스파크가 뭔지만 대충 아는 사람을 위한 RDD 설명
스파크의 RDD와 관련된 개념들(Transformation & Action, DAG, Lazy Evaluation)에 대해 무엇인지 쉽고 간단하게 정리해보는 글입니다.
스파크를 처음 접하게 되면 보통 아래와 같은 정보들을 순차적으로 접하게 됩니다.
- 아파치 스파크는 빅데이터를 위한 분산 병렬 처리 프레임워크다. 이전에 비슷한 목적의 하둡 맵리듀스라는 게 있었는데 그거 대비 뭔가 더 좋다더라.
- 스파크의 주요 데이터 구조 중에는 RDD라는 저수준 API가 있고 DataFrame이라는 고수준 API가 있대.
- DataFrame은 뭔지 아는데 RDD는? 탄력적인 분산 데이터셋이고 변경이 불가능한 Read-Only 란다.
- (일단 여기서부터.. 🤔? 변경이 불가능한데 탄력적인 게 뭐야 따뜻한 아이스아메리카노?)
- DataFrame은 뭔지 아는데 RDD는? 탄력적인 분산 데이터셋이고 변경이 불가능한 Read-Only 란다.
특히 저처럼 데이터 분석가라면 처음 스파크를 써볼 때 RDD의 존재가 참 애매할 것입니다. 아니 남들까지 일반화하면 좀 그러니까 과거의 저는 그랬다고 고백을 해 봅니다. 이전에 R을 썼든 파이썬을 썼든 데이터 만져 봤으면 데이터프레임 모르는 사람은 없죠? 근데 RDD는 뭐래요? 일단 정의를 들으면 무슨 말인지 잘 모르겠거든요. 그리고 일단 써보기 시작하면 RDD가 뭔지 전혀 이해하지 못하고도 큰 지장은 없습니다. 그냥 spark sql 문법만 익혀서 코드 작성하면 나한테 익숙한 형태인 DataFrame을 가지고 내가 원하는 작업들이 그럭저럭 돌아가니깐요.
오늘은 그런 분들을 위한 간단한 RDD 설명글을 적어보겠습니다. 사실 RDD는 ‘뭔지 모르겠고 이해할 필요 없는 것 같다’는 첫인상과 달리 스파크의 핵심적인 개념이기 때문입니다.
하둡 맵리듀스 ➡️ 스파크
우선 스파크가 뭔지 대충 아신다면 분산 병렬 처리 시스템도 대충은 아실 것입니다. 간단하게는 데이터가 너무 크고 작업이 너무 빡세니 한 컴퓨터로 하지 말고 여러 컴퓨터로 나눠서 동시에 한 다음에 합치면 되지 않겠냐는 아이디어고, 하둡 맵리듀스는 그 아이디어를 실제로 성공적으로 실행할 수 있게 해준 프로젝트였습니다.
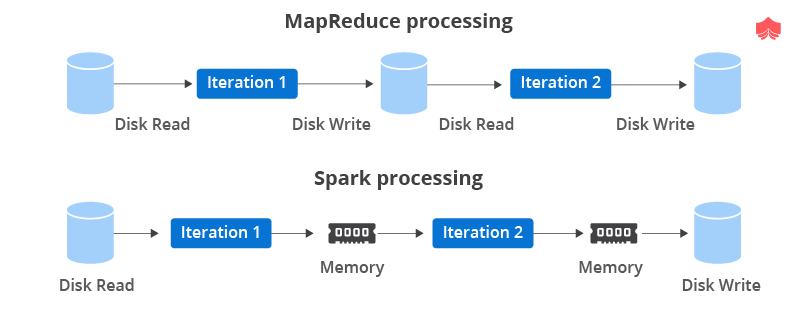
스파크는 그 이후에 등장했습니다. 스파크가 하둡 맵리듀스와 결정적으로 다른 점은 In-Memory라는 것, 즉 메모리 위에서 처리를 한다는 것입니다. 기존 하둡 맵리듀스는 디스크로부터 데이터를 불러오고 처리한 결과를 디스크에서 쓰고, 이걸 반복하는 과정에서 (읽고 쓰기) 속도가 느려질 수밖에 없었습니다. 매번 스테이지마다 결과를 디스크에 저장하고 다시 읽어와서 다음 작업을 하기 때문에 실시간 서비스에는 적용이 어려웠고 배치성 작업 위주로 가능하다는 단점도 있었죠.
 비교 (출처)
비교 (출처)
반면 스파크는 메모리에서 처리하고 쓰기 때문에 매번 불필요한 디스크 I/O가 발생하지 않아 훨씬 빠르고, 스트리밍 데이터를 다룰 수 있다는 장점이 있죠. 그런데 만약 메모리 용량은 아무래도 한계가 있을 텐데 큰 데이터를 올렸다가 뭐가 잘못되면 어떻게 하나요? 중간에 디스크에 쓰지도 않는데 날아가면 처음부터 다시 해야 하나요?
그렇게 해서 RDD가 등장합니다.
RDD
RDD는 신생아 시절의 스파크의 핵심 API였습니다. 2.x 버전 이상으로 올라오면서부터는 명백한 목적이 있지 않은 이상 잘 사용하지 않게 되었으나, 우리가 잘 아는 DataFrame과 같은 보다 더 고수준의 API 를 다루는 코드도 결국 사실상 RDD로 컴파일됩니다.
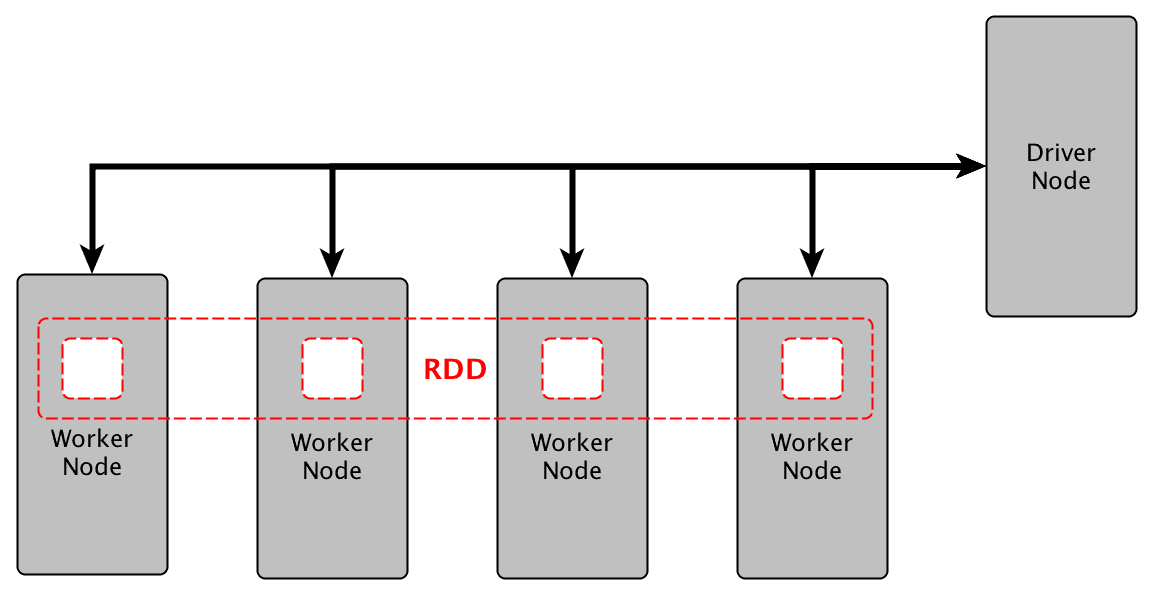
우선 잘 이해 안 되는 이름부터 시작하면 RDD는 Resilient Distributed Dataset으로 탄력적인 분산 데이터셋으로 번역할 수 있겠습니다. ‘분산’은 뭐 우리가 분산 컴퓨팅을 하려고 하는 것이니 별로 어려울 것 없이 여러 곳에 분산되어 저장된 데이터셋이라고 보면 되고요.
 RDD는 여러 개의 파티션에 나누어서 위치함 - 클러스터의 여러 워커 노드에 의해 연산이 수행되도록 (출처)
RDD는 여러 개의 파티션에 나누어서 위치함 - 클러스터의 여러 워커 노드에 의해 연산이 수행되도록 (출처)
문제는 저 ‘탄력적’이라는 게 대체 무슨 뜻이냐는 것인데요. 출발점으로 다시 돌아가면 우리는 메모리 위에서 모든 작업을 할 건데 하다가 잘못되면 어떻게 하냐? 가 문제였죠. 이 탄력적이란 말은 RDD가 그런 에러나 사고 상황에 탄력적으로 잘 대처할 수 있다는 소리입니다.
그리고 그게 어떻게 가능한지를 이해하려면 RDD의 가장 중요한 특성: 불변(immutable)하며 Read-only, 즉 저장 시스템에서 읽어오는 것만 가능하다. 를 알면 됩니다.
RDD는 불변이기 때문에 처음 만들어진 이후에 어떤 변경도 가해지지 않았다는 게 보장됩니다. 그러면 데이터가 먼지처럼 날라갈지언정 처음 그것이 어떻게 만들어졌었는지만 우리가 잘 기록하고 있다면! 그냥 똑같이 다시 만들 수 있습니다. 그렇기 때문에 뭔가 모순 같은, ‘불변이라 탄력적’이라는 말이 성립하게 되죠.
그러면 그 기록은 어떻게 되어 있을까요? RDD는 다음 속성들로 구분됩니다.
- 파티션: 데이터가 어떻게 나뉘어져 있는지
- 연산 함수: 각 조각이 어떤 연산을 통해 만들어졌는지
- 의 존성: 위 연산을 하려면 다른 부모 RDD가 필요할 경우 그 정보
- 위치 목록: 각 파티션을 연산하기 위한 위치는 어디인지 (ex. HDFS의 어딘가)
- 파티셔너: 데이터를 어떻게 파티션으로 나눌 것인지 (ex. 해시 파티셔너)
즉 이런 정보(일종의 lineage)만 있으면 우리는 언제든 RDD를 다시 만들어낼 수 있는 것입니다.
Transformation
자연스럽게 의문이 생깁니다. 변경을 못한다고? 변경을 하고 싶으면 어떡해? → 하면 됩니다. 단, 우리가 RDD에 가하는 모든 변경(연산) 작업은 그 RDD를 바꾸는 것이 아닙니다. 스파크는 매번 이전 RDD를 기반으로 새로운 RDD를 만들고, 그 이전 RDD에 대한 정보와 어떤 연산을 했는지를 기록해 두게 됩니다(= 리니지). 이때 RDD에 가해지는 연산을 다른 이름으로 Transformation 이라고 부릅니다.
![]()
모든 Transformation은 위와 같은 DAG 로 기록됩니다. DAG는 Directed Acyclic Graph = 방향성이 있는 비순환 그래프를 의미합니다. 쉽게 말하면 한쪽 방향으로만 가고 돌아는 못 온다는 소립니다. 그림으로 보면 딱 보이긴 하지만요. 이 그래프에서 각 노드는 RDD 파티션이고, 엣지는 Transformation입니다.
저 그림에서 groupBy, map, union, join과 같은 여러 Transformation의 예시를 엿볼 수 있습니다. 참고로 Transformation은 좁은 것과 넓은 것으로 나뉘는데, 이런 뜻입니다.
- 좁은 트랜스포메이션: 각 입력 파티션이 하나의 출력 파티션에만 영향을 미칠 때. 즉 파티션 간 교환이 일어날 필요가 없을 때 ex. filter
- 넓은 트랜스포메이션: 하나의 입력 파티션이 여러 출력 파티션에 영향을 미칠 때. 즉 파티션 간 교환(shuffle)이 발생할 때 ex. join
Lazy Evaluation, Action
위에서처럼 DAG이 만들어졌다고 칩시다. 하지만 이때까지는 아무 일도 일어나지 않습니다. 뭔 말이냐고요? 그냥 그래프를 기록만 해두고 스파크는 가만히 기다립니다. 언제까지? 우리가 실제로 그 결과를 요구할 때까지요.
결과를 요구하는 것의 예시 :
- 가장 첫번째 데이터를 보여줘
- 전체가 몇 개인지 세줘
- 나 파이썬 쓰는데 파이썬 객체에 데이터를 모아줘
- 여기다가 저장해줘
- …
Transformation의 결과물을 달라고 요구하는 것을 우리는 Action이라고 부릅니다. Action의 단계가 오면 스파크는 그제서야 필요한 연산들을 실제로 수행하기 시작합니다.
이게 뭐가 좋냐면, 전체 그림을 다 그려놓고 마지막의 마지막까지 기다렸다가 한꺼번에 실행을 함으로써 스파크는 우리가 원하는 결과물을 최적화된 방법으로 처리할 수 있게 됩니다.
예를 들어 누군가 피자 주문을 하려고 저녁 전에 저한테 A, B, C 구역을 돌면서 각각 무슨 메뉴를 몇 판씩 시킬 건지 알아오라고 시켰다고 칩시다. 만약 제가 부지런했다면 그 말이 끝나는 즉시 달려나가 메뉴를 다 적어왔을 겁니다. 그러고 나니 갑자기 A구역만 피자를 시키기로 했다면서 거기 주문 정보만 달라고 한다면? 그럼 저는 이제 제가 알아 온 전체 정보에서 A만 필터링해서 주면 되겠죠. 충분히 요청 사항은 해결한 것 같습니다. 하지만 저는 세 군데나 돌아다니느라 너무 많은 시간과 기운을 써버렸잖아요? 반대로 제가 무척 게으른 사람이라서 저녁 직전까지 일을 미루고 있었더니 갑자기 A만 알아오라길래 거기만 다녀오는 상황을 상상해 봅시다. 역시 성공적으로 원하는 정보를 얻었지만 제가 들인 수고는 훨씬 더 적을 겁니다. 이게 바로 Lazy evaluation (지연 연산) 입니다.