스파크 GraphFrames 튜토리얼
GraphFrames을 이용한 몇 가지 간단한 그래프 분석 튜토리얼입니다. 스파크 완벽 가이드 30장 그래프 분석을 바탕으로 정리한 내용입니다.
스파크는 그래프 처리를 지원하는 RDD 기반의 라이브러리 GraphX를 제공하고 있습니다. 다만 저수준의 인터페이스로 인해 간편한 사용은 조금 어려울 수 있는데, 그 이후에 DataFrame API를 제공하고 스파크가 지원하는 다양한 언어를 사용할 수 있도록 하는 GraphFrames이 개발되었습니다.
이번 글의 예제 데이터는 Bay Area Bike Share 포털에서 무료 공개한 자전거 여행 데이터입니다(단, 해당 데이터가 현재는 접근이 불가능하다고 합니다. 이번 글은 스파크 완벽 가이드 책의 30장을 기반으로 정리한 내용이며, 해당 도서 관련 깃헙에 예제 용 데이터가 올라와 있으므로 이 주소에서 받으시면 동일한 결과를 얻을 수 있습니다). 예저 코드의 경우 글쓴이가 익숙하다는 이유로 python 코드만 정리하였으며, 동일 예제에 대한 scala 코드도 여기에서 확인하실 수 있습니다. 따라해보실 경우 스파크 설치 후 로컬 환경에서 실행할 수도 있겠지만, 데이터브릭스 무료 커뮤니티 에디션을 이용하는 게 가장 간편한 방법 중 하나일 것 같습니다.
자전거 여행 데이터는 대충 아래와 같습니다. 각 자전거와 한번의 이동(여행)마다 ID가 있고, 출발/도착 시간과 출발/도착 정류장의 정보를 가지고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#여행 정보
tripData.show(10)
+-------+--------+---------------+--------------------+--------------+---------------+--------------------+------------+------+---------------+--------+
|Trip ID|Duration| Start Date| Start Station|Start Terminal| End Date| End Station|End Terminal|Bike #|Subscriber Type|Zip Code|
+-------+--------+---------------+--------------------+--------------+---------------+--------------------+------------+------+---------------+--------+
| 913460| 765|8/31/2015 23:26|Harry Bridges Pla...| 50|8/31/2015 23:39|San Francisco Cal...| 70| 288| Subscriber| 2139|
| 913459| 1036|8/31/2015 23:11|San Antonio Shopp...| 31|8/31/2015 23:28|Mountain View Cit...| 27| 35| Subscriber| 95032|
| 913455| 307|8/31/2015 23:13| Post at Kearny| 47|8/31/2015 23:18| 2nd at South Park| 64| 468| Subscriber| 94107|
| 913454| 409|8/31/2015 23:10| San Jose City Hall| 10|8/31/2015 23:17| San Salvador at 1st| 8| 68| Subscriber| 95113|
| 913453| 789|8/31/2015 23:09|Embarcadero at Fo...| 51|8/31/2015 23:22|Embarcadero at Sa...| 60| 487| Customer| 9069|
| 913452| 293|8/31/2015 23:07|Yerba Buena Cente...| 68|8/31/2015 23:12|San Francisco Cal...| 70| 538| Subscriber| 94118|
| 913451| 896|8/31/2015 23:07|Embarcadero at Fo...| 51|8/31/2015 23:22|Embarcadero at Sa...| 60| 363| Customer| 92562|
| 913450| 255|8/31/2015 22:16|Embarcadero at Sa...| 60|8/31/2015 22:20| Steuart at Market| 74| 470| Subscriber| 94111|
| 913449| 126|8/31/2015 22:12| Beale at Market| 56|8/31/2015 22:15|Temporary Transba...| 55| 439| Subscriber| 94130|
| 913448| 932|8/31/2015 21:57| Post at Kearny| 47|8/31/2015 22:12|South Van Ness at...| 66| 472| Subscriber| 94702|
+-------+--------+---------------+--------------------+--------------+---------------+--------------------+------------+------+---------------+--------+
1
2
3
4
5
6
7
8
9
10
11
#정류장 정보
bikeStations.show(5)
+----------+--------------------+---------+-----------+---------+--------+------------+
|station_id| name| lat| long|dockcount|landmark|installation|
+----------+--------------------+---------+-----------+---------+--------+------------+
| 2|San Jose Diridon ...|37.329732|-121.901782| 27|San Jose| 8/6/2013|
| 3|San Jose Civic Ce...|37.330698|-121.888979| 15|San Jose| 8/5/2013|
| 4|Santa Clara at Al...|37.333988|-121.894902| 11|San Jose| 8/6/2013|
| 5| Adobe on Almaden|37.331415| -121.8932| 19|San Jose| 8/5/2013|
| 6| San Pedro Square|37.336721|-121.894074| 15|San Jose| 8/7/2013|
+----------+--------------------+---------+-----------+---------+--------+------------+
그래프 작성하기
그래프의 구성요소는 정점(node)와 엣지(edge) 또는 링크입니다. 또 엣지에 방향이 있는지 없는지에 따라 방향성(directed) 그래프와 비방향성(undirected) 그래프로 나뉩니다.
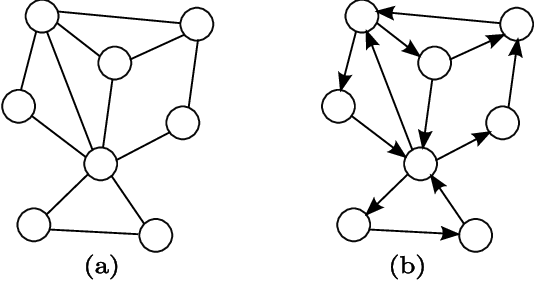 (a) 비방향성 (b) 방향성 그래프
(a) 비방향성 (b) 방향성 그래프
GraphFrame은 다음과 같이 그래프를 생성합니다. 우리가 다루는 것은 출발지와 도착지가 있는 여행 데이터이므로, 방향성 그래프를 생성하고, 식별자를 id 로, 시작 정점 ID는 src , 도착 정점 ID를 dst 로 지정해 줍니다.
1
2
3
4
5
6
7
8
9
from graphframes import GraphFrame
import pyspark.sql.functions as F
stationVertices = bikeStations.withColumnRenamed('name', 'id').distinct()
tripEdges = (tripData
.withColumnRenamed('Start Station', 'src')
.withColumnRenamed('End Station', 'dst')
)
stationGraph = GraphFrame(stationVertices, tripEdges)
stationGraph.cache()
그래프가 잘 만들어졌는지 카운팅해봅니다.
1
2
3
4
5
6
print('정거장 수: ' + str(stationGraph.vertices.count()) )
print('전체 여행 수: ' + str(stationGraph.edges.count()) )
print('전체 여행 수 원 데이터: ' + str(tripData.count()) )
정거장 수: 70
전체 여행 수: 354152
전체 여행 수 원 데이터: 354152
그래프 쿼리하기
가장 간단한 작업부터, 쿼리로 여행 횟수를 계산하거나 종료 지점을 선택하여 필터링할 수 있습니다. GraphFrame은 노드과 에지 모두 DataFrame으로 손쉬운 접근이 가능합니다. 위에서 지정한 기존 ID, source, destination 외에도 기타 추가되는 칼럼이 계속 유지되므로 필요할 때 언제든 쿼리할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
stationGraph.edges.groupBy('src', 'dst').count().orderBy(F.desc('count')).show(10)
+--------------------+--------------------+-----+
| src| dst|count|
+--------------------+--------------------+-----+
|San Francisco Cal...| Townsend at 7th| 3748|
|Harry Bridges Pla...|Embarcadero at Sa...| 3145|
| 2nd at Townsend|Harry Bridges Pla...| 2973|
| Townsend at 7th|San Francisco Cal...| 2734|
|Harry Bridges Pla...| 2nd at Townsend| 2640|
|Embarcadero at Fo...|San Francisco Cal...| 2439|
| Steuart at Market| 2nd at Townsend| 2356|
|Embarcadero at Sa...| Steuart at Market| 2330|
| Townsend at 7th|San Francisco Cal...| 2192|
|Temporary Transba...|San Francisco Cal...| 2184|
+--------------------+--------------------+-----+
특정 도착지(Townsend at 7th)를 기준으로 해당 지점에서 출발과 도착 횟수를 다음과 같이 계산합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
stationGraph.edges.where("src ='Townsend at 7th' OR dst = 'Townsend at 7th' ").groupBy('src', 'dst').count().show(10)
+--------------------+--------------------+-----+
| src| dst|count|
+--------------------+--------------------+-----+
| 2nd at South Park| Townsend at 7th| 312|
|Embarcadero at Br...| Townsend at 7th| 197|
| Clay at Battery| Townsend at 7th| 83|
| 5th at Howard| Townsend at 7th| 317|
| Townsend at 7th|South Van Ness at...| 368|
| Market at Sansome| Townsend at 7th| 278|
| Townsend at 7th|San Francisco Cit...| 46|
| Townsend at 7th| Market at 10th| 387|
|San Francisco Cal...| Townsend at 7th| 1198|
|Washington at Kearny| Townsend at 7th| 60|
+--------------------+--------------------+-----+
규모가 큰 그래프 안에서 형성되는 작은 규모의 그래프를 서브그래프라고 합니다.
1
2
townAnd7thedges = stationGraph.edges.where("src ='Townsend at 7th' OR dst = 'Townsend at 7th' ")
subgraph = GraphFrame(stationGraph.vertices, townAnd7thedges)
모티프 찾기
모티프란 구조적 패턴을 그래프로 표현하는 방법입니다. 모티프를 지정하면 실제 데이터 대신 데이터의 패턴을 쿼리합니다. DataFrame에서는 Neo4J의 Cypher 언어와 유사한 도메인에 특화된 언어로 쿼리를 지정하는데, 이 언어를 사용하면 정점과 에지의 조합을 지정하고 그에 대한 이름을 할당할 수 있습니다. 예를 들어 정점 a 가 에지 ab를 통해 다른 정점 b에 연결되도록 하려면 (a)-[ab]→(b) 로 작성합니다. 괄호 또는 대괄호 안의 이름은 값을 나타내는 게 아니라 결과로 나오는 DataFrame에 존재하는 이름과 일치하는 정점 및 가장자리 컬럼 이름입니다, 결과값 반환 목적이 아니면 이름은 생략해도 됩니다. ((a) - [] → () )
- 세 도착지 간에 삼각형 패턴을 형성하는 모든 자전거를 찾아봅시다. 삼각형 패턴이란 a에서 b로, b에서 c로, c에서 a로 연결되는 에지를 가지는 정점 a,b,c가 있다는 뜻입니다.
1
motifs = stationGraph.find('(a)-[ab]->(b); (b)-[bc]->(c); (c)-[ca]->(a)')
위 코드를 실행하면 정점 a,b,c와 각 에지의 중첩 필드가 포함된 DataFrame 이 생성되고 이제 이 DataFrame에 사용되는 쿼리를 작성할 수 있습니다.
- 특정 자전거를 대상으로 위 삼각형 패턴 중 가장 짧은 경로를 찾아봅시다.
기존의 타임스탬프를 스파크의 타임스탬프로 파싱한 다음 특정 지점에서 다른 지점으로 이동한 자전거가 동일한 것인지, 각 이동을 시작하는 시점이 올바른지 확인하기 위해 비교를 수행합니다.
이때 유의해야 할 점은 모티프 쿼리가 반환한 삼각형(결과값)을 필터링해야 한다는 것입니다. 보통 이러한 쿼리에서는 동일한 정점 ID가 여러 개 있는 경우 하나의 정점 ID로 통합시키지 않으므로, 하나의 정점으로 통합하기 원하면 필터링을 수행해야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
motifs.selectExpr("*",
"to_timestamp(ab.`Start Date`, 'MM/dd/yyyy HH:mm') as abStart",
"to_timestamp(bc.`Start Date`, 'MM/dd/yyyy HH:mm') as bcStart",
"to_timestamp(ca.`Start Date`, 'MM/dd/yyyy HH:mm') as caStart")\
.where("ca.`Bike #` = bc.`Bike #`").where("ab.`Bike #` = bc.`Bike #`")\
.where("a.id != b.id").where("b.id != c.id")\
.where("abStart < bcStart").where("bcStart < caStart")\
.orderBy(F.expr("cast(caStart as long) - cast(abStart as long)"))\
.selectExpr("a.id", "b.id", "c.id", "ab.`Start Date`", "ca.`End Date`")\
.limit(1).show(1, False)
+---------------------------------------+---------------+----------------------------------------+---------------+---------------+
|id |id |id |Start Date |End Date |
+---------------------------------------+---------------+----------------------------------------+---------------+---------------+
|San Francisco Caltrain 2 (330 Townsend)|Townsend at 7th|San Francisco Caltrain (Townsend at 4th)|5/19/2015 16:09|5/19/2015 16:33|
+---------------------------------------+---------------+----------------------------------------+---------------+---------------+
가장 짧은 삼각형 경로는 San Francisco Caltrain 2 → Townsend at 7th → San Francisco Clatrain → San Francisco Caltrain2 순으로 총 22분 정도 걸렸네요. 이렇게 모티프 찾기를 결과 테이블 통해 DataFrame 쿼리와 결합하여 발견된 패턴을 더욱 간결히 하거나 정렬, 집계할 수 있다는 것이 GraphFrame의 가장 강력한 기능이라고 합니다.
그래프 알고리즘
GraphFrame은 현재 여러 그래프 관련 알고리즘을 손쉽게 활용할 수 있도록 지원하고 있습니다. 대부분 알고리즘이 파라미터를 취하는 메서드로 구성되어, 새로운 GraphFrame이나 단일 DataFrame을 반환하는 식입니다.
페이지랭크
그 유명한 구글의 페이지랭크(논문)입니다. 간단히 말하자면 어떤 웹 페이지의 중요성을 판단할 때, 다른 웹 페이지로부터 받는(다른 페이지가 인용한) 링크의 양과 질에 따라서 중요도를 계산하는 알고리즘입니다. 구글의 이 페이지랭크 값에 따라서 검색시 중요한 페이지가 먼저 나열되도록 해왔습니다.
자전거 여행의 경우, 중요한 정류장을 찾는 문제라고 할 수 있겠습니다. 간단히 해 봅니다. 페이지랭크 알고리즘은 GraphFrame을 반환한합니다. 신규 생성되는 pagerank 컬럼으로부터 각 정점에 대한 추정된 페이지랭크 값을 추출할 수 있습니다. 꼭 지정해줘야 하는 파라미터는 두가지인데요, resetProbability 와 maxIter 입니다. 페이지랭크는 랜덤하게 웹서핑을 지속하는 서퍼가 여러 페이지를 임의로 방문하며 탐색하는 모델을 만드는데, 이때 특정 페이지에서 만족하여 탐색을 중단하거나 다음 페이지를 클릭할 텐데, 다음 페이지로 클릭하는 확률을 Damping Factor라고 합니다. 이 Reset probability의 경우 1-DF를 뜻하며, 보통 DF를 0.85로 잡기 때문에 0.15로 설정해 줍니다. maxIter 는 알고리즘이 몇 번 이터레이션을 돌 건지 설정하는 파라미터입니다. 너무 적으면 결과가 안 좋고 너무 크게 하면 성능이 떨어지겠죠?
페이지랭크로 계산한 가장 중요도 높은 정류장 10개
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
ranks = stationGraph.pageRank(resetProbability=0.15, maxIter=10) ranks.vertices.orderBy(F.desc('pagerank')).select('id', 'pagerank').show(10) +--------------------+------------------+ | id| pagerank| +--------------------+------------------+ |San Jose Diridon ...| 4.051504835989959| |San Francisco Cal...|3.3511832964287103| |Mountain View Cal...|2.5143907710155586| |Redwood City Calt...|2.3263087713711696| |San Francisco Cal...| 2.23114429136986| |Harry Bridges Pla...|1.8251120118882906| | 2nd at Townsend| 1.58212177850392| |Santa Clara at Al...|1.5730074084907522| | Townsend at 7th|1.5684565805340673| |Embarcadero at Sa...| 1.541424208774895| +--------------------+------------------+
In-Degree와 Out-Degree 지표 계산
한 정점에 연결된 엣지의 수를 degree라고 할 때, 만약 방향성 있는 그래프라면 이 degree는 in-degree와 out-degree로 나뉩니다. 예컨대 SNS 팔로워를 그래프로 볼 경우, 인이 아웃보다 많다는 것은 팔로잉보다 팔로워가 많다는 것이고, 이 비율이 매우 높을수록 많은 팔로워를 가진 영향력 있는 유저라고 볼 수도 있겠죠.
자전거 여행에서는 주로 도착하는 사람은 많지만 출발하지는 않는 곳(혹은 그 반대)의 정점을 찾아볼 수 있을 것 같습니다. 각 정점의 나가는 수와 들어오는 수를 어떻게 계산할까요?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
inDeg = stationGraph.inDegrees
inDeg.orderBy(F.desc('inDegree')).show(5,False)
+----------------------------------------+--------+
|id |inDegree|
+----------------------------------------+--------+
|San Francisco Caltrain (Townsend at 4th)|34810 |
|San Francisco Caltrain 2 (330 Townsend) |22523 |
|Harry Bridges Plaza (Ferry Building) |17810 |
|2nd at Townsend |15463 |
|Townsend at 7th |15422 |
+----------------------------------------+--------+
outDeg = stationGraph.outDegrees
outDeg.orderBy(F.desc('outDegree')).show(5,False)
+---------------------------------------------+---------+
|id |outDegree|
+---------------------------------------------+---------+
|San Francisco Caltrain (Townsend at 4th) |26304 |
|San Francisco Caltrain 2 (330 Townsend) |21758 |
|Harry Bridges Plaza (Ferry Building) |17255 |
|Temporary Transbay Terminal (Howard at Beale)|14436 |
|Embarcadero at Sansome |14158 |
+---------------------------------------------+---------+
degreeRatio = inDeg.join(outDeg, 'id').selectExpr('id','double(inDegree)/double(outDegree) as degreeRatio')
degreeRatio.orderBy(F.desc('degreeRatio')).show(10,False)
+----------------------------------------+------------------+
|id |degreeRatio |
+----------------------------------------+------------------+
|Redwood City Medical Center |1.5333333333333334|
|San Mateo County Center |1.4724409448818898|
|SJSU 4th at San Carlos |1.3621052631578947|
|San Francisco Caltrain (Townsend at 4th)|1.3233728710462287|
|Washington at Kearny |1.3086466165413533|
|Paseo de San Antonio |1.2535046728971964|
|California Ave Caltrain Station |1.24 |
|Franklin at Maple |1.2345679012345678|
|Embarcadero at Vallejo |1.2201707365495336|
|Market at Sansome |1.2173913043478262|
+----------------------------------------+------------------+
degreeRatio.orderBy('degreeRatio').show(10,False)
+----------------------------------------+------------------+
|id |degreeRatio |
+----------------------------------------+------------------+
|Redwood City Medical Center |1.5333333333333334|
|San Mateo County Center |1.4724409448818898|
|SJSU 4th at San Carlos |1.3621052631578947|
|San Francisco Caltrain (Townsend at 4th)|1.3233728710462287|
|Washington at Kearny |1.3086466165413533|
|Paseo de San Antonio |1.2535046728971964|
|California Ave Caltrain Station |1.24 |
|Franklin at Maple |1.2345679012345678|
|Embarcadero at Vallejo |1.2201707365495336|
|Market at Sansome |1.2173913043478262|
+----------------------------------------+------------------+
너비 우선 탐색
너비 우선 탐색은 그래프의 모든 정점을 순회하는 알고리즘 중 하나로, bfs 메소드를 이용하면 너비 우선 탐색을 통해 서로 다른 지점 간 최단 경로는 무엇일지 찾아볼 수 있습니다. maxPathLength는 최대 에지 수를 지정하며, edgeFilter 를 통해 조건에 맞지 않는 에지를 필터링할 수 있습니다. (ex. 통근시간만 보겠다)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
stationGraph.bfs(fromExpr="id = 'Townsend at 7th'", toExpr="id = 'Spear at Folsom'", maxPathLength =2).show(10)
+--------------------+--------------------+--------------------+
| from| e0| to|
+--------------------+--------------------+--------------------+
|[65, Townsend at ...|[913371, 663, 8/3...|[49, Spear at Fol...|
|[65, Townsend at ...|[913265, 658, 8/3...|[49, Spear at Fol...|
|[65, Townsend at ...|[911919, 722, 8/3...|[49, Spear at Fol...|
|[65, Townsend at ...|[910777, 704, 8/2...|[49, Spear at Fol...|
|[65, Townsend at ...|[908994, 1115, 8/...|[49, Spear at Fol...|
|[65, Townsend at ...|[906912, 892, 8/2...|[49, Spear at Fol...|
|[65, Townsend at ...|[905201, 980, 8/2...|[49, Spear at Fol...|
|[65, Townsend at ...|[904010, 969, 8/2...|[49, Spear at Fol...|
|[65, Townsend at ...|[903375, 850, 8/2...|[49, Spear at Fol...|
|[65, Townsend at ...|[899944, 910, 8/2...|[49, Spear at Fol...|
+--------------------+--------------------+--------------------+
연결 요소 & 강한 연결 요소
연결 요소(Connected component)란 자체적 연결을 가지고 있지만 큰 그래프에는 연결되지 않은(방향성 없는) 서브그래프입니다.
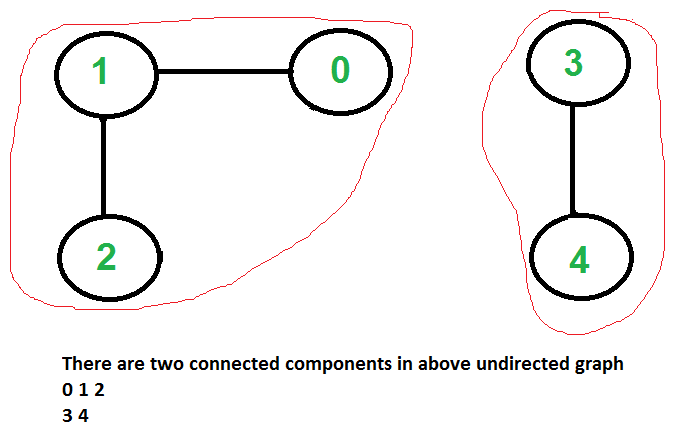
현 데이터에 대해 방향성이 없다고 가정하고 알고리즘을 실행해 봅시다. 연산량이 많기 때문에 체크포인트 디렉터리를 설정하면 좋습니다.
1
2
3
spark.sparkContext.setCheckpointDir('/tmp/checkpoints')
minGraph = GraphFrame(stationVertices, tripEdges.sample(False, 0.1))
cc = minGraph.connectedComponents
강한 연결 요소(Strongly connected components)는 방향성이 고려된 상태로 강하게 연결된 구성 요소, 즉 내부의 모든 정점 쌍 사이에 경로가 존재하는 서브그래프입니다. 아래 그림의 경우 3개의 SCC가 존재합니다.
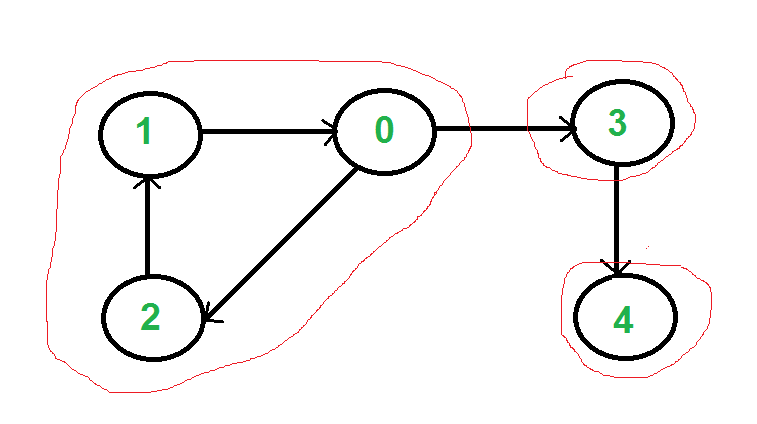
- SCC 찾기
1
2
3
4
5
6
7
8
9
10
11
scc = minGraph.stronglyConnectedComponents(maxIter=3)
scc.groupBy('component').count().show()
+------------+-----+
| component|count|
+------------+-----+
|128849018880| 16|
| 8589934592| 19|
| 0| 33|
| 17179869184| 1|
|317827579904| 1|
+------------+-----+