스파크의 Adaptive Query Execution
Spark 3.0에서 등장한 Adaptive Query Execution에 대해 알아보았습니다. 런타임에서 동작하는 옵티마이저가 어떤 것인지와 주요 3가지 기능, 사용법까지 다룹니다.
스파크의 쿼리 옵티마이저는 다음과 같이 발전해 왔습니다.
- Spark 1.x: rule-based
- Spark 2.x : rule-based & cost-based
- Spark 3.x : rule-based & cost-based & runtime
정해진 규칙들에 해당하는 케이스는 규칙대로 바꿔주는 룰 기반 옵티마이저와는 달리 비용 기반 옵티마이저는 런타임 이전에 다양한 데이터 통계(ex. 행의 개수, 고유 값의 개수, null 값, 최소/최대값 등)를 모아서 스파크가 더 효율적인 실행계획으로 쿼리를 실행하도록 합니다. 예를 들면 어떤 방식의 조인을 실행할지, 여러 개의 조인을 실행할 때 어떤 조인을 먼저 실행하는 게 좋을지 어떤 필터링을 먼저 할지 등을 결정해 줍니다. 다만 이러한 기존 옵티마이저의 단점은 사전 통계치 모으는 데도 비용이 발생하고, 사전이기 때문에 부정확한 추정치로 이어진다는 점, 하드코딩된 힌트 기반으로 작동하여 데이터의 변동을 따라가지 못하는 점 등으로 인해 때때로 최적의 최적화를 하지 못할 수도 있다는 것입니다.
이번 글의 주제는 Spark 3.0에서 새로 등장한 런타임 통계 기반의 옵티마이저인 적응적 쿼리 실행(Adaptive Query Execution, AQE)입니다.
런타임에서 최적화한다는 것은?
일반적으로 스파크에서 쿼리가 실행될 때, 셔플 또는 브로드캐스트 교환을 기준으로 쿼리 스테이지가 쪼개지고 스테이지 내부에서 병렬 실행을 합니다. 예를 들어 다음과 같은 쿼리를 실행하면 이렇게 셔플 직전에 파이프라인이 잠시 끊기는 구간이 생기죠. 이 구간을 materialization point (그림상 pipeline break point) 라고 부릅니다. 이전 스테이지의 모든 병렬 실행이 끝나야 다음 스테이지로 넘어가고요.
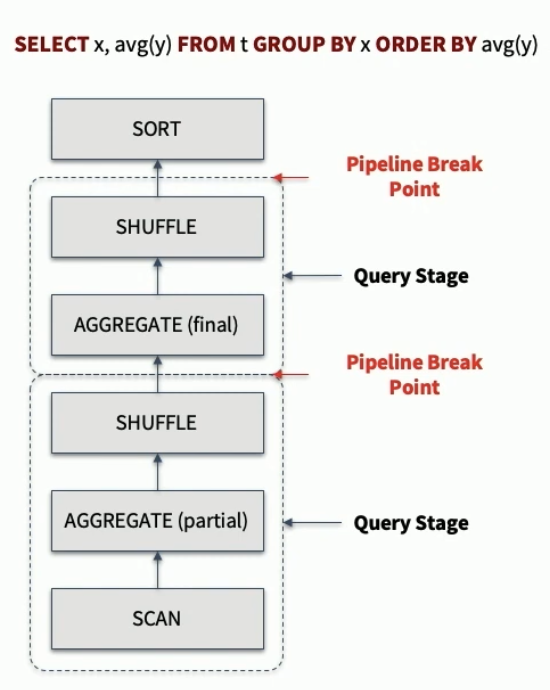
AQE는 이 break point에서 재최적화(re-potimization)을 하는 방식으로 동작합니다. 처음 이 중간에 끊기는 지점에 중간중간 데이터와 파티션에 대한 통계를 내서, 다음 스테이지를 시작하기 전에 이 값들을 가지고 처음 만들었던 논리적 실행계획을 더 좋은 성능을 내는 방향으로 변경해주는 것입니다.
이제 AQE가 어떤 단계에서 동작하는지 알았으니 상세하게 어떤 방식으로 최적화를 해주는지 살펴봅시다. AQE가 제공하는 주요 기능은 다음 세 가지입니다.
1. 셔플 파티션의 동적 통합 (Dynamically coalescing shuffle partitions)
셔플은 비용이 많이 들어가고, 따라서 셔플이 많이 발생하면 쿼리 성능이 떨어집니다. 셔플에서 고려해야 할 중요한 요소 중 하나는 바로 셔플 파티션의 수입니다. 셔플 파티션 수가 너무 적으면, 각 파티션에 들어가는 데이터 크기가 커져 ram이 아닌 디스크를 사용해 연산을 하게 되어 성능이 떨어집니다. 반면 파티션 수가 너무 많으면(크기가 작으면) 비효율적인 I/O로 속도가 저하될 수 있고, 수많은 파티션을 스케줄링하고 태스크 설정하는 데서 오버헤드가 발생할 수 있습니다.
이전까지는 전체 쿼리 실행해서 정해진 정적의 파티션 설정이 있는 상황에서, 최적화된 실행을 위해 사용자가 통계치를 보고 적절한 파티션의 수를 지정하여 통합, 데이터를 재분배해야 하는 경우가 있었습니다. 또한 데이터 크기는 그때그때 바뀔 수도 있는 상황에서 사전 지정은 그 변화에 대응하지 못하는 문제가 있죠.
AQE는 런타임에 각 스테이지가 끝날 때마다 셔플 통계치를 보고 아래와 같이 너무 많은 작은 파티션이 있으면 적절하게 합쳐주어 비슷한 크기의 파티션들로 만들어줍니다.
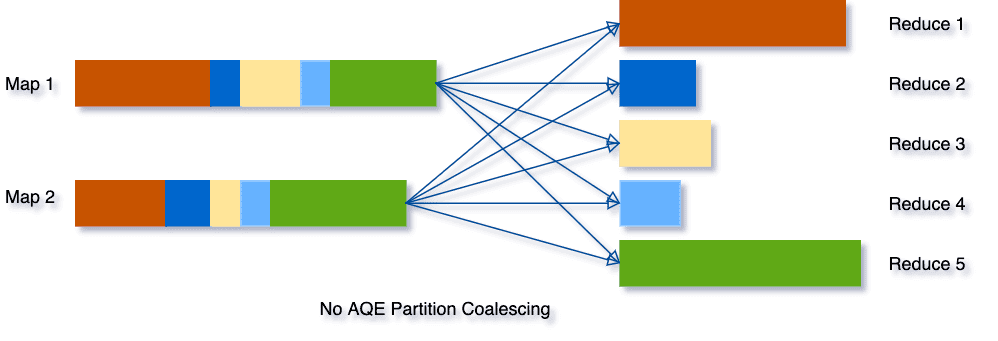

2. 조인 전략의 동적 전환 (Dynamically switching join strategies
스파크는 다양한 조인 전략을 지원하는데, 조인 방식마다 드는 비용에는 차이가 있습니다. 예를 들어 브로드캐스트 해시 조인은 디멘션 테이블처럼 작은 테이블을 익스큐더 노드로 통째로 복사해서 셔플 없이 각 파티션 내에서 조인을 진행하는 것으로, 만약 한쪽의 크기가 하드코딩된 특정 크기보다 작다면 성능 면에서 브로드캐스트 해시 조인이 더 좋은 선택입니다. 포인트는 이걸 쓰려면 한쪽 테이블이 작아야 한다는 것인데요.
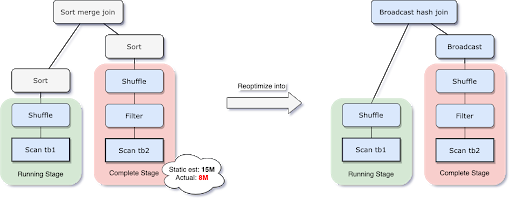
AQE는 아래와 같이 처음의 실행계획은 특정 데이터가 클 것이라고 예측해서 sort merge join이었더라도 이후 런타임 중에 보니 충분히 작아서 브로드캐스트 해시 조인이 더 낫다고 판단된다면, 재최적화시 조인 전략을 바꿔줌으로써 최적화된 실행을 해줍니다.
3. 편향된 조인의 동적 최적화 (Dynamically optimizing skew joins)
파티션 하나에 데이터가 몰려있는 경우를 편향되어있다(skewness가 발생했다)라고 합니다. skew된 상태에서 수행하는 셔플은 심각한 속도 저하로 이어질 수 있습니다. 앞서 언급했듯이 스파크는 스테이지 내부에서 병렬 처리를 하고 다 끝나야 다음으로 때문에, 모든 선수가 다 돌아와야 다음 라운드를 뛰는 상황에서 한 명만 거리가 엄청나게 먼 곳에 떨어진 상황인 거죠.
AQE는 이처럼 데이터가 일부 파티션에 편향되어 있는 상황에서 아래와 같이 적절하게 해결해줍니다.
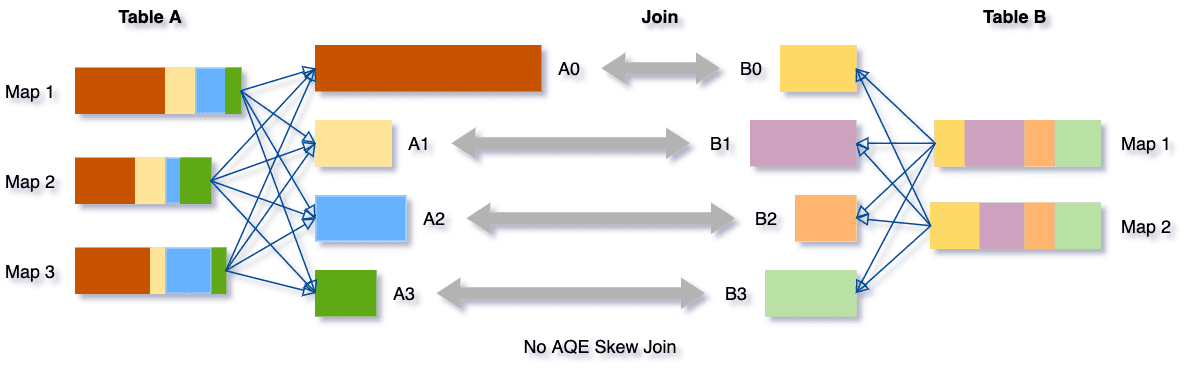
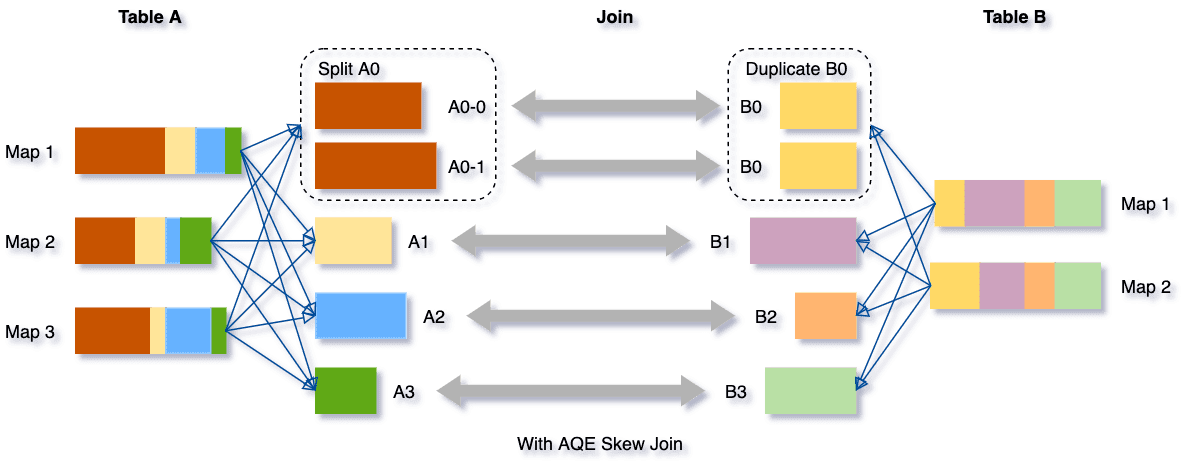
A와 B를 조인하는 상황에서 뭘 했냐면, 가장 데이터가 쏠려 있는 A0을 두 개의 파티션(A0-0, A0-1)으로 나누고, 각자와 조인할 수 있도록 B0을 2개로 복붙해주었습니다. 이렇게 하면 처리 속도를 크게 향상시킬 수 있습니다. 저도 코드 수준의 성능 향상(주로 skewness 해결법) 팁들을 찾아보고 이 글로 정리해둔 적 있는데요. 재파티셔닝이나 salting, 적절한 조인 고르기 등 성능을 위해 고민해야 했던 것들이 무색해지게 하는 그런 기능으로 보이네요.
그래서 얼마나 도움이 될까?
TPC-DS의 벤치마크 데이터셋과 쿼리를 사용해서 비교했을 때, AQE는 최대 8배까지 속도 차이가 났고, 32개의 쿼리는 10% 이상의 속도 개선이 있었다고 합니다(전체가 몇 갠지 몰라서 찾아보니 TPC-DS는 총 99개 쿼리를 제공한다고). 아래는 가장 속도 차이가 많이 났던 10개의 쿼리의 처리시간을 비교한 그림입니다.
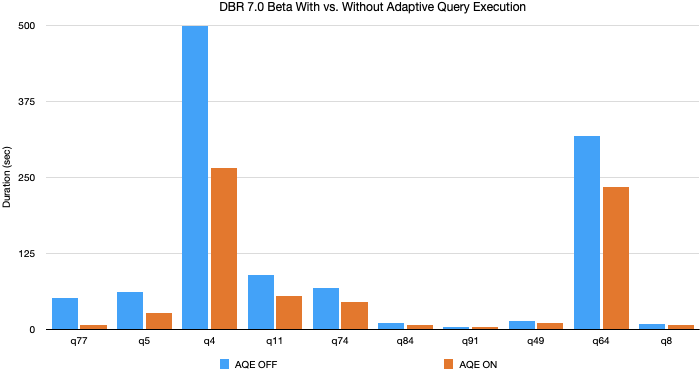
다만 TPC-DS 데이터는 다 랜덤하게 생성된 거라서 보통 skew되지 않았기 때문에, 이 성능 향상은 대부분 3개 기능 중 1,2번으로 비롯된 것이라고 합니다. 따라서 skewness가 있는 일반적인 데이터에 적용하면 더 큰 성능 향상을 기대할 수 있을 거라고 하네요.
사용법
다음과 같이 Spark 3.x에서 AQE를 활성화할 수 있습니다. 스트리밍 쿼리가 아니고, 1개 이상의 exchange가 발생하거나(조인, aggregation, window 등 포함) 서브쿼리가 포함되는 쿼리일 때 적용되게 됩니다.
1
spark.conf.set("spark.sql.adaptive.enabled",true)
3개 기능 각 설정의 경우,
spark.sql.adaptive.coalescePartitions.enabledspark.sql.adaptive.autoBroadcastJoinThresholdspark.sql.adaptive.skewJoin.enabled
보다 자세한 설정은 공식 문서에서 확인할 수 있습니다.