스파크는 내 코드를 어떻게 실행할까? (Logical Plan과 Physical Plan)
스파크의 구조적 API의 실행 계획에 대해 알아봅니다.
이번 글의 주제는 우리가 작성한 스파크 코드가 어떻게 실제 스파크 내부의 실행 코드로 변환되는지 그 과정을 살펴보는 것입니다.
오늘 다룰 내용은 아래와 같은 한 장의 그림으로 요약될 수 있습니다.
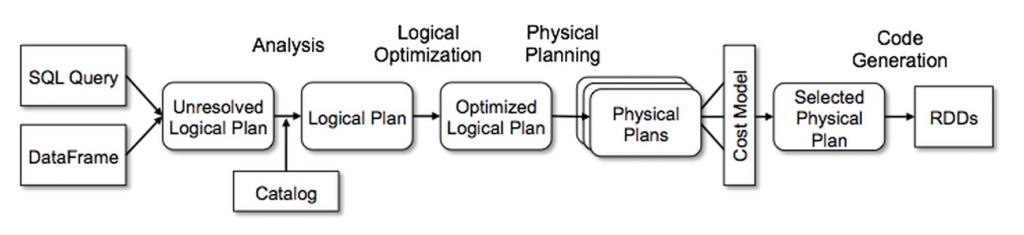
예시
테이블 만들기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
pizza_schema = T.StructType([ T.StructField('id', T.IntegerType(), True), T.StructField('pizza', T.StringType(), True), T.StructField('price', T.IntegerType(), True) ]) customer_schema = T.StructType([ T.StructField('id', T.IntegerType(), True), T.StructField('address', T.StringType(), True) ]) order_schema = T.StructType([ T.StructField('id', T.IntegerType(), True), T.StructField('pizzaId', T.IntegerType(), True), T.StructField('customerId', T.IntegerType(), True), T.StructField('count', T.IntegerType(), True) ]) pizza = spark.createDataFrame([ [0,'페퍼로니',23500], [1,'하와이안',24500], [2,'치킨바베큐',29500] ], schema = pizza_schema ) customer = spark.createDataFrame([ [0, 'A동'], [1, 'B동'], [2, 'B동'], [3, 'A동'], [4, 'C동'], [5, 'A동'], [6, 'C동'], [7, 'C동'], ], schema = customer_schema ) order = spark.createDataFrame([ [100, 2, 4, 1], [100, 0, 3, 3], [100, 0, 1, 2], [100, 1, 0, 1], [100, 2, 6, 2], [100, 2, 2, 1], ], schema = order_schema )
각 동에서 무슨 피자를 얼만큼 시켜먹었는지를 알고 싶습니다.
→ 각각 다른 테이블에서 피자 가격 정보와 각 주문자의 주소(동) 정보를 가져오고 동과 피자 별로 합을 계산하자.
1
2
3
4
5
6
7
df = (order
.join(pizza, pizza.id == order.pizzaId, how = 'inner')
.join(customer, customer.id == order.customerId, how = 'inner')
.groupBy('pizza','address')
.agg(F.sum(F.col('count')*F.col('price')).alias('sum'))
)
df.show()

이렇게 간단한 집계를 실행할 때 스파크 내부적으로는 어떤 일이 일어나고 있을까요?
맨 처음 그림에 나와 있는 단계를 하나하나 살펴보도록 하겠습니다.
Logical Plan
로지컬 플랜은 말 그대로 논리적인 수준에서만 추상적인 트랜스포메이션을 지정하는 것을 말합니다. 이 단계에서는 아직 익스큐터가 어떻게 실행할지는 고려하지 않습니다.
Unresolved Logical Plan → Analysis
그냥 입력한 대로 받아들인 플랜입니다. Parsed Logical Plan이라고도 합니다. 제가 작성한 코드에 문법적인 문제가 없다면, 이 플랜까지는 잘 만들어집니다. 실제로 그런 테이블이 있는지, 컬럼명이 유효한지 확인하지 않고 우선 플랜을 만드는 것입니다.
explain() 을 사용하면 각 단계에서 어떤 플랜이 세워졌는지 출력해서 볼 수 있는데요, 여러가지 mode를 지원하고 있고, 따로 설정하지 않으면 마지막 Physical Plan을 보여주므로 다음과 같이 extended 으로 설정해 줍니다. (문서)
1
df.explain(mode='extended')
가장 먼저 나오는 게 이 Unresolved Logical Plan입니다.

이제 스파크의 Analyzer가 우리가 넣은 칼럼과 테이블을 검증하는데, 카탈로그, 모든 테이블의 저장소와 데이터프레임 정보를 이용해 체크합니다.
만약 컬럼이나 테이블 등에 문제가 있다면 스파크는 이 단계에서 플랜을 거절하게 됩니다. 예를 들어 제가 칼럼 이름 하나의 한 글자를 대문자인데 소문자로 잘못 썼다면 (너무 자주 있는 일… ), 다음과 같은 에러를 보게 될 것입니다.
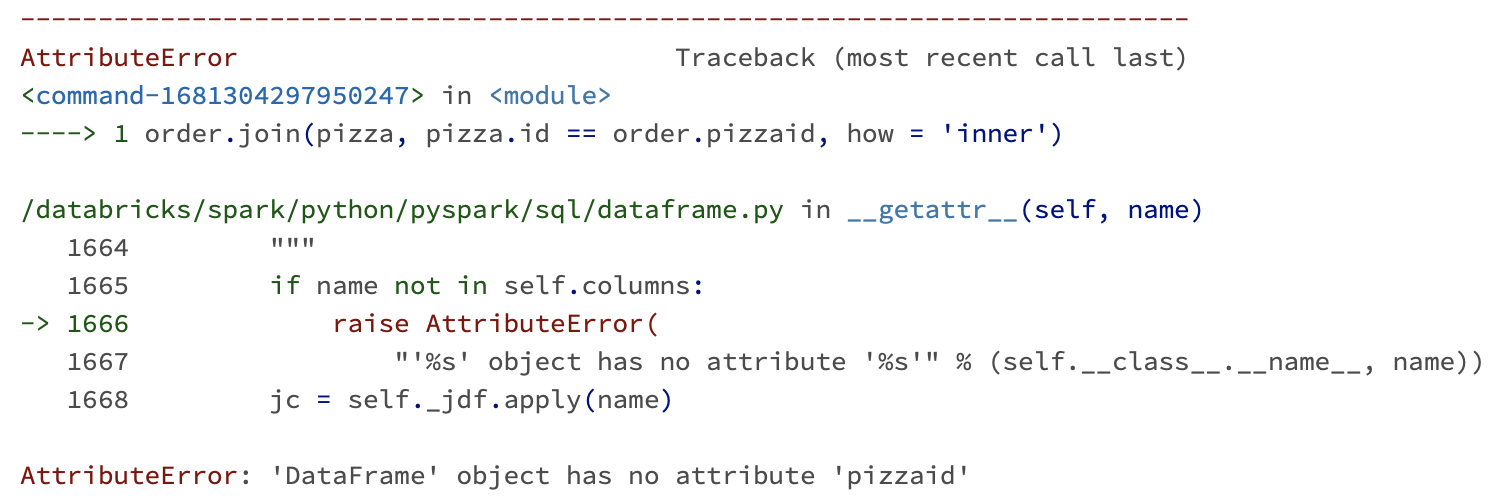
하지만 검증 결과 코드가 유효하다고 판단되었다면 다음 단계로 갑니다.
Resolved Logical Plan → Logical Optimization
데이터 구조, 스키마 등에 문제가 없다고 확인이 된 상태의 계획으로, Analyzed Logical Plan 이라고도 합니다.
 이제 계획을 최적화하는 단계로 넘어갑니다. 이제 Catalyst Optimizer 가 모든 태스크가 수행 가능하며 하나로 계산될 수 있는지, 멀티조인시 쿼리 실행을 어떤 순서로 할 건지, 조건절 푸시다운이나 선택절 구문 등을 사용해서 위의 계획을 최적화합니다. 이 Optimizer는 각자 유즈케이스에 맞게 확장하여 만들 수도 있습니다.
이제 계획을 최적화하는 단계로 넘어갑니다. 이제 Catalyst Optimizer 가 모든 태스크가 수행 가능하며 하나로 계산될 수 있는지, 멀티조인시 쿼리 실행을 어떤 순서로 할 건지, 조건절 푸시다운이나 선택절 구문 등을 사용해서 위의 계획을 최적화합니다. 이 Optimizer는 각자 유즈케이스에 맞게 확장하여 만들 수도 있습니다.
Optimized Logical Plan
최적화가 된 플랜은 요렇게 생겼습니다.
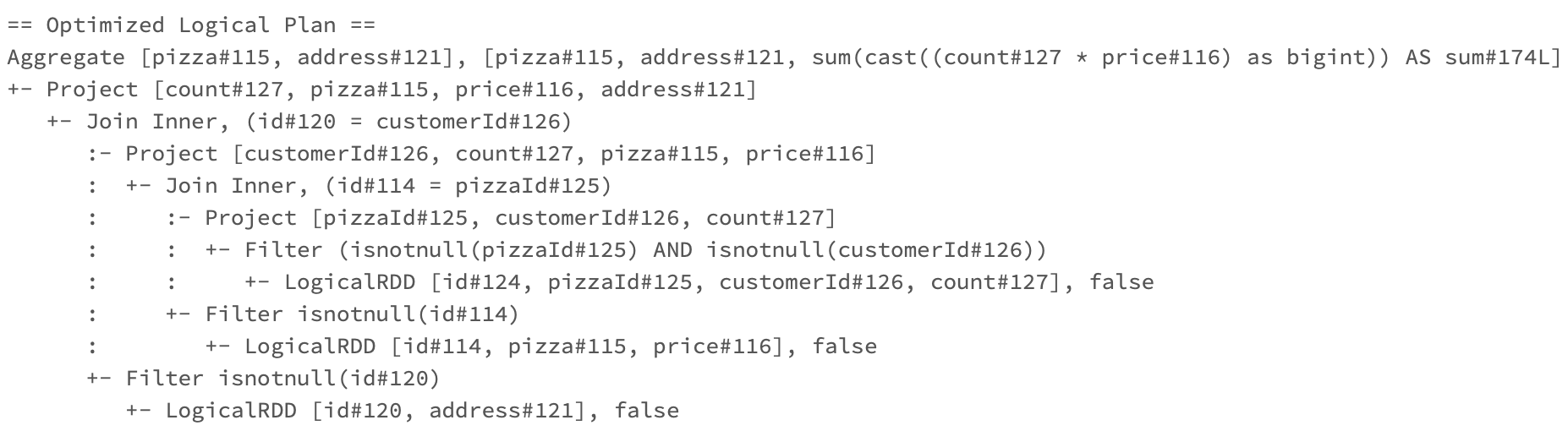
제 원래 코드가 크게 복잡한 작업이 아니었기 때문에 최적화된 플랜은 필요한 칼럼만 고르고(Project), 값이 없는 것은 제외하도록(Filter) 하는 정도만 추가된 것 같습니다. 사실 원래 코드에 특별히 필터가 없었고, 그래서 이 최적화된 플랜에서도 null 값 필터링 정도만 확인할 수 있는데요. 만약 제 코드에 여러 개의 복잡한 필터 조건을 걸었다면, 보통 Catalyst Optimizer는 필터 조건을 원 데이터에 가장 가깝게(가능한 한 최대한 먼저 필터링하도록) 옮기고, 불필요한 필터는 없애고, 여러 필터를 합치는 등의 최적화를 해 주었을 겁니다.
Physical Plan
이제 그럼 이 로지컬 플랜을 실제로 어떻게 실행할 것인지 물리적 실행 계획을 생성하는 단계로 넘어갑니다.
Physical Plans→ Cost Model Analysis
이 단계에서 우리의 계획은 갑자기 복수형으로 변합니다. 스파크는 하나의 계획이 아닌 여러 가지 물리적 실행 계획을 만들어본 다음, 비용 모델을 통해 각 계획에 소요되는 시간이나 리소스를 비교합니다. 이때 사용하는 테이블의 크기나 파티션 수 등 물리적 속성을 고려하게 되죠. 비용 분석을 진행한 결과, 가장 최적의 계획 하나를 선택하게 됩니다.
Selected Physical Plan → Code Generation
스파크 3.0에서는 explain() 메서드의 mode='formatted'를 이용하면 아래와 같이 최종 선택된 물리적 실행 계획의 아웃라인을 보기 좋게 뽑아볼 수 있습니다. 그리고 좀 더 내려보면 각 노드의 디테일도 확인할 수 있고요.
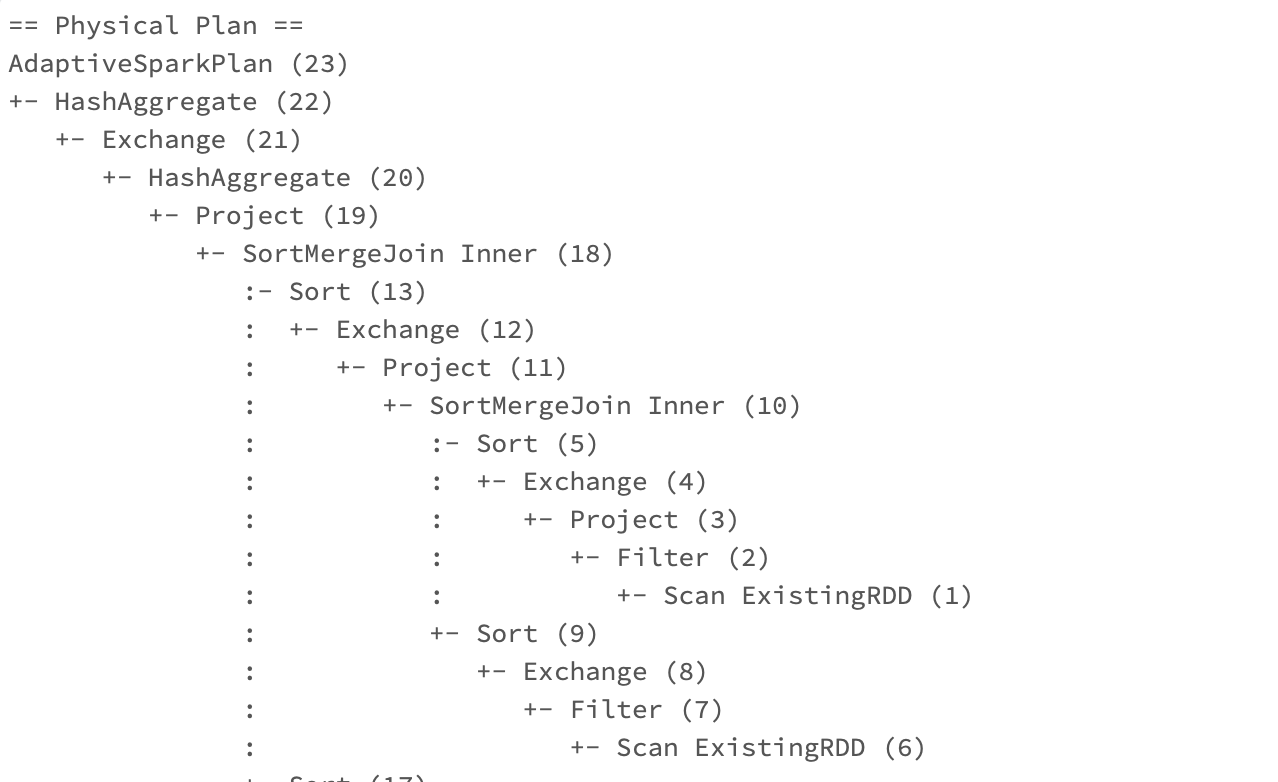
이 플랜을 확인하면서 우리는 성능을 위해 코드를 개선해볼 여지가 있는지 한번 확인해 볼 수 있습니다. Exchange는 셔플을 의미하고, 조인이나 리파티셔닝, 소팅 혹은 Coalesce처럼 하나의 익스큐터로 데이터를 옮길 때 모두 발생할 수밖에 없는데요, 불필요한 셔플이 너무 많이 발생하지 않도록 하는 것은 성능 최적화에 있어서 가장 중요한 부분이라고 해도 과언이 아닙니다. 또 조인을 하더라도 어떤 조인을 사용하고 있는지(위에서는 SortMergeJoin)를 확인할 수 있고, 이 조인 방식에 따라서도 성능에 큰 영향을 줄 수 있습니다.
참고로 동일한 내용은 Spark UI의 SQL 탭에 가서도 DAG 그림 형태로 확인할 수 있습니다.
어쨌든 이 플랜이 최종적으로 선택되고 나면, Tungsten 실행 엔진에 의해 클러스터에서 동작하기 위해 코드가 생성됩니다. 저는 구조적 API(DataFrame)으로 정의된 쿼리를 썼지만 이 단계에서 스파크가 저수준 인터페이스인 RDD 트랜스포케이션으로 컴파일해주는 것입니다. 이렇게 만들어진 RDD의 DAG에 따라 모든 코드가 실행되며, 런타임에 전체 태스크나 스테이지를 제거할 수 있는 자바 바이트 코드를 생성해 추가적인 최적화를 수행해 줍니다.