ML 코드로 배워보는 SOLID 원칙
객체 지향 설계의 5가지 원칙을 데이터쟁이가 알아들을 수 있는 예시를 통해 공부해본 내용입니다.
주피터 노트북 좋아하세요?

주피터 노트북은 데이터 분석이나 ML 모델 개발을 하는 사람에게 매우 편리한 도구입니다. 일반적인 소프트웨어 개발에 비해 분석이나 모델 개발을 할 때는 실험이 작업의 많은 비중을 차지하거든요. 따라서 코드를 작성할 때도 전체적인 구조나 설계는 솔직히 알 바 아니고 빨리 돌려서 이거 분포 어떤지 확인해야지! 정확도 몇 나오는지 찍어봐야지! 하는 게 우리 모두의 마음입니다. 그러니 셀 단위로 실행하고 바로바로 결과를 볼 수 있는 주피터 노트북이 얼마나 적절하고 편한 선택지인지 굳이 설명할 필요는 없을 것입니다. 이 글을 읽는 분들 중 함수가 무서운 분들은 아마 없겠지만 사실 함수가 무서워서라기보다는 정말 “편한 대로” 쓰다 보니까 모듈화 전혀 없이 주루룩 그냥 일필휘지로 써내려가게 됩니다.
하지만 일회성의 Ad-hoc 분석이나 모델 프로토타이핑 단계가 지나고 뭔가 프로덕션에 올려야 하는 단계가 되면, 주피터 노트북은 만악의 근원이 되곤 합니다. 하나의 노트북에 데이터 전처리부터 모델 학습, 추론이나 데이터 적재까지 한방에 때려넣은(이런 걸 조금 어려운 말로 monolithic 하다고 하더군요) 코드를 보고 있으면 정말 두통이 밀려옵니다. 가끔 옆동네 개발자 분들이 이런 코드를 보고 경악의 표정을 애써 숨기시는 재미있는 광경도 볼 수 있습니다. 구체적으로 이런 코드의 문제점은 한두 가지가 아닌데,
- 디버깅, 유지보수가 어려움 (셀 89개 와다다 있는 노트북을 보신 적이 있습니까? 솔직히 남의 코드는커녕 과거의 내가 썼어도 뭐가 뭔지 어디가 어딘지 알 도리가 없음)
- 버전 관리와 협업이 어려움 (수정된 부분 비교하기가 어렵고 특히 출력 결과가 포함되기 때문에 파일이 달라지기도 함)
- 재사용과 확장이 어려움 (코드의 어떤 부분이 어떤 기능을 하는지 분리되어 있지 않고 같은 로직을 계속 반복해서 작성하기도 함. 특정 기능을 고치고 싶어도 불가능)
따라서 아무리 실험은 주피터 노트북에서 하더라도 프로덕션 단계에서는 적절한 수준의 모듈화와 스크립트 작성이 필요하겠습니다. 그때 참고할 수 있는 것이 객체 지향 프로그래밍(OOP)에서 바람직한 설계 원칙으로 알려진 SOLID 원칙입니다. SOLID 원칙은 5가지로 이루어져 있으며 SOLID라는 이름은 그 5개의 머릿글자를 따서 만들어졌습니다. 굉장히 오래된 내용이기 때문에 검색해보면 자료가 넘쳐나지만 아무래도 말도 좀 어렵고 예시는 와닿지 않는 경우가 많아서, 오늘은 저에게 쉬운 예시로 한번 이해해보려고 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 데이터 불러오기
penguins = sns.load_dataset("penguins")
# 데이터 전처리
penguins.dropna(inplace=True)
le = LabelEncoder()
penguins['species'] = le.fit_transform(penguins['species'])
penguins['sex'] = le.fit_transform(penguins['sex'])
penguins['island'] = le.fit_transform(penguins['island'])
X = penguins.drop(columns=['species'])
y = penguins['species']
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습 및 평가
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# 시각화
plt.figure(figsize=(8, 6))
sns.scatterplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="species")
plt.title("Penguin Species based on Bill Length and Depth")
plt.show()
위 코드는 펭귄 데이터를 불러와서 종 분류를 하는 내용으로 굳이 자세히 안 읽어봐도 머신러닝의 ABC같은 그런 내용이죠. 앞에 말씀 드렸던 전형적인 ‘주피터 노트북 식’ 코드이기도 하고요. 이제 SOLID 원칙에 따라서 위 코드를 한번 고쳐보겠습니다.
📍 시작 전 잠깐 disclaimer
- 고친 버전의 코드들이 “이렇게 코드를 작성하는 게 무조건 좋다”는 의미인가 하면 그건 절대 아니고요(그렇게 고민하면서 잘 쓰여진 코드는 아니고 실제상황이라면 제가 썼었을 방식이랑 동떨어진 경우도 있습니다), SOLID 원칙을 데이터 분석과 모델링을 주로 하시는 분들에게 익숙한 언어로 한번 이해해 보기 위한 예제로 봐주세요.
- ML 프로젝트에서 이 모든 것을 반드시 꼭 지켜야한다기보다는 프로덕션 코드를 작업할 때 지향할 수 있는 일종의 방향성이라고 생각합니다.
Single Responsibility Principle
하나의 클래스는 하나의 책임만 가져야 한다.
책임이 뭔데? 싶었지만 그냥 ‘기능’이라는 말로 이해해도 좋을 것 같습니다. 즉 각 클래스는 하나의 기능을 수행하는 데 집중하며, 따라서 변경할 때도 단순히 그 기능에 대한 수정사항이 있을 때 (하나의 이유로) 변경되어야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
class DataLoader:
def load_data():
return sns.load_dataset("penguins")
class DataPreprocessor:
def preprocess_data(df):
df.dropna(inplace=True)
le = LabelEncoder()
df['species'] = le.fit_transform(df['species'])
df['sex'] = le.fit_transform(df['sex'])
df['island'] = le.fit_transform(df['island'])
X = df.drop(columns=['species'])
y = df['species']
return X, y
class ModelTrainer:
def __init__(self, model):
self.model = model
def train(self, X_train, y_train):
self.model.fit(X_train, y_train)
def predict(self, X_test):
return self.model.predict(X_test)
def evaluate(self, y_test, y_pred):
return accuracy_score(y_test, y_pred)
class DataVisualizer:
def visualize(df):
plt.figure(figsize=(8, 6))
sns.scatterplot(data=df, x="bill_length_mm", y="bill_depth_mm", hue="species")
plt.title("Penguin Species based on Bill Length and Depth")
plt.show()
if __name__ == "__main__":
data = DataLoader.load_data()
X, y = DataPreprocessor.preprocess_data(data)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestClassifier(n_estimators=100, random_state=42)
trainer = ModelTrainer(model)
trainer.train(X_train, y_train)
y_pred = trainer.predict(X_test)
accuracy = trainer.evaluate(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
DataVisualizer.visualize(data)
일단 우리의 원래 코드에는 클래스라는 게 존재하지조차 않았으므로 코드의 각 기능을 세분화하여 담당하는 클래스를 하나씩 만들어봤습니다.
- 데이터를 불러오는 DataLoader 클래스
- 데이터 전처리를 담당하는 DataPreprocessor 클래스
- 모델 학습, 예측, 평가를 담당하는 ModelTrainer 클래스
- 데이터 시각화를 담당하는 DataVisualizer 클래스
이제 각 클래스가 하나의 역할만 수행하도록 해서, 만약 시각화에 대해 변경하고 싶은 내용이 생겼다면 DataVisualizer만 고치면 된다! 라는 걸 알 수 있습니다.
Open-Closed Principle
소프트웨어 요소(클래스, 모듈, 함수 등)는 확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다.
무슨 열림교회닫힘이야? 가 아니고, ‘변경을 하지 말고’ 확장할 수 있어야 한다는 뜻입니다. 즉, 새로운 기능이 추가될 때 기존에 있던 코드를 고치지 않고도 확장할 수 있는 방식으로 구현되어야 합니다. 어떻게 하냐면, 추상화된 인터페이스와 상속을 이용하면 됩니다.
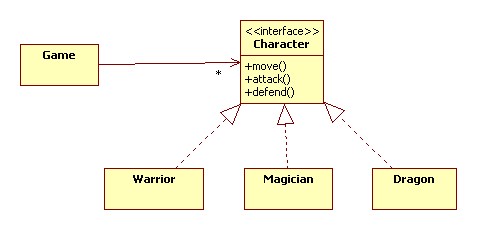
객체 지향 프로그래밍(OOP)의 핵심적인 개념을 간단하게만 짚고 넘어가겠습니다. 예를 들어 게임 내에 법사, 전사 등 여러 캐릭터가 존재합니다. 법사는 공격할 때 지팡이를 휘두르고 전사는 검을 휘두르니까 각각의 세부적인 동작은 다르지만 어쨌든 공격할 수 있는 기능이 있어야 한다는 건 동일하겠죠. 따라서 일단 ‘캐릭터’라는 상위의 추상적인 인터페이스를 만들어서 그 안에 움직임, 공격, 방어와 같은 기본적인 기능들의 틀을 잡아놓습니다. 그 다음에 법사와 전사 클래스는 이 캐릭터 인터페이스를 상속 받아서 그 안에서 세부적으로 달라지는 동작들은 각각 구현합니다. 이런 것을 다형성(Polymorphism) 이라고도 부르는데, 이렇게 하면 여러 클래스를 동일한 인터페이스로 처리하면서도 새로운 클래스에 대해 유연하게 확장할 수 있다는 장점이 있습니다. 그러니까 드래곤이라는 새로운 유형이 나왔을 때도 우리는 뭔가를 처음부터 새로 만들거나 기존의 캐릭터 인터페이스를 뜯어고치는 게 아니고 이걸 상속받아서 ‘불뿜기 공격’ 같은 기능을 새로 구현하면 되는 거죠. 결론적으로 OCP는 다형성을 최대한 이용하라는 원칙이 되겠습니다.
다시 우리의 예제로 돌아가면,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
from abc import ABC, abstractmethod
class BaseModel(ABC):
@abstractmethod
def train(self, X_train, y_train):
pass
@abstractmethod
def predict(self, X_test):
pass
@abstractmethod
def evaluate(self, y_test, y_pred):
pass
class RandomForestTrainer(BaseModel):
def __init__(self, n_estimators=100, random_state=42):
self.model = RandomForestClassifier(n_estimators=n_estimators, random_state=random_state)
def train(self, X_train, y_train):
self.model.fit(X_train, y_train)
def predict(self, X_test):
return self.model.predict(X_test)
def evaluate(self, y_test, y_pred):
return accuracy_score(y_test, y_pred)
class GradientBoostingTrainer(BaseModel):
def __init__(self, learning_rate=0.1, n_estimators=100, random_state=42):
self.model = GradientBoostingClassifier(learning_rate=learning_rate, n_estimators=n_estimators, random_state=random_state)
def train(self, X_train, y_train):
self.model.fit(X_train, y_train)
def predict(self, X_test):
return self.model.predict(X_test)
def evaluate(self, y_test, y_pred):
return accuracy_score(y_test, y_pred)
우선 ABC는 추상 클래스와 메서드를 정의하기 위해 사용하는 라이브러리입니다. 추상 클래스는 인스턴스를 실제로 생성하기 위해서가 아니라 이 클래스를 상속하는 다른 클래스들이 어떤 메소드와 속성을 가져야 하는가? 라는 인터페이스를 정의하기 위해서 만듭니다. 앞서 예시에서 ‘캐릭터’ 클래스 같은 거죠. @abstractmethod라는 데코레이터는 뭐냐면 이 추상 클래스를 상속받는 클래스들이 반드시 이 메소드는 구현해야 한다! 라는 의미입니다.
여기서 우리는 BaseModel이라는 추상 클래스를 만들었고, 사용할 실제 모델은 이 클래스를 상속받아서 동작하도록 했습니다. 단 상속받을 때는 train, predict, evaluate을 필수적인 기능으로 구현해야 합니다. 이제 RandomForest 말고 GBT라는 다른 모델을 써볼래 라는 생각이 들면, BaseModel을 고치는 게 아니라 이걸 상속 받아서 사용하면 됩니다(확장).
Liskov Substitution Principle
하위 클래스는 상위 클래스를 대체할 수 있어야 한다.
개인적으로 처음에 좀 이해가 안 갔던 말입니다. 이 문장을 읽으면 아니 왜 하위 클래스가 상위 클래스를 대체해야 하는데? (하위클래스별로 세분화된 작업을 하려고 상속해서 오버라이딩한 거 아닌가?) 라는 생각이 드는데, 이 문장은 사실 실제로 대체를 하라는 말이 아니라 대체할 수 ‘있게끔’ 올바른 상속 관계를 설계하라는 말에 가까운 것 같습니다. 원래 이 원칙의 출발점을 따라가보면, “T타입의 객체에 대해 성립하는 속성은 T의 서브타입 S의 객체에서도 성립해야 한다.”라는 문장이 나옵니다. 즉 상위 클래스에서 성립하는 속성이 하위 클래스에서도 똑같이 성립해야 하기 때문에, 이 원칙은 상위 클래스를 사용하는 코드에서 그걸 하위 클래스로 바꿔도 오작동하면 안 된다 (오작동하면 올바르게 성립하는 상속관계가 아니다) 라는 의미입니다.
 LSP 검색하면 나오는 고전짤 (그림 출처)
LSP 검색하면 나오는 고전짤 (그림 출처)
오리의 생김새와 소리까지 따라서 장난감 오리를 만들었는데, 문제는 오리를 내려놓으면 뒤뚱뒤뚱 걷지만 장난감 오리는 배터리가 없으면 안 움직입니다. 따라서 오리와 같은 상황(상위 클래스를 사용한 코드)에 장난감 오리(하위 클래스)를 놓았을 때 오작동하는 상황이고 LSP 위반인 거죠. 이런 경우 어떻게 해야 할까요? 배터리 없이 움직이게 하는 게 가능하다면 (하위 클래스를 상위 클래스 속성에 맞춰 재작성) 하면 되는데 보통 그렇진 않으니까, 이 장난감 오리를 오리의 하위 클래스가 아닌 장난감의 하위 클래스로 변경함으로써 LSP를 지킬 수 있습니다.
이제 우리 원래 예시로 돌아가보면, 이번엔 모델 부분이 아닌 데이터 전처리하는 부분을 건드려보도록 하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class DataPreprocessor(ABC):
def __init__(self, df: pd.DataFrame):
self.df = df
@abstractmethod
def preprocess(self) -> pd.DataFrame:
"""전처리 실행"""
pass
class NumericPreprocessor(DataPreprocessor):
def preprocess(self) -> pd.DataFrame:
scaler = StandardScaler()
numeric_columns = self.df.select_dtypes(include=["number"]).columns
self.df[numeric_columns] = scaler.fit_transform(self.df[numeric_columns])
return self.df
class CategoryPreprocessor(DataPreprocessor):
def preprocess(self) -> pd.DataFrame:
encoder = OneHotEncoder(sparse=False)
categorical_columns = self.df.select_dtypes(include=["object"]).columns
if categorical_columns.empty:
return self.df
transformed = encoder.fit_transform(self.df[categorical_columns])
column_names = encoder.get_feature_names_out(categorical_columns)
encoded_df = pd.DataFrame(transformed, columns=column_names, index=self.df.index)
self.df = self.df.drop(columns=categorical_columns).reset_index(drop=True)
encoded_df = encoded_df.reset_index(drop=True)
return pd.concat([self.df, encoded_df], axis=1)
class TrainTestSplitter(DataPreprocessor):
def preprocess(self) -> tuple[pd.DataFrame, pd.DataFrame]:
train_df, test_df = train_test_split(self.df, test_size=0.2, random_state=42)
return train_df, test_df
칼럼명이 하드코딩되어 있던 원래 클래스에서, SRS와 OCP를 생각하면서 DataPreprocessor라는 상위 인터페이스를 만든 후 이를 상속하여 각각 수치형/카테고리형 칼럼을 전처리하는 기능을 만들었습니다. 데이터 전처리의 마지막 단계는 학습 데이터와 테스트 데이터로 분할하는 것인데요, 다만 이 기능을 하는 클래스를 DataPreprocessor를 상속하도록 할 경우 LSP를 위반하는 것이 됩니다. DataPreprocessor처럼 전처리된 pandas dataframe을 반환하는 것이 아닌 분할된 데이터로 이루어진 튜플을 반환하고 있기 때문에, (저렇게 했을 때 실행이 안 되는 것은 아닙니다만) 상위 클래스를 대체할 수 없는 하위 클래스로 잘못된 상속 설계라고 볼 수 있는 것이죠.
Interface Segregation Principle
클라이언트는 자신이 사용하지 않는 인터페이스에 의존하지 않아야 한다.
이 원칙은 인터페이스를 가능한 한 작고 구체적으로 분리해서 설계하며, 꼭 필요한(실제로 사용하는) 메서드만 포함하도록 해야 한다는 것입니다.
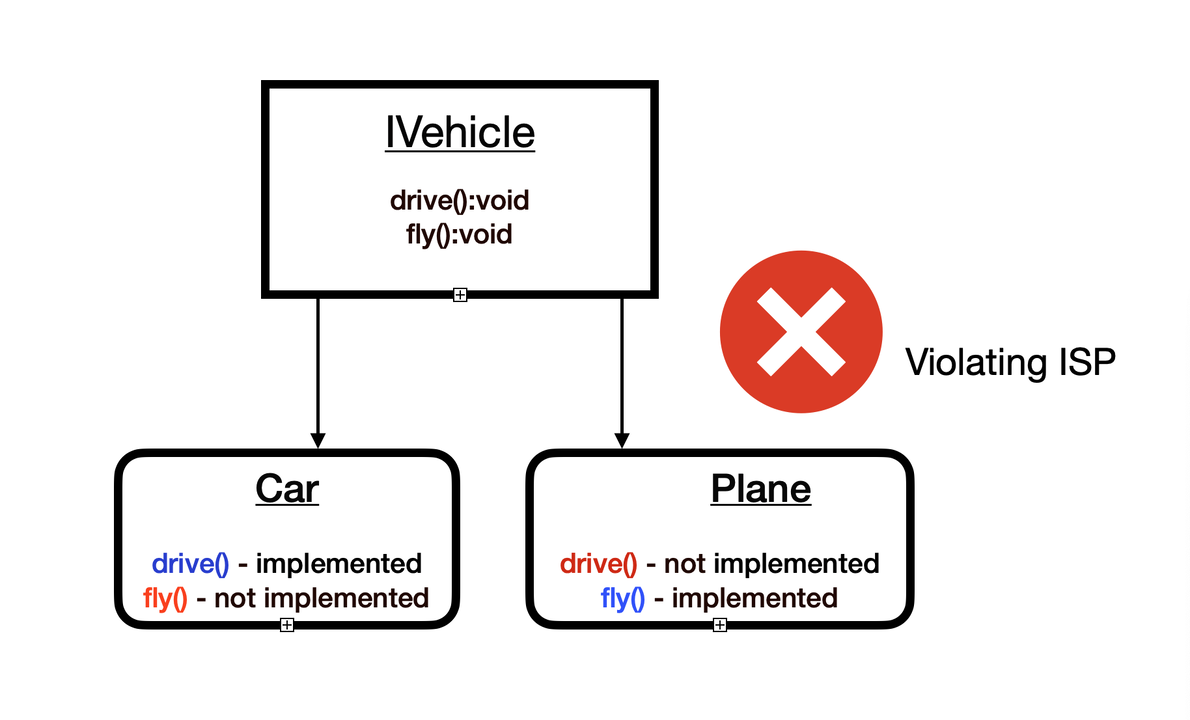 상위 클래스 인터페이스가 2개의 기능을 포함하고 있지만 사실 각각의 하위 클래스 입장에서 둘 중 하나는 필요가 없는 경우 (그림 출처)
상위 클래스 인터페이스가 2개의 기능을 포함하고 있지만 사실 각각의 하위 클래스 입장에서 둘 중 하나는 필요가 없는 경우 (그림 출처)
이 원칙은 매우 간단명료하므로 추가적인 설명 없이 예시로 넘어가봅시다. OCP 단계에서 우리는 BaseModel을 만들었고, 이 클래스는 학습(train), 예측(predict), 평가(evaluate)를 한꺼번에 들고 있었습니다. 하지만 생각해보면 모든 케이스에서 이 3가지 기능이 꼭 필요한 건 아닐 수 있습니다. 펭귄 데이터셋에서는 좀 벗어난 이야기이겠습니다만 이미 사전에 학습된 모델을 불러와서 예측만 수행하고 싶을 때도 있고, 일종의 feature extractor처럼 예측 없이 그냥 학습 후 학습된 벡터만 추출하고 싶을 때도 있죠. 그리고 Online learning 중인 상황이면 평가 기능이 딱히 필요하지 않겠고요.
이를 고려해서, 3개의 인터페이스를 한번 분리해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Trainable(ABC):
@abstractmethod
def train(self, X_train, y_train):
pass
class Predictable(ABC):
@abstractmethod
def predict(self, X_test):
pass
class Evaluable(ABC):
@abstractmethod
def evaluate(self, y_test, y_pred):
pass
이렇게 3개의 인터페이스로 분리가 되면 다음과 같이 케이스별로 필요한 기능만 골라서 구현할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class RandomForestTrainer(Trainable, Predictable, Evaluable):
def __init__(self, n_estimators=100, random_state=42):
self.model = RandomForestClassifier(n_estimators=n_estimators, random_state=random_state)
def train(self, X_train, y_train):
self.model.fit(X_train, y_train)
def predict(self, X_test):
return self.model.predict(X_test)
def evaluate(self, y_test, y_pred):
return accuracy_score(y_test, y_pred)
class PretrainedModel(Predictable):
def __init__(self, model_path):
self.model = joblib.load(model_path)
def predict(self, X_test):
return self.model.predict(X_test)
class FeatureExtractor(Trainable):
def __init__(self, n_components=1):
self.model = PCA(n_components=n_components)
def train(self, X_train):
self.model.fit(X_train)
def extract_features(self, X):
return self.model.transform(X)
Dependency Inversion Principle
고수준 모듈은 저수준 모듈에 의존하면 안 되며, 둘 다 추상화에 의존해야 한다.
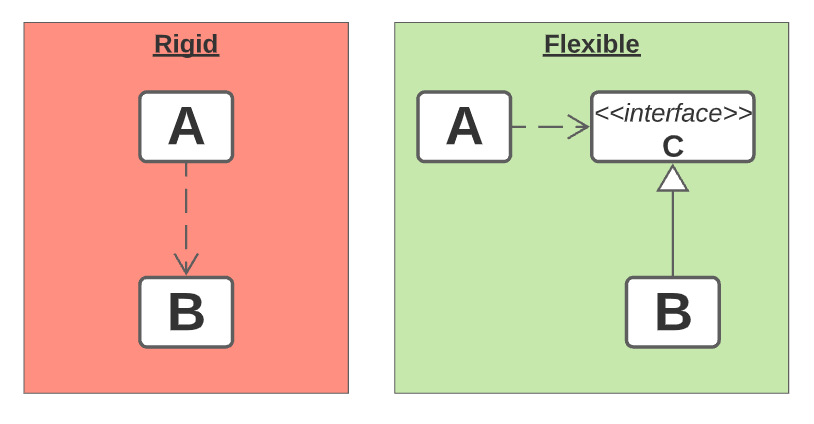
일단 고수준 모듈은 뭐고 저수준 모듈은 뭘까요? 고수준 모듈(A)은 중요한 비즈니스 로직을 실행하는 클래스이고, 저수준 모듈(B)은 세부적이고 구체적인 기능을 수행하는 클래스로서 이 고수준 모듈에서 호출해서 사용하는 대상입니다. 그리고 DIP는 A가 B에 직접적으로 의존하기보다는 중간에 추상화된 인터페이스 C가 껴 있어야 한다는 원칙입니다. 주입(Inversion)이라는 말은 고수준 모듈이 저수준 모듈을 외부에서 주입받는다는 의미로 이해하면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class MargheritaPizza:
def prepare(self):
print("🍅🌿🧀")
def bake(self):
print("🔥")
def serve(self):
print("🍕")
class PizzaSell:
def __init__(self):
self.pizza = MargheritaPizza()
def order_pizza(self):
self.pizza.prepare()
self.pizza.bake()
self.pizza.serve()
위 예시에서 개별 피자는 저수준 모듈이고, 피자판매는 고수준 모듈입니다. 하지만 위 코드처럼 고수준 모듈에서 특정 저수준 모듈에 의존하게 되면, 새로운 피자를 메뉴에 추가할 때마다 클래스를 수정해야 합니다(OCP도 위반이죠).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class Pizza(ABC):
@abstractmethod
def prepare(self):
pass
@abstractmethod
def bake(self):
pass
@abstractmethod
def serve(self):
pass
class HawaiianPizza(Pizza):
def prepare(self):
print("🍍🍖🧀")
def bake(self):
print("🔥")
def serve(self):
print("🍕")
class PizzaSell:
def __init__(self, pizza: Pizza):
self.pizza = pizza
def order_pizza(self):
self.pizza.prepare()
self.pizza.bake()
self.pizza.serve()
margherita_sell = PizzaSell(MargheritaPizza())
pepperoni_sell = PizzaSell(HawaiianPizza())
위 코드의 경우, 고수준 모듈에서 개별 피자에 의존하는 것이 아닌 Pizza라는 추상화된 인터페이스에 의존함으로써 새로운 피자 추가에 대한 확장성과 유지보수 용이성을 확보하고 있습니다.
다시 원래의 예시로 돌아가서 데이터 전처리 부분을 보면, 우리는 DataPreprocessor 라는 추상 인터페이스까지만 만든 상황이었습니다. 기존에 만든 DataPreprocessor와 Numeric/CategoricalPreprocessor는 그대로 두고, 다음과 같이 고수준 모듈을 추가해볼 수 있겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
class PreprocessingPipeline:
def __init__(self, preprocessors: list[DataPreprocessor]):
self.preprocessors = preprocessors
def run(self) -> pd.DataFrame:
processed_df = self.preprocessors[0].df
for preprocessor in self.preprocessors:
processed_df = preprocessor.preprocess()
return processed_df
pipeline = PreprocessingPipeline([NumericPreprocessor(df), CategoryPreprocessor(df)])
processed_df = pipeline.run()
pipeline이라는 고수준 모듈이 일련의 DataPreprocessor 타입의 저수준 모듈을 주입받아서 작동하고 있으며, 기존에 구현된 수치형 스케일러나 카테고리형 인코더 외의 어떤 다른 작용을 하는 전처리 클래스가 추가된다고 해도 유연하게(기존 코드의 수정 없이) 확장 가능하게 됩니다.