[번역] PEGASUS: 추출된 빈 문장으로 사전훈련을 하는 새로운 추상적 문서 요약 모델
번역글이며, 원문은 여기입니다.
학생들에게는 종종 읽고 이해하는 능력과 글 쓰는 능력을 모두 보여주기 위해 문서를 읽고 요약을 하는 것이 과제로 주어지곤 합니다. 이러한 추상적 문서 요약은 자연어처리 분야의 가장 어려운 과제 중 하나인데요, 긴 문단들에 대한 이해, 정보 압축, 그리고 언어 생성이 모두 관여되는 작업이기 때문이죠. 이러한 목적으로 머신 러닝 모델을 훈련시킬 때 가장 지배적인 패러다임은 신경망이 인풋 시퀀스와 아웃풋 시퀀스를 연결하도록 학습하는 시퀀스-투-시퀀스sequence-to-sequence, seq2seq) 방식입니다. 비록 처음에는 seq2seq 모델들이 RNN(순환신경망) 기반으로 개발되었지만, 최근에는 트랜스포머 (Tansformer) 인코더-디코더 모델들이 요약 대상인 긴 문장들 간 존재하는 의존성을 모델링하는 데 더 효과적이라는 것이 드러남에 따라 더 많이 사용되고 있습니다.
자기지도학습(self-supervised learning) 사전훈련(pretraining)과 결합된 트랜스포머 모델들(e.g., BERT, GPT-2), RoBERTa, XLNet, ALBERT), T5, ELECTRA))은 언어 학습 전반에서 매우 강력한 프레임워크인 것으로 드러났고, 파인 튜닝(fine-tuning)될 경우 수많은 언어 처리 과제에서 최첨단의(state-of-the-art) 성능을 보여 왔습니다. 지금까지는 사전훈련이 전반적인 학습에 중점을 두었기 때문에, 이때 시행되는 자기지도학습의 목적은 다운스트림 태스크에 대한 적용과 연관할 때 다소 불가지론적으로 여겨졌습니다(즉 일반적인 말뭉치의 의미 정보를 습득하도록 하느라 실제 적용해야 할 태스크와의 관련은 파악하기 어려웠습니다). 이때의 우리의 의문은 최종적인 태스크와 조금 더 가까운 목적으로 자기지도학습을 진행하는 것이 더 좋은 성능을 가져오지 않을까 하는 것이었습니다.
“PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization” (2020 ICML)에서 우리는 트랜스포머 인코더-디코더 모델을 위한 사전훈련 자기지도학습 목표를 구성하고, 이를 빈 문장 생성(gap-sentence generation)으로 명명합니다. 이 모델은 12개의 다양한 추상적 요약 과제 데이터셋에 대해 파인 튜닝 시 최첨단의 성능을 달성하였습니다.
요약을 위한 자기지도학습 목적 설정
사전훈련 시 자기지도학습의 목표가 최종적인 다운스트림 과제에 가까울수록 파인 튜닝 성능이 좋을 것이라는 게 우리의 가설이었습니다. PEGASUS 사전학습에서는 몇 개의 온전한 문장들이 문서로부터 제거되고, 모델은 그 문장들을 회복해야 합니다. 예를 들어 사전훈련 인풋의 예시는 몇 개의 문장을 마스킹한 문서이며, 그 마스킹된 문장들이 합쳐진 것을 아웃풋으로 내놔야 합니다. 사실 이는 거의 불가능해 보일 정도로 매우 어려운 과제이며, 심지어 사람에게 시켜도 해내기 어려울 것입니다. 우리는 모델이 이 문제를 완벽하게 해낼 것으로 기대하지는 않습니다. 그러나 이처럼 어려운 과제를 부여받음으로써 모델은 세계의 일반적인 사실들과 언어에 대해서 배울 수 있으며, 이후 파인 튜닝 요약 과제와 매우 비슷한 아웃풋을 생성해내기 위해 문서 전체에서 얻는 정보들을 정제하는 법도 학습합니다. 이러한 자기지도학습 방식의 장점은 사람이 주석을 다는 일 없이 문서가 있는 한 예시를 마음껏 만들어낼 수 있다는 것입니다.
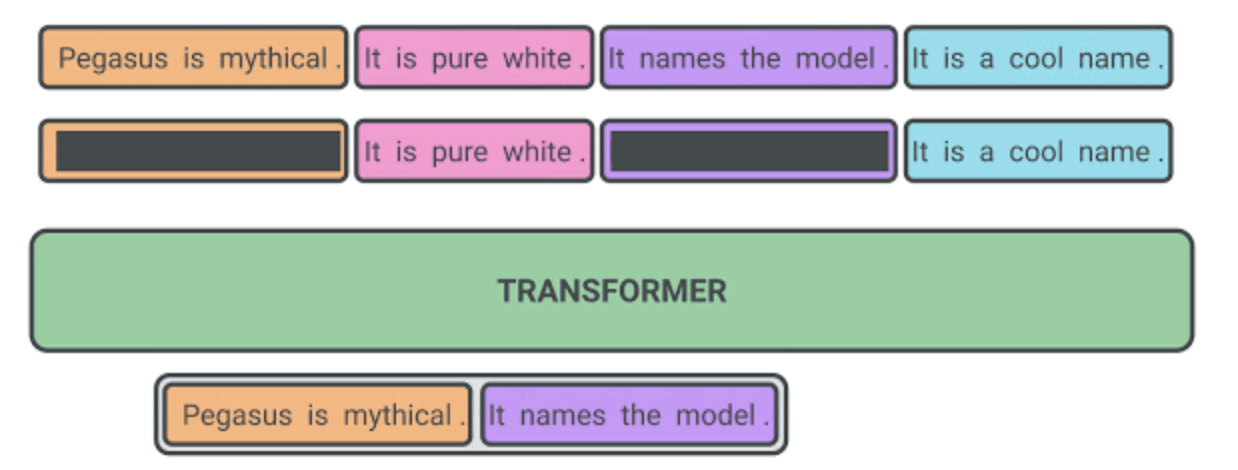
마스킹된 문장들이 “중요한” 문장들일수록 자기지도학습의 아웃풋이 ‘‘요약’‘에 가까워지며, 모델의 성능도 향상됩니다. 우리는 ROUGE)라는 메트릭에 기반하여, 자신을 제외한 나머지 문서 내용과 가장 비슷한 문장들을 자동으로 찾을 수 있도록 했습니다. ROUGE는 0부터 100까지의 점수를 사용하여 두 개의 텍스트의 유사도를 n-gram을 가지고 계산합니다. (ROUGE-1, ROUGE-2, ROUGE-L 이 세 가지가 일반적으로 사용되는 변수들입니다).
T5 와 같은 우리의 최근 다른 방식과 유사하게 우리는 웹에서 문서들을 크롤링하여 매우 큰 말뭉치로 우리의 모델을 사전 훈련시켰습니다. 그리고 12개의 공개된 추상적 요약 데이터셋에 대해 파인 튜닝시켰고, T5에서 사용한 것의 5%에 그치는 적은 수의 파라미터만 사용하여 새로운 state-of-the-art 결과를 얻었습니다. 이 데이터셋들은 뉴스 기사, 과학 논문, 청원들, 단편들, 이메일들, 법적 문서들, 가이드들까지 포함하여 다양하게 선택하였으며, 이 모델 프레임워크가 넓은 분야의 주제들에 적용될 수 있음을 보여주었습니다.
더 적은 수의 데이터로 파인 튜닝 한다면
이처럼 PEGASUS는 거대한 크기의 데이터셋에서 놀라운 성능을 보여주었지만, 놀랍게도 이 모델이 state-of-the-art 수준에 거의 도달하는 결과를 얻기 위해서는 애초에 그다지 많은 데이터를 필요로 하지 않았습니다.
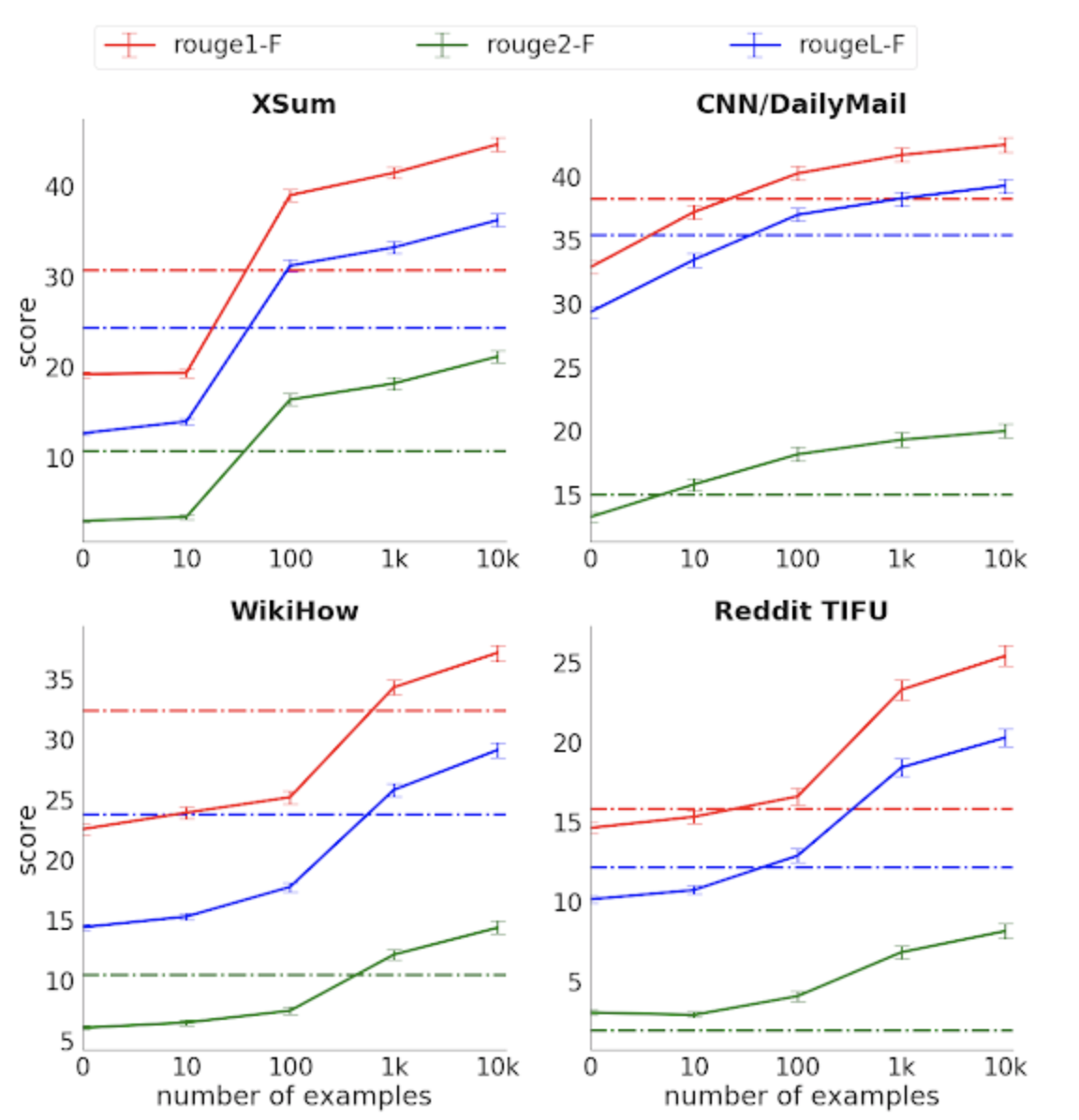 4개의 요약 데이터셋에 대해 ROUGE 점수 (3가지 지표, 높을수록 좋음) vs. 라벨링된 데이터 크기. 점선은 사전훈련 없는 베이스라인 트랜스포머 인코더-디코더 모델.
4개의 요약 데이터셋에 대해 ROUGE 점수 (3가지 지표, 높을수록 좋음) vs. 라벨링된 데이터 크기. 점선은 사전훈련 없는 베이스라인 트랜스포머 인코더-디코더 모델.
1000개의 파인 튜닝 예시를 가지고, 우리는 대부분의 과제에서 이보다 몇 차수나 많은 수의 완전한 지도학습 데이터를 사용한 강한 베이스라인 모델 (트랜스포머 인코더-디코더)보다 좋은 성능을 보이는 것을 확인했습니다. 요약 과제에 필요한 라벨링된 데이터의 수집은 매우 비싸다는 것을 고려할 때, 이 정도의 샘플 효용성은 비용과 스케일을 상당히 줄일 수 있다고 할 수 있습니다.
사람의 요약과 비교한다면
비록 ROUGE와 같은 자동적인 평가 지표가 모델 개발에서의 성능 향상을 측정하는 데 유용한 도구로 사용되었지만, 이러한 지표가 가진 정보는 제한되어 있고, 유창함이나 인간 수행과의 비교 같은 부분은 말해줄 수 없습니다. 따라서 우리는 추가적으로 인간 평가를 수행하였고, 평가자들이 사람이 작성한 요약문과 우리의 모델이 작성한 요약문을 (뭐가 어느 것인지 모르는 채로) 비교하도록 하였습니다. 우리는 3가지 데이터셋에 대해 이 실험을 진행하였고, 평가자들이 PEGASUS의 결과물에 비해 사람이 작성한 요약문을 특별히 선호하지 않는다는 사실을 확인하였습니다. 무엇보다 1000개 예시만 가지고 훈련된 모델조차 거의 비슷한 결과를 가져왔습니다. 특히 많이 연구되어온 XSum과 CNN/Dailymail 데이터셋의 경우, 우리의 모델이 1000개 예시만 가지고 인간과 거의 동일한 성능을 내었습니다. 이러한 결과는 더 이상 요약이라는 과제를 위해 거대한 크기의 라벨링된 데이터가 필요하지 않다는 사실을 보여주며, 저비용의 유즈케이스가 많을 것임을 시사합니다.
이해력 테스트 : 배가 몇 척인지 셀 수 있나?
XSUM 데이터의 테스트 문서에 대해 우리의 모델은 이렇게 요약을 합니다: “BBC 취재 결과에 따르면 4척의 영국 해군 군함을 다시 사용하여 보존할 수 있도록 하는 제안이 제출되지 않았다.” 이때 모델은 문서에 등장하는 4척의 배 (HMS Cumberland, HMS Campbeltown, HMS Chatham and HMS Cornwall) 를 “네 척의 영국 해군 군함”으로 성공적으로 요약 및 페러프레이즈해냅니다. 추출하는 방식의 요약을 했다면 얻어낼 수 없는 결과인 것이, “4”라는 숫자는 원 문서 어디에도 없거든요. 요행일까요, 아니면 진짜 모델이 숫자를 세었던 걸까요? 이걸 알아낼 수 있는 방법은 문서에 등장하는 배를 없애거나 추가해보고 숫자가 변하는지 보는 겁니다.
전체 원래 & 바뀐 버전의 문서과 모델의 요약 결과는 원문 맨 하단에서 확인할 수 있습니다. 여기서는 결과 부분(원문에 포함된 부분)만 번역하였습니다.
2척부터 5척까지는 모델이 성공적으로 배가 몇 척인지 ‘셉니다’. 그러나 6번째 배인 ‘HMS Alphabet’을 더한 순간, 모델이 7척이라고 잘못 세어 버립니다. 이를 봤을 때 적은 수의 리스트를 몇 개인지 세는 것은 가능한데, 우리가 기대하는 만큼 훌륭하게 일반화되지는 않나 봅니다. 그럼에도 이러한 기초적인 셈 능력이 인상적인 이유는, (숫자를 세어서 짧게 보여주는 것이) 모델에 명시적으로 프로그래밍되지 않았기 때문이며 비록 제한이 있더라도 이 모델 나름의 상징적 사고 능력을 보여주고 있기 때문입니다.
이 분야의 지속적인 연구와 결과 재생산을 위해 코드와 모델 체크포인트를 GitHub에 공유합니다. 다른 요약 데이터셋에 PEGASUS를 적용할 때 사용할 수 있는 파인튜닝 코드도 포함되어 있습니다.