연 욕구를 동시에 유발하기 때문이라는 주장을 펼쳤다고 합니다.
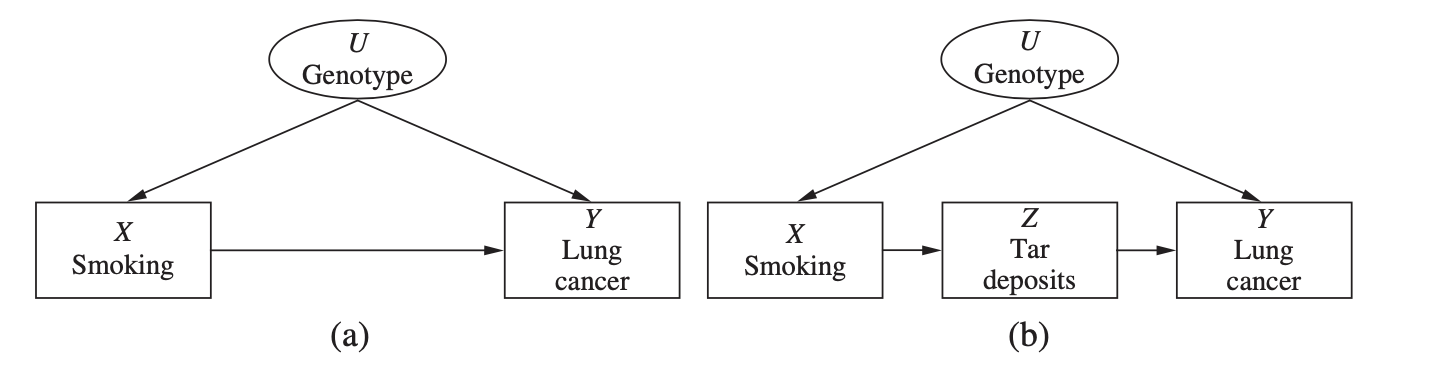
유전자형에 대한 측정치가 없는 상황이라면 좌측 그림의 그래프는 이 주장을 확인하기에 부적절합니다. 우리가 알고 싶은 건 흡연 $X$ 와 폐암 $Y$ 간의 인과인데, 두 변수 모두 유전자형 $U$ 의 영향을 받지만, 유전자형 데이터가 없으면 개입으로 Backdoor 경로를 차단할 수 없거든요. 우측 그림에는 환자의 폐에 쌓여 있는 타르 양 $Z$ 이 새로운 변수로 등장합니다. 그러나 이 그래프에서도 수정해야 하는 변수의 데이터가 없는 문제는 똑같이 남아 있습니다.
$X$와 $Y$ 사이에 관찰된 상관이 순전히 유전자형 때문일까요? 유전자형의 영향을 어떻게 배제하고 볼까요?
이처럼 분명 인과 효과를 혼란시키는 변수가 분명히 있는데, 그 변수에 대한 데이터가 없어서 Backdoor 경로를 차단할 수 없을 때는 Frontdoor criterion을 사용하면 됩니다. 중간에 등장한 변수 $Z$ 를 이용해 Backdoor criterion을 두 번 연속적으로 적용하면 X → Y 인과효과를 계산할 수 있습니다!
다음 순서를 따라가 봅니다.
X → Y: 이 효과는X → Z효과와Z → Y효과 2개로 쪼갤 수 있다. $P(Y=y \vert do(X=x)) = \sum_z P(Y=y \vert do(Z=z))P(Z=z \vert do(X=x))$X → Z: Backdoor 경로가 없으니까 그냥 $P(Z=z \vert do(X=x)) = P(Z=z \vert X=x)$ 이다.Z → Y:Z ← X ← U → Y라는 Backdoor 경로가 있지만, X가 이를 차단한다. 즉 Z의 관점에서는 X가 Backdoor 조건을 만족하는 수정 변수다. 그래서 $P(Y=y \vert do(Z=z)) = \sum_x P(Y=y \vert Z=z, X=x)$다.- 위 둘을 사용하면, $P(Y=y \vert do(X=x)) = \sum_z \sum_{x’} P(Y=y \vert Z=z, X=x’)P(X=x’)P(Z=z \vert X=x)$
즉 최종 식의 우변에는 $do()$ 형태가 사라지고 우리가 가지고 있는 데이터들로만 계산할 수 있는 $P(Y=y \vert do(X=x))$ 가 남게 됩니다.
여기서 Frontdoor criterion 을 정리하면 이렇습니다.
DAG $G$ 에서 변수들의 집합 $Z$는 다음 3개 조건을 만족할 때 $(X, Y)$에 대해 Frontdoor criterion을 만족한다.
- X에서 Y로 가는 모든 직접 경로 사이에 있는 노드이다.
- X에서 Z로 가는 모든 경로가 차단되지 않은 상태다.
- Z에서 Y로 가는 모든 backdoor 경로는 X에 의해 차단된다.
그리고 이 조건을 만족하면 $X$가 $Y$에게 미치는 인과 효과는 $P(Y=y \vert do(x)) = \sum_z P(z \vert x) \sum_{x’} P(y \vert x’, z) P(x’)$ 처럼 계산할 수 있습니다.
💬 벌써 인과 추론 세번째 글이네요! 계획했던 글 중에서는 1. 지금 보는 책의 마지막 장인 반사실(Counterfactuals)에 대한 글과 2. 파이썬이나 R로 간단한 인과 추론 실습을 해보는 글 이렇게 2가지를 남겨두고 있습니다.