LLM 시대의 추천 시스템
Recommender Systems in the Era of Large Language Models 을 읽어 보았습니다.
LLM의 시대에 모든 것에 LLM을 붙이는 경향도 없잖아 있지만 추천 시스템은 가장 자연스러운 확장을 만들어낼 수 있는 영역 중 하나입니다. 추천 모델이 실험실을 떠나서 실제 서비스에 적용될 때는 정적인 예측의 정확도만 중요한 것은 아니기 때문입니다. 사용자와의 상호작용, 의도와 맥락 이해, 근거 설명까지 가능한 Agent 라는 건 어떻게 보면 추천 시스템의 궁극적인 지향점입니다. 이전의 추천이 냅다 사용자에게 너 여기 가면 좋아할 것 같아! (아니면 말고) 하고 던지고 끝나는 방식이었다면, 앞으로의 추천 시스템은 “휴양지 느낌인데 밤에는 좀 도시 같고 한국인 너무 많지 않은 데 여행 가고 싶다” 정도의 모호한 요청에 대해서도 능동적으로 추가 질문을 던져서 사용자의 니즈를 탐색하고 맞춤형 제안을 단계적으로 줄 수 있기를 기대하는 거죠. 그건 아직 좀 멀리 있는 목표 같긴 하지만 어쨌든 최근에 추천 시스템과 LLM은 여러 방향에서 만남을 지속하고 있는데, 한번 개괄적으로 어떤 접근들이 있어 왔는지 보고 싶어서 오랜만에 서베이 논문 을 하나 읽어봤습니다. 주목받는 주제라 심지어 서베이 논문도 여러 편이 있었지만 오늘 골라온 녀석의 구성이 가장 파악이 쉬웠습니다. 거두절미하고 내용 자세히 보겠습니다.
LLM+Recsys
당연히 서론은 추천 시스템에 LLM이 왜 필요하냐? 에 대한 내용입니다. 역사적으로 추천 시스템은 초기의 협업 필터링 방식에서부터 비교적 최근의 딥러닝 기반 모델로 발전했죠. 어떤 방식을 쓰든 추천은 기본적으로 사용자와 아이템 간의 상호작용을 효과적으로 학습하는 것이 핵심이고, 딥러닝(CNN, RNN, GNN 등등) 모델들도 이 역할을 잘 수행하는 편이었으나 이 논문의 서론에서 요약하는 다음과 같은 한계들이 있었습니다.
- 자연어 이해, 텍스트를 포함한 복합적인 맥락 이해가 제한적임
- 특정 과제에 맞춰서 학습되어 일반화 능력이 제한되어 있음
- 예 - 영화 평점 예측에 맞춰서 학습되어 있지만 특정 설명에 맞춘 상위 k개 영화 추천 수행에는 어려움을 겪음(특정한 시나리오에 집중하여/도메인에 크게 의존해서 개발되기 때문)
- 여러 추론 단계를 거쳐야 하는 복잡한 다단계 결정 지원에는 어려움을 겪음
- 예- 여행 계획 추천 (목적지를 기반으로 인기 관광지를 고려하고, 다음 관광지에 해당하는 일정을 마련하고, 사용자 선호도와 비용에 맞춰 추천하기)
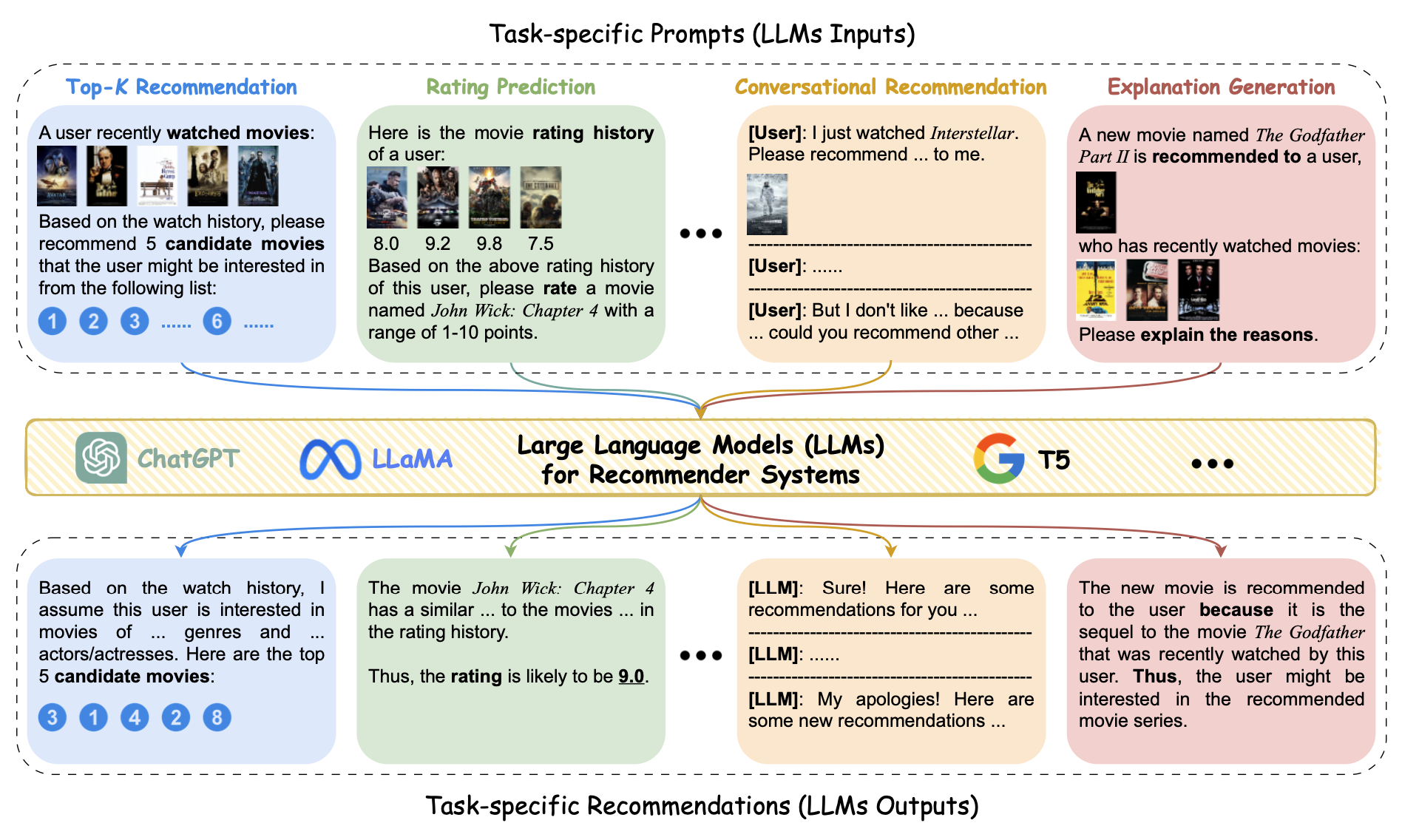 작업별 프롬프트 통해서 LLM이 직접 추천자 역할을 수행하는 예시
작업별 프롬프트 통해서 LLM이 직접 추천자 역할을 수행하는 예시
그러다 LLM이 등장했고, LLM은 뛰어난 언어 이해와 자연스러운 문장 생성 능력, 그리고 추론 능력을 통해 대화형 방식으로 사용자의 의도를 캐치하고 복잡한 질의를 처리할 수 있게 되었습니다. 여러 연구와 업계 사례로 LLM이 사용자 리뷰 분석, 아이템 설명, 대화형 추천 등에서 효율적으로 사용될 수 있다는 것이 확인되었습니다. 기존 딥러닝 기반 추천 모델이 어려워했던 추가적인 자연어 정보(사용자 프로필, 코퍼스 레벨 텍스트, 지식 그래프의 텍스트 정보 등)를 적극 활용할 수 있고, 지식 범위가 넓고 타 도메인으로 일반화하는 능력이 뛰어나서 다양한 추천 시나리오와 새로운 사용자/아이템에도 대응할 수 있다는 것이죠. 또 특정 태스크 데이터가 적어도 간단한 프롬프트로 작업 수행이 가능하다는 것도 새로운 가능성이라고 할 수 있겠습니다.
히스토리 짚어보기

위 그림은 지금까지 언어 모델과 추천 시스템의 발전 과정을 도식화한 것입니다. 이 부분은 간단하게 넘어가겠습니다.
- 초기의 협업 필터링과 콘텐츠 기반 추천
- CF: 사용자-아이템 행렬의 미완성 부분을 예측 e.g. matrix factorization
- CB: 주로 인구통계, 아이템 설명 등 텍스트 정보 활용
- 딥러닝 기반 모델(사용자 행동 시퀀스/패턴을 학습)과의 결합
- 사전 학습된 언어 모델(Pre-trained Language Model) 사용
- 트랜스포머 아키텍처 기반의 BERT, GPT등을 사용하여 방대한 양의 텍스트 데이터에 대한 학습을 거친 뒤 텍스트 데이터의 정보를 학습하거나, 사용자 시퀀스를 MLM, Auto-Regressive 방식으로 모델링하여 추천 성능을 개선 (BERT4Rec이 이런 예시)
- 단, 모델 사이즈가 커질수록 학습∙추론 비용 증가하고 대규모 도메인 데이터가 필요하다는 문제가 있음
Representation Learning
다시 말하자면 추천은 본질적으로 사용자의 특성을 잘 표현하고, 아이템의 특성을 잘 표현한 다음, 그 둘 사이의 유사도(또는 상호작용 확률) 를 계산하는 문제입니다. 따라서 사용자/아이템 표현(representation)을 배우는 것은 추천 시스템의 핵심인데요. (각 사용자/아이템에 대한 수치화된 벡터를 얻는 과정으로 ‘임베딩’이라고도 합니다.) 사용자와 아이템을 나타내는 방식은 크게 두 가지로 나눠 볼 수 있습니다. 첫번째는 간단히 각각 고유 인덱스(ID)를 사용하는 것이고 두번째는 텍스트 정보를 사용하는 것이죠. 이 두 가지 방식은 다음과 같은 그림으로 비교해볼 수 있습니다.
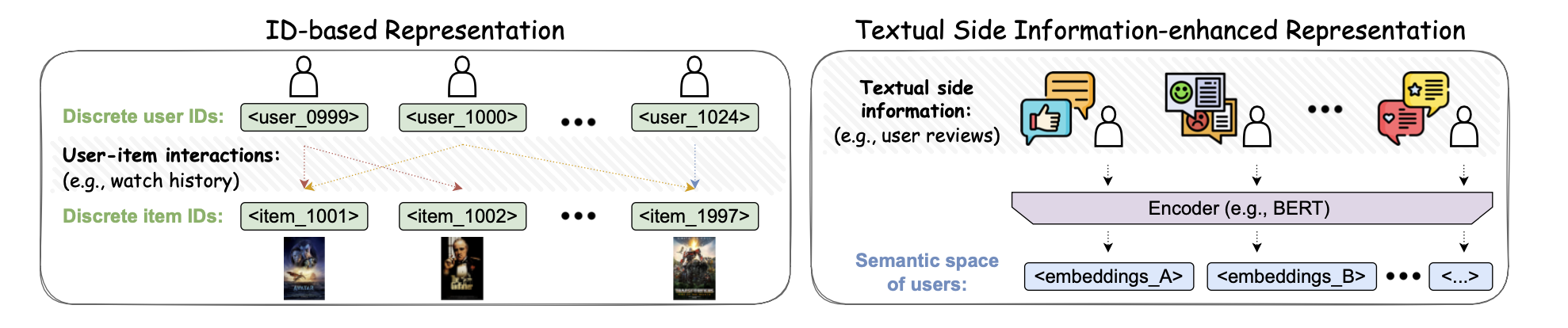
첫번째 ID 기반의 임베딩은 사용자와 아이템을 고유 정수 ID로 다룹니다. user_1234, item_56789 요런 식으로요. LLM 기반 추천 시스템의 초기 단계의 예시 중 하나는 P5라는 패러다임이었는데(사전 학습된 T5를 백본으로 이용), 이런 ID들을 LLM 어휘 내에서 하나의 특수 토큰으로 취급하면서 사용자와 아이템의 상호작용을 포함한 다양한 형식의 데이터들을 자연어 시퀀스로 만들었습니다(“User 123 watched movie 456 and rated 4 stars”). 여기서 각 사용자/아이템 ID는 하나의 새로운 단어인 거죠. 이런 ID 기반 방법의 문제는 불연속적인 ID이기 때문에 의미를 포함할 수 없고, 특히 사용자-아이템 상호 작용이 극히 드문 경우 추천을 위한 정보를 습득하기가 매우 힘들다는 것입니다. 또한 ID 개수가 매우 많으면 어휘 확장으로 인한 계산 비용도 많이 증가하게 됩니다.
두번째 텍스트 정보 기반의 임베딩은 ID가 아닌 사용자와 아이템의 텍스트 정보(프로필, 설명, 리뷰)를 LLM으로 인코딩하는 방식입니다. 도메인 지식, 제품 스펙, 리뷰 감정 등 ‘맥락 정보’를 자연스럽게 추천 시스템이 배울 수 있고, 텍스트 설명이 있다면 처음 보는 유저나 아이템에 대해서도 어느 정도 의미를 파악할 수 있으니 콜드 스타트에도 덜 취약하죠. 다만 텍스트가 길거나 품질이 낮으면 임베딩의 품질도 낮아질 수 있고 실시간 대규모 서비스 시에는 추론 단계에서 비용이 문제가 될 수도 있습니다.
따라서 두 가지 방식을 혼합한 사례가 대다수인 것으로 보이는데, 일반적으로 유저/아이템을 ID 형태로 다루되 각각의 텍스트 설명을 함께 학습하도록 합니다. 예를 들어 ShopperBERT는 이커머스 도메인에서 사용자의 행동 데이터 시퀀스를 BERT MLM(Masked Language Model; 단어를 일부 마스킹해서 맞히도록 모델을 학습) 방식으로 학습해서 임베딩을 얻는데, 이때 행동의 설명 텍스트(검색어, 리뷰 등)를 같이 활용합니다.
어 근데 여기를 읽으면 이건 LLM보다는 (위-에 있는 히스토리 도식에 따르면) PLM 활용에 가까운 것 같은데? 싶으실 겁니다. 맞습니다. 이 챕터는 사용자/아이템 임베딩에 초점을 두고 있고, 이 주제에서는 상대적으로 BERT 같은 PLM 중심 기법이 더 많이 등장합니다. 아직 임베딩 학습에서는 (특히 실시간, 대규모 서비스 환경에서는 비용 상) PLM 수준의 모델을 효율적으로 돌리는 경우가 많은 것 같습니다. 물론 LLM으로 사용자/아이템에 대한 텍스트 설명에서 표현을 학습하는 것도 충분히 가능한 일입니다. 다만 LLM만이 할 수 있는 영역은 이후 챕터들에서 더 나옵니다.
Pre-training & Fine-tuning LLM
LLM 사전 학습(Pre-training)은 일반적으로 모델이 방대한 텍스트 코퍼스(예를 들면 매우 큰 볼륨의 웹 문서들)에서 언어 패턴을 학습하는 단계입니다. 이 논문에서는 사전 학습의 두 가지 유형으로 일부 단어를 마스킹해서 모델이 이를 잘 맞히도록 학습하는 MLM(Masked Language Model)과 다음 단어를 예측하는 Auto-regressive한 NPT(Next Token Prediction) 방법을 소개하고 있습니다. 보통 MLM은 양방향의 텍스트 문맥을 이해할 수 있고, NPT는 다음에 오는 텍스트를 생성하는 데 강점이 있는 것으로 알려져 있죠. 이를 추천 시스템에 적용한 예시로는 PTUM(사용자의 클릭, 시청과 같은 행동 시퀀스를 NPT/MLM으로 학습해서 순차 추천에 응용), M6(텍스트+이미지 멀티모달 이커머스 데이터를 NPT/MLM 방식으로 함께 학습) , 앞서 언급된 P5 등을 들고 있습니다.
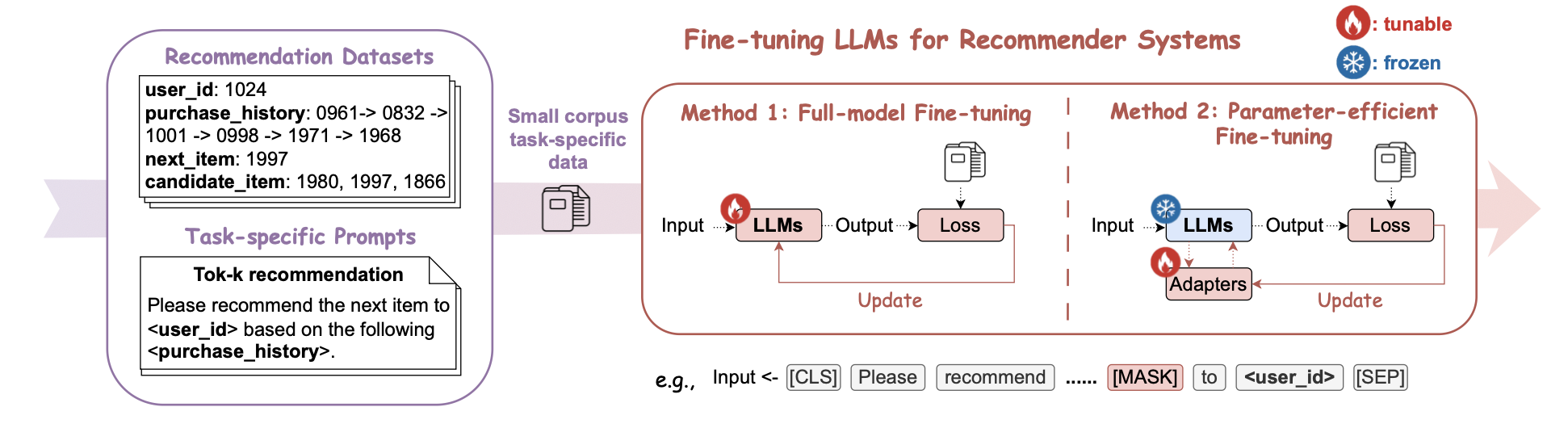
다운스트림 태스크에서 LLM은 더 많은 도메인 지식을 파악하기 위해 Fine-tuning이 필요합니다. 이 글에서는 위 그림처럼 전체 모델 fine-tuning과 parameter-efficient fine-tuning(PEFT)으로 나눠서 설명하고 있습니다.
전자(LLM의 모든 파라미터를 업데이트하는 전략)의 경우, 성능은 놓지만 수십~수천억의 파라미터를 전부 학습해야 하므로 매우 비싼 계산 비용이 발생하고 실제 환경에서 거의 불가능한 영역인 경우가 많습니다. 특히 도메인 특화 및 개인화 요구가 강한 추천 시스템에서는 작은 추가 학습만으로 각 태스크에서 성능을 높일 수 있는 PEFT 전략이 실무에서는 유용할 것입니다. PEFT는 대부분의 파라미터를 고정하되 작은 랭크 행렬이나 추가 훈련 가능한 어댑터 레이어만 조정하는 전략으로 큰 모델을 더 적은 자원으로 빠르게 도메인에 최적화할 수 있습니다. 주로 LoRA를 사용한 예시가 많은데 LLaMA 기반 추천 모델을 LoRA를 사용해서 조정한 TallRec이나 LLaRa, LoRA+Adapter 방식을 적용한 LLMRec 등을 예시로 들 수 있습니다.
Prompting LLM
이제 작업별 프롬프트를 통해 LLM을 다운스트림 작업에 적용하는 방식을 이야기해봅시다.
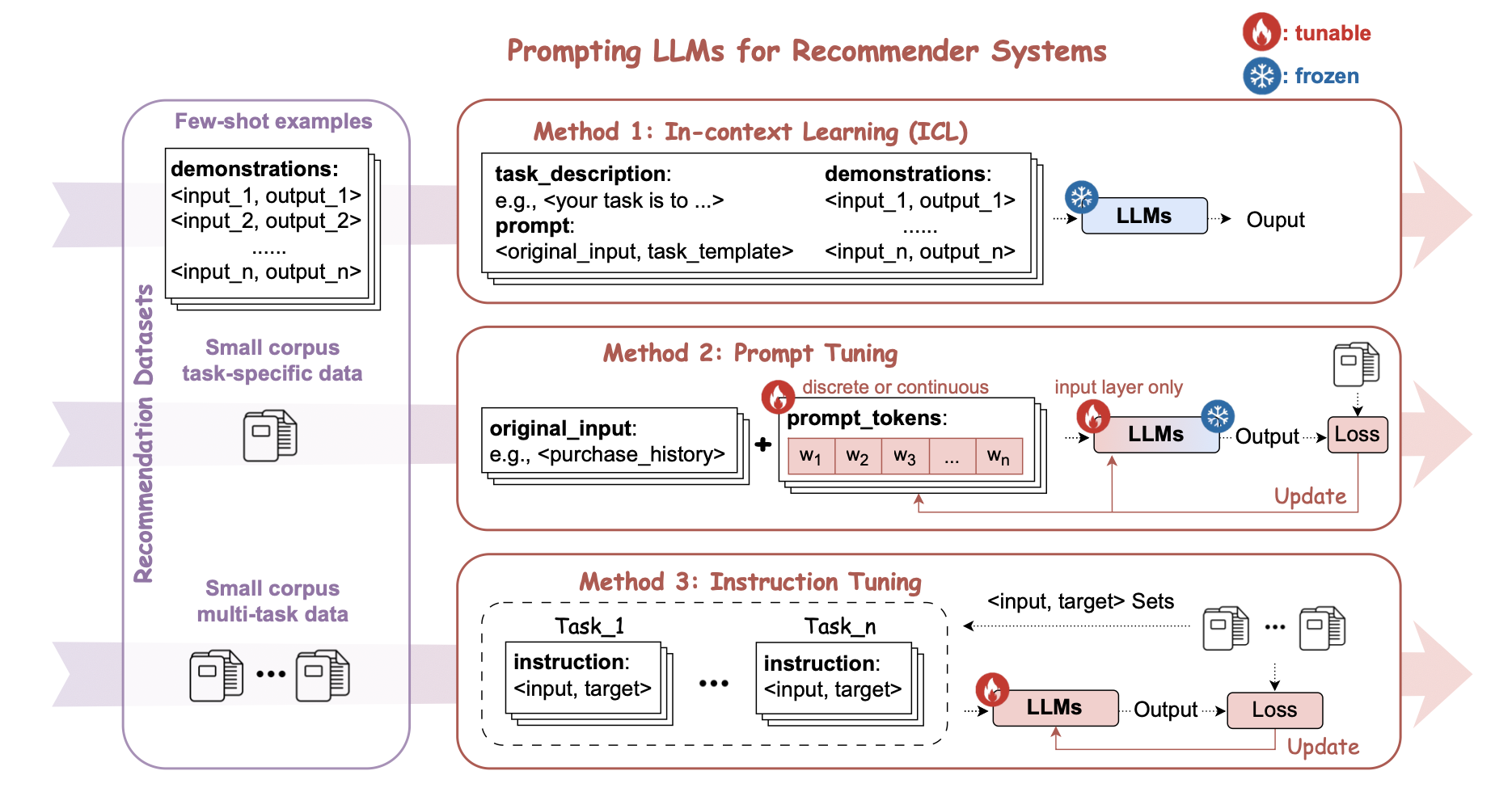
첫번째로 비교적 초기 단계에 등장했던 기본적인 프롬프트 방식들이 언급됩니다. 가장 대표적인 것은 ICL(In-context Learning)으로, LLM의 파라미터를 변경하지 않고 프롬프트 내에 입력-출력 예제를 제공하여, 마치 모델이 학습한 것처럼 동작하도록 유도하는 방식입니다. 제공되는 예시의 수에 따라 Few-shot ICL과 Zero-shot ICL로 나눌 수 있고 일반적으로 Few-shot ICL이 Zero-shot ICL보다 우수한 성능을 보이는 경우가 많습니다. 추가적인 문맥 내 예시를 제공함으로써 LLM이 태스크를 더 잘 수행하도록 유도할 수 있기 때문이죠. 반면 Zeo-shot ICL은 태스크별 추천 데이터셋을 별도로 준비할 필요가 없다는 장점이 있고, 대화형 추천처럼 사용자가 LLM에 명시적인 예제를 제공하지 않는 상황에 적절할 수 있습니다.
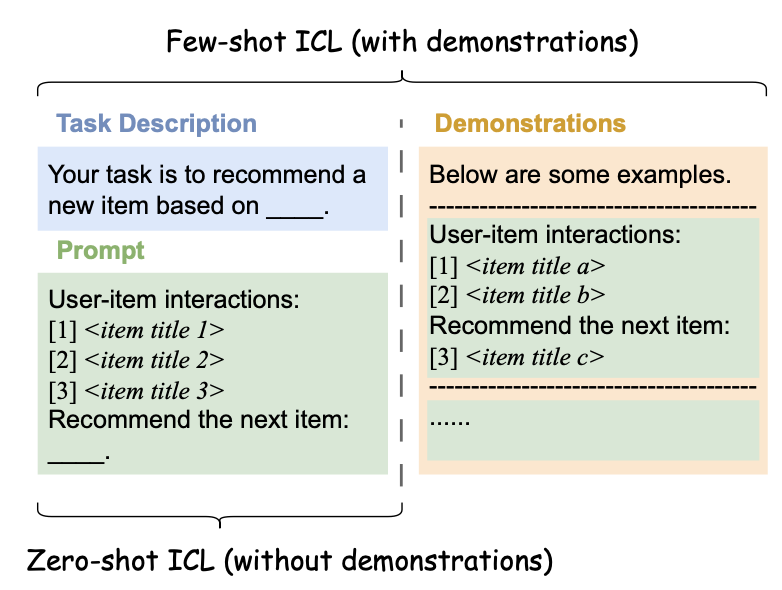
ICL은 기존의 전통적인 추천모델과 LLM을 연결하는 데 사용될 수도 있고(예를 들면 기존의 추천 모델에서 생성된 후보 아이템 목록을 전달받아서 LLM이 이를 기반으로 최종 추천 결과를 조정), 최근에 활발히 진행되는 LLM을 활용한 자율적인 추천 에이전트(autonomous recommendation agent) 연구에서도 사용됩니다.
또 chain-of-thought 방식의 프롬프트도 언급하고 있는데, 모델이 추천 결과를 단계적으로 추론하여 논리적으로 설명할 수 있도록 유도하는 방식입니다. 예를 들어, “유저의 구매 내역을 보고 단계별로 생각해보자. 먼저, 유저의 high-level intention이 뭘까? 두번째로, 구매한 아이템과 일반적으로 같이 판매되는 아이템은 뭘까? 마지막으로, 쇼핑 의도와 아이템 연관성을 같이 고려해서 선정된 아이템을 추천해 줘.”
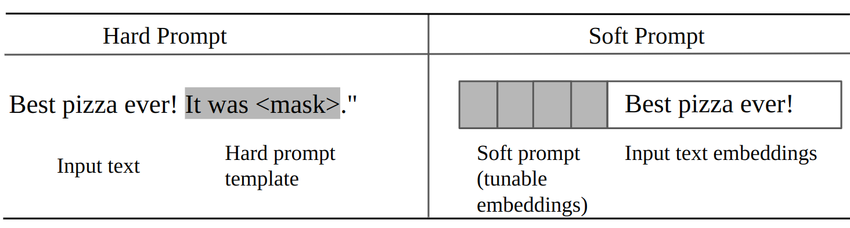
두번째는 프롬프트 튜닝입니다. 프롬프트 튜닝은 모델을 직접적으로 변경하지 않으면서도, 적은 리스스로 각각의 다운스트림 태스크에서 성능을 극대화할 수 있는 실용적인 방식인데요. 직접 텍스트 형태의 프롬프트를 설계해서 고정된 템플릿 형태를 취하는 하드 프롬프트(Hard Prompting) 방식과 학습 가능한 벡터를 추가하여 최적의 프롬프트를 자동으로 찾는 방식의 소프트 프롬프트(Soft Prompting) 방식으로 나누어 볼 수 있습니다. 사실 위에 언급된 기본적인 프롬프트들을 쓰는 방식은 넓게 보면 하드 프롬프트의 일종이겠네요.
마지막으로 Instruction 튜닝은 모델이 모델이 추천 관련 태스크를 더 잘 수행할 수 있도록 다양한 지시문(Instruction)과 입력, 정답 데이터(출력)의 쌍을를 학습하는 방식입니다. 프롬프트와 fine-tuning의 성격을 모두 지니고 있다고 할 수 있는데요. 예를 들어, “사용자의 최근 평점 데이터를 기반으로 다음에 볼 영화를 3개 추천하세요.”와 같은 문장과 입력(평점 데이터)과 출력(3개의 영화)을 학습 데이터로 만들어, 모델이 특정 형식의 질의에 자연스럽게 응답할 수 있도록 합니다. 이를 활용하면 특정 추천 시스템 도메인에 맞춘 맞춤형 프롬프트를 설계할 수 있고, 비교적 적은 데이터로도 유사한 유형의 새로운 질문에도 더 잘 적응하는 학습 효과를 낼 수 있습니다(Few-shot).
각 유형 별로 좀 메이저한 연구들을 잘 요약된 표(그리고 Code Availability까지)로 정리해놓았기 때문에 궁금하신 분들은 논문 10페이지를 보시면 되겠습니다.
Future Directions
마지막 장에서 이 논문은 LLM 기반 추천 시스템이 미래에 다뤄야 할 가능한 문제와 해결책들을 언급하고 있습니다. 이 부분도 간단하게만 정리해 보겠습니다.
- Hallucination 해결
- 생성 결과 후처리(외부 지식 그래프나 신뢰 가능한 DB로 팩트체크, 필터링)
- 학습 시 거짓 정보 샘플에 대한 패널티 전략 추가
- 신뢰성과 공정성
- Fairness Metrics(정량화 지표)를 바탕으로 파인튜닝
- 개인정보 보호(Privacy)와 함께 투명성을 확보하기 위한 Explainable AI 기법 병행
- 대화형 및 멀티모달 추천 확장
- 예) 의류 코디 추천(이미지 분석), 음악 추천(가사∙오디오 텍스트 변환), 여행지 추천(지도+텍스트)
- 고효율 모델 및 경량화 (On-device)
- 실 서비스에서 추론 비용과 속도가 매우 중요하므로 LoRA, Adapter, Knowledge Distillation, Quantization 등으로 모델 사이즈나 연산량 축소
- 모바일∙엣지 디바이스에서도 동작 가능한 ‘Small LLM’ 연구 필요
- 주석∙피드백 기반 학습
- ChatGPT의 RLHF(RL from Human Feedback)같이, 실제 사용자 피드백이나 인력 라벨링으로 모델 품질 향상
- 온라인 러닝 시도로, 사용자 상호작용에 따라 실시간 업데이트
- 그래프 구조와 LLM의 융합
- LLM을 그래프 학습에 직접 적용하거나, 그래프에서 추출된 텍스트 시나리오를 프롬프트로 활용
- e.g. “아이템 A-B-C가 연관되고, 사용자가 A를 좋아하면 B도 좋아할 확률이 높다” 식의 reasoning을 LLM이 자연어로 실행
- 더 강화된 개인화
- 개인화 프롬프트(사용자 프로필을 반영한 템플릿), 개인화된 어댑터(PEFT)로 각 사용자에게 특화된 LLM 응답
- 프라이버시 보호와 개인화의 균형
- 추천의 설명 가능성과 투명성 - 추천 근거를 텍스트로 제시하는 것은 이미 LLM에게 쉬운 일이지만 환각적 설명의 위험이 있으므로 신뢰 가능한 설명 기법을 도입해 투명성 보장
- 에이전트형 RecSys
- LLM에 상태관리, 툴 API 연동, 메모리 저장 기능을 추가해 복합 액션 수행
- 자율적으로 목표를 설정하고 하위 태스크를 수행해 최적의 추천 전략을 도출