사전훈련된 NLP 모델에서 성별 상관의 측정과 완화
지난 몇 년 간 자연어처리 분야에서는 BERT, ALBERT, XLNet, ELECTRA처럼 사전훈련된 모델을 다운스트림 태스크를 위해 파인튜닝하는 것이 가장 좋은 성능을 낼 수 있는 선택이었습니다. 이 과정에서 모델은 필연적으로 훈련 데이터에서 특정 단어, 혹은 특정 개념들 간의 강한 상관을 학습하게 됩니다. 그러나 어떤 상관은 잘못 형성되면 사회적인 고정관념이 모델의 결정에 영향을 미치게 할 수 있기 때문에 주의 깊게 다뤄져야 할 필요가 있습니다. 특히 성별에 의한 상관 (gendered correlation)은 학계에서도 기업에서도 이러한 편향 문제를 다루는 데 있어서 가장 우선시하는 주제 중 하나입니다.
 ☹️고비용을 들여 훈련시킨 모델이 간호사가 남자일 거란 생각을 못해서 환자에게 근무를 시켜 버리면 안 되겠죠?
☹️고비용을 들여 훈련시킨 모델이 간호사가 남자일 거란 생각을 못해서 환자에게 근무를 시켜 버리면 안 되겠죠?
Measuring and Reducing Gendered Correlations in Pre-trained Models 는 사전훈련된 자연어처리 모델 및 적용되는 다운스트림 태스크에서 성별 상관을 측정할 수 있는 메트릭과 가능한 완화 테크닉을 제안하고, 비슷한 정확도를 보이는 기존의 모델들도 이 메트릭에 따르면 크게 차이가 날 수도 있다는 것을 보인 연구입니다. 개인적으로 이 연구를 리뷰하고 싶었던 이유는 제안하는 메트릭과 완화 전략이 성별과 같은 어떤 특정한 상관에만 한정되는 것이 아니라 일반적으로 적용될 수 있는 확장성을 가지고 있다는 점 때문입니다. 이 연구는 사실 제시되는 모델의 ‘성별’ 상관에 대한 케이스 스터디라고 볼 수도 있겠네요.
참고로 모델 이름은 Zari입니다. Zari는 역시나 세서미 스트리트의 muppet이고, 아프가니스탄 출신의 6살 소녀 캐릭터입니다. “어린 소녀도 누구 못지 않게 해낼 수 있다는 것을 보여주기 위해” 디자인되었다고 하네요. 이 연구의 모델 체크포인트들은 여기서 확인해볼 수 있습니다.

그리고 이 포스팅에서 ‘성별 상관’이라는 표현을 계속 사용하는 것은 이 논문 저자들의 선택을 따른 것입니다. 동 주제의 다른 연구들에서는 성별 편향(gender bias)라는 말을 더 자주 발견할 수 있습니다. 이 논문의 저자들은 편향, 편견이라는 말이 사회적이고 문화적인 기준에 따라 달라지는 것이기 때문에 객관적인 표현을 쓰고자 했다고 하는데요. 개인적으로는 상관인지 편향인지 아무튼 ‘그 현상’이 지극히 사회적이고 문화적인 언어 사용 패턴에 의해 발생하는 것일 뿐더러, 이런 연구들이 대개 모델의 사용에 있어 의도치 않은 부정적인 영향을 가져오는 것을 방지하는 것을 목적으로 하고 있기 때문에 살짝 덜 객관적으로 ‘편향’이라고 말해도 큰 문제는 없을 것 같다는 생각을 했습니다. 그래도 뭐 일단 표현은 논문과 똑같이 쓰겠습니다.
성별 상관 측정
이 연구에선 크게 4가지의 태스크와 메트릭으로 모델의 성별 상관을 측정합니다. 3가지는 이미 진행된 기존 연구를 그대로 혹은 일부 변형해서 사용한 것이고, 마지막은 이 연구가 새롭게 제안하는 방식입니다.
- Conference Resolution : 이 글의 맨 처음에 등장하는
his가 누구를 말하는 건지 찾기는 전형적인 conference resolution 태스크입니다. 기존 연구 (Rudinger et al., 2018) 는 모델이 이 태스크에서 she라는 대명사를 특정 직업 단어와 연관시킬 가능성과 미국 노동청에서 공시한 실제 그 직업 내 여성의 비율 간 피어슨 상관계수를 성별 상관 측정치로 삼았습니다. 즉 모델이 성별 상관을 강하게 보인다면, 여성이 실제로 많은 직업일수록 여성 대명사를 해당 직업 단어로 답변할 가능성이 높습니다. - STS(Semantic Textual Simularity)-B : 일반적 STS-B의 공식은 주어진 두 문장이 의미적으로 유사한 정도를 판단하는 것입니다. 이 연구는 기존 연구(Cer et al., 2017) 중
남자나여자가 주어인 문장들만 골라서 남녀 성별 버전을 직업 단어들로 바꾼 버전과 각각 비교합니다. 모델이 성별 상관에 의존하고 있지 않다면, 다음 두 쌍의 의미적 유사도는 별 차이가 없어야 합니다:남자가 걷고 있다-간호사가 걷고 있다,여자가 걷고 있다-간호사가 걷고 있다. 그렇지 않다면 차이가 발생하겠죠. 마찬가지로 이 점수차와 실제 직업 통계의 피어슨 상관계수를 측정치로 사용합니다. - Bias-in Bios : 웹에서 인물 전기 데이터를 수집한 다음, 각 전기에 그 사람의 직업을 라벨로 붙입니다. 이 태스크에서 모델이 해야 하는 것은 전기 내용만 읽고 라벨을 맞히되, 그 과정에서 성별 정보에 의존하지 않는 것입니다. 기존 연구(De-Arteaga et al., 2019)에서는 두 성별 샘플들 간의 TPR 차이를 직업에 따라 매크로 평균 낸 값을 사용했는데, 이 연구에서는 TPR 차이와 실제 직업 통계 간 선형 모델 적합 후 그 기울기를 사용했습니다(상관계수는 모델 간 차이가 별로 나지 않았다고 하네요).
Discovery of Correlations (DisCo) : 이 연구에서 제안하는 방식으로, 사전훈련 모델 자체에 대한 기술적 수치입니다. DisCo는 여러 개의 빈칸 있는 템플릿으로 이루어져 있습니다. 예를 들면,
[사람]이 대학교에서 [빈칸]을 공부했다.와 같은 문장들인데요.[사람]을 채운 뒤 모델이[빈칸]에 어떤 단어(순위 3개까지)를 채우는지 보는 방식입니다. 즉 그 후보 단어들이[사람]의 성별에 따라 유의하게 달라지는지 보겠다는 것이죠( $\chi^2$ 검정 사용).다음 2가지는
[사람]에 뭘 넣고 시작하는지에 따라 달라집니다.- DisCo (Terms) : 성별 의미가 들어간 단어들의 집합 사용 (ex.
여배우) - DisCo (Names) : 그 이름을 가진 사람의 80% 이상이 특정 성별로 편중된 이름들의 집합 사용 (ex.
Maria)
새로 제안하는 방식이니 만큼 장점 어필 문구가 없을 리 없는데요, 이 연구가 말하는 기존 연구에 비한 DisCo의 장점은 모델이 빈칸에 채우는 단어를 사전에 정해놓지 않고 모델이 뭘 내놓는지 관찰하는 방식이기 때문에 기존에 예상치 못한 상관을 발견해낼 수 있다는 것입니다. 그래서 이름이 Discovery가 되었고요.
- DisCo (Terms) : 성별 의미가 들어간 단어들의 집합 사용 (ex.
BERT/ALBERT의 점수는?
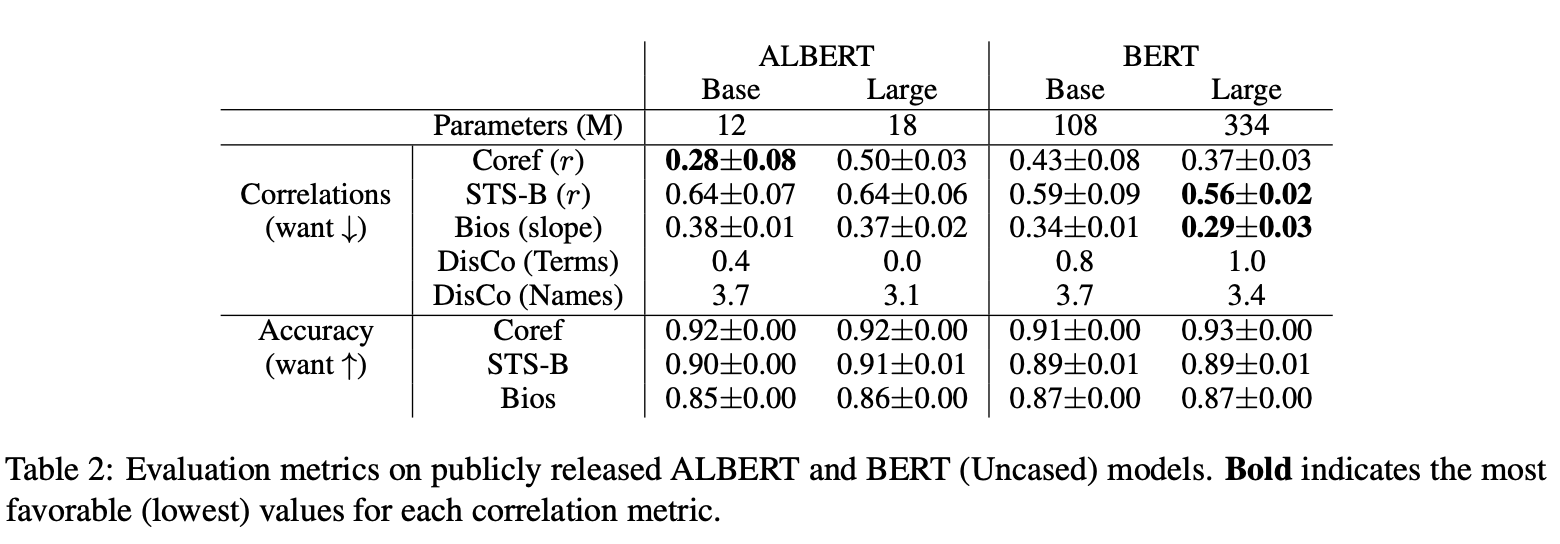
- 위 5개의 경우 성별 상관 메트릭 (낮을수록 좋음)
- 위 3개의 경우 각 태스크에 대한 성능 (높을수록 좋음) *DisCo는 다운스트림 태스크가 아니고 기술 측정이기 때문에 성능 지표가 없음
모델별로 성능 지표는 모든 태스크에 대해 큰 차이가 없는데도 불구하고(최대 2% 정도의 차이), 성별 상관 메트릭은 크게 차이가 나는 것을 확인할 수 있습니다. 특히 Conference Resolution 태스크의 경우 ALBERT Base와 Large가 정확도는 동일한데 상관은 거의 20% 이상의 차이를 보이고 있죠. STS-B와 Bias-inBios 에서는 BERT 모델들이 ALBERT 모델보다 좀 더 나은 상관을 보이는 수준입니다. (BERT 모델 사이즈에 따라 결과를 비교해본 부분도 논문에 실려 있으니 참고를!) 사실 이 부분을 지금 자세히 보지 않는 것은, 어떤 모델이 어떤 모델보다 낫다를 보여주기보단 비슷한 성능을 가지고 있더라도 특정 상관에 대한 점수는 상당히 차이가 날 수 있다 정도가 시사점이기 때문입니다.
해결책은?
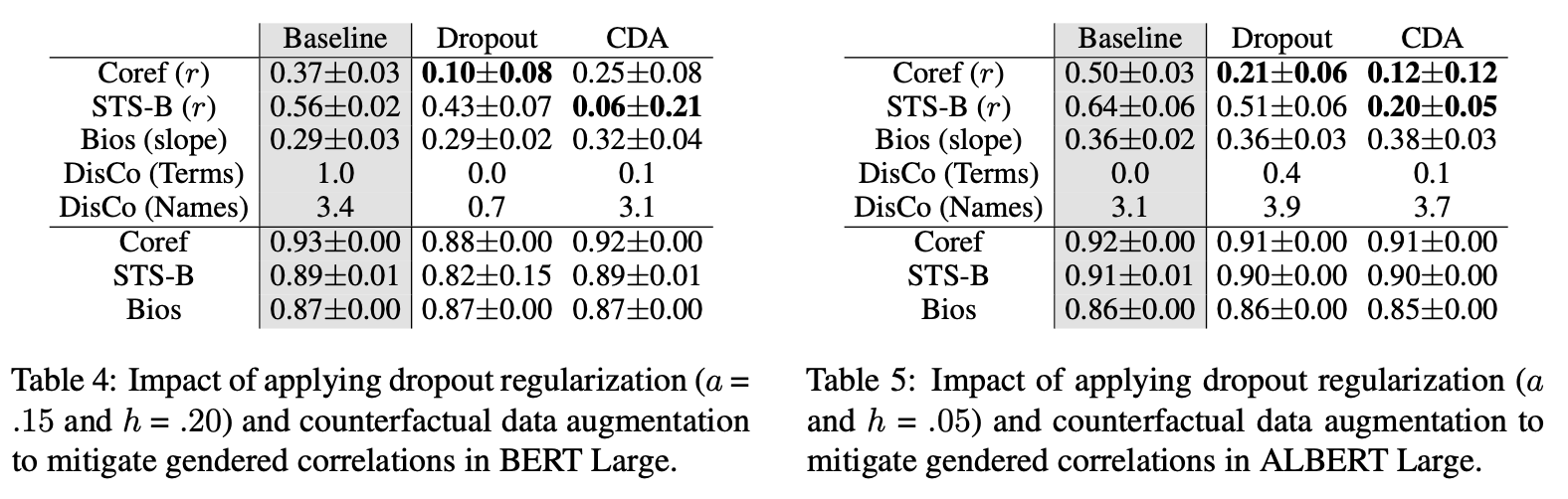 _2가지 완화 방법 적용시 성별 상관 메트릭의 변화 : (좌) BERT, (우) ALBERT
_2가지 완화 방법 적용시 성별 상관 메트릭의 변화 : (좌) BERT, (우) ALBERT
완화 방법 1. 드롭아웃 정규화
각 층에서 확률적으로 노드를 누락시키는 드롭아웃은 일반적인 오버피팅 방지 방법 중 하나죠. 모델이 성별처럼 어떤 특성에 의해 발생하는 개념들 간 상관을 지나치게 활용하는 것도 어떻게 보면 오버피팅이라고 볼 수도 있겠습니다. BERT는 드롭아웃 디폴트가 어텐션 가중치와 히든 활성화 층에 .10으로 적용되어 있고, ALBERT는 없습니다. 이 논문에서는 이 파라미터 값을 늘려 드롭아웃 비중을 높이거나 (ALBERT의 경우) 드롭아웃을 추가함으로써 정확도를 거의 떨어뜨리지 않고 성별 상관 메트릭을 크게 낮출 수 있음을 보였습니다.
완화 방법 2. 반사실적 데이터 증강 (Counterfactual Data Augmentaion)
멋있게 쓰면 CDA인데 간단히 말하면 바꿔치기입니다. 성별 정보가 들어간 정보를 그것의 반대 성별 단어로 바꿉니다. 예를 들어 데이터에 이 글을 쓴 남자는~ 이런 식의 문장이 있다면 그걸 이 글을 쓴 여자는~ 으로 바꿔 주는 것입니다. 이 연구는 이런 추가로 증강된 문장들을 모델 위에 얹어서 추가 단계로 훈련시켜주는 방식(1-sided application)과 처음부터 원래 문장들과 함께 훈련시키는 방식(2-sided application)을 둘 다 시도해보았다고 하는데, 전자가 완화 효과는 더 컸지만, 완화를 하다 못해 과도한 정정 효과가 일어나 종종 음수의 상관계수나 기울기가 발생했다고 합니다. 즉 반대 방향의 상관이 나타난 것이죠(완화라고 할 수 없게 되어버린 것!). 따라서 최적의 값으로 보고된 위 테이블은 2-sided 방식으로 적용한 결과입니다.
CDA도 대체로 훌륭하게 정확도를 유지하면서 상관 메트릭을 감소시키고 있습니다. 하지만 DisCo(Names) 항목을 보면 CDA의 치명적 한계가 보이는데요, Disco(Terms)와는 달리 상관이 전혀 감소되지 않은 걸 확인할 수 있습니다. 이유는 당연히 CDA에는 미리 정해진 인풋 단어 리스트가 필요하기 때문입니다. 즉, 남자를 여자로 바꾸고 소년을 소녀로 바꾸겠다는 사전 설정이 필요합니다. 그리고 그 리스트에 DisCo(Names)에서 사용하는 이름들은 없었던 것입니다.
태스크나 데이터에 따라 다르겠지만, 어떤 리스트도 이런 모든 가능성을 다 커버하긴 어렵습니다. 이 연구에서는 이름의 첫 글자를 알파벳을 절반으로 잘라(A~M으로 시작하는 이름) 랜덤한 이름으로 대치하는 식의 추가 보완 방법을 제시하고 있긴 합니다만, 이처럼 아마 리스트가 커버하지 못하는 단어들이 무엇인지에 따라 모델을 적용하는 사람이 주관적 센스(?)로 해결해야 하는 부분으로 보입니다. 즉 일반적으로 그냥 쓸 수 있는 방식인 드롭아웃과는 달리 CDA는 어떤 데이터에 대해 어떤 상관을 감소시키고 싶은지에 대한 정의와 설정된 인풋이 필요합니다. 바로 다음에서 언급될 다운스트림 태스크에서 더 robust한 것은 CDA 적용 모델이기 때문에, 뭐 두 가지 방법이 요렇게 장단이 있는 것으로 비교가 될 것 같네요.
완화 효과는 파인 튜닝 후에도 이어진다
마지막 인상적인 결과는 이렇게 사전훈련된 모델에 드롭아웃이나 CDA를 적용했을 때, 그 성별 상관 감소 효과가 파인 튜닝한 후에도 여전히 확인된다는 것입니다. 다운스트림 태스크 데이터 또한 만만찮게 성별 상관을 유발할 수 있는 정보들을 담고 있을 텐데도 말이죠.
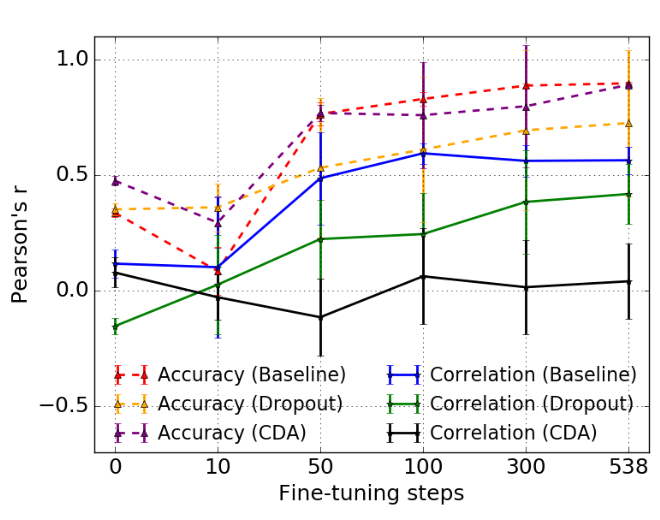
위 그림은 파인 튜닝 스텝에 따른 3가지 모델의 정확도와 성별 상관 수치입니다. 처음에는 정확도와 상관이 모두 낮지만, 파인 튜닝이 진행되면서 정확도는 증가하고, 상관의 경우 함께 증가하거나(Baseline) 덜 증가 혹은 낮게 유지(Dropout, CDA)되네요. CDA 적용된 모델이 Baseline 모델(Public BERT)와 성능은 크게 차이 나지 않으면서 성별 상관도 끝까지 낮게 유지하는 게 눈에 들어옵니다. 즉 모델은 태스크 데이터에서 성별 상관을 추가로 접하게 되는데, 완화 기법이 적용된 모델은 그렇제 않은 모델에 비해 견고하게 낮은 상관을 유지하는 것입니다.