MLFlow Tracking 튜토리얼
MLFlow 로 머신러닝 모델의 실험 트래킹/로깅을 처음 해보는 사람을 위한 간단한 튜토리얼입니다. 제가 처음 해보면서 썼습니다.
들어가기 전에
이 글을 보고 얻을 수 있는 정보는:
- MLflow 로 ML 실험을 기록하고 싶은데 어떻게 하는지 간단하게 알고 싶다/따라하고 싶다
- Pyspark로도 쓰고 싶다 (+ Pandas UDF)
- 같은 실험을 그룹별로 나눠서 진행하고 싶다
이 글에서 사용한 것은:
- Databricks 커뮤니티 버전
- 무료이고 쉽게 써볼 수 있어서이고, 빠르게 따라할 수 있는 Tracking 튜토리얼이 이 글의 목표이기 때문입니다. 커뮤니티 버전의 경우 모델 레지스트리나 배포는 안 됩니다(돈 내야 합니다).
- seaborn에 내장된 펭귄 데이터셋
- 요즘은 Penguin is the new iris 라고 하더군요. 저는 펭귄을 좋아하기 때문에 아주 반갑습니다. 아무래도 꽃보단 펭귄이죠 🐧
1 2 3
import seaborn as sns penguins = sns.load_dataset('penguins') penguins.head(3)
- 요즘은 Penguin is the new iris 라고 하더군요. 저는 펭귄을 좋아하기 때문에 아주 반갑습니다. 아무래도 꽃보단 펭귄이죠 🐧
![]()
- 펭귄의 서식지/종/부리/날개/몸무게/성별 정보를 포함하고 있음
- 불러올 거 불러오고 대애충 처리
1
2
3
4
5
6
7
8
9
10
11
12
13
import matplotlib.pyplot as plt
import pandas as pd
import mlflow
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import roc_auc_score, plot_roc_curve, confusion_matrix
penguins = penguins.dropna(axis=0, how = 'any')
le = LabelEncoder()
penguins['species_encoded']= le.fit_transform(penguins['species'])
penguins['island_encoded']= le.fit_transform(penguins['island'])
penguins['sex_encoded']= le.fit_transform(penguins['sex'])
MLflow Tracking 기본
⛳ 나머지 정보들로 수컷인지 암컷인지 예측
- 학습/테스트 데이터셋 생성
1
2
3
4
5
6
7
features=['bill_length_mm', 'bill_depth_mm','flipper_length_mm', 'body_mass_g','island_encoded', 'species_encoded']
X = penguins[features]
y = penguins['sex_encoded']
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
sc = StandardScaler()
scaled_x_train = sc.fit_transform(x_train)
scaled_x_test = sc.transform(x_test)
- 첫번째로 3가지를 로깅해볼 겁니다.
- 모델의 평가 지표 →
mlflow.log_metric- 학습 정확도, 평가 정확도, AUC
- 테스트 결과와 관련된 플랏(이미지) →
mlflow.log_artifact- ROC 플랏과 컨퓨전 매트릭스 히트맵
- 모델 자체 →
mlflow.log_artifact
- 모델의 평가 지표 →
- 따라서 다음과 같이 학습 및 평가 함수를 구성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def train(model, x_train, y_train):
model = model.fit(x_train, y_train)
train_acc = model.score(x_train, y_train)
mlflow.log_metric("train_acc", train_acc)
print(f"Train Accuracy: {train_acc:.3%}")
def evaluate(model, x_test, y_test):
eval_acc = model.score(x_test, y_test)
preds = model.predict(x_test)
auc_score = roc_auc_score(y_test, preds, multi_class='ovr')
mlflow.log_metric("eval_acc", eval_acc)
mlflow.log_metric("auc_score", auc_score)
print(f"Auc Score: {auc_score:.3%}")
print(f"Eval Accuracy: {eval_acc:.3%}")
roc_plot = plot_roc_curve(model, x_test, y_test, name = 'ROC Curve')
plt.savefig("roc_plot.png")
plt.show()
plt.clf()
conf_matrix = confusion_matrix(y_test, preds)
ax = sns.heatmap(conf_matrix, annot=True, fmt='g')
plt.title('Confusion Matrix')
plt.savefig('conf_matrix.png')
mlflow.log_artifact("roc_plot.png")
mlflow.log_artifact("conf_matrix.png")
- 이제 실제 모델을 훈련/평가해보는데, 기본적으로 하나의 Experiment 안에서 여러 번 run을 돌릴 수 있는 구조라고 보면 됩니다. 따라서
mlflow.set_experiment로 하나의 실험이다 라고 세팅해준 다음mlflow.start_run으로 이번 실행을 시작합니다. with 문 안에서 학습과 평가가 이루어지면 됩니다!
1
2
3
4
5
6
7
8
model = LogisticRegression()
mlflow.set_experiment("/Users/your_id/penguin_logistic_regression")
with mlflow.start_run():
train(model, scaled_x_train, y_train)
evaluate(model, scaled_x_test, y_test)
mlflow.sklearn.log_model(model, "logistic_regression")
print("Model run: ", mlflow.active_run().info.run_uuid)
mlflow.end_run()
![]()
저장된 걸 확인하고 모델 불러오기
- 자 저장한 건 어디서 보나요? Databricks를 사용한다면 3가지 방법으로 저장된 실험 결과 ui에 접근할 수 있습니다.
맨 좌측에 Experiments 탭

내가 실험 세팅 때 지정한 경로의 (코드상
Users/your_id/~ ) 디렉토리에
run을 실행한 노트북 셀 하단에 링크도 생겨 있음 (사실 이게 제일 쉬워요.)

- 그러면 우리는 이런 화면들을 만나게 됩니다.
- 실험의 전체 실행들을 볼 수 있고
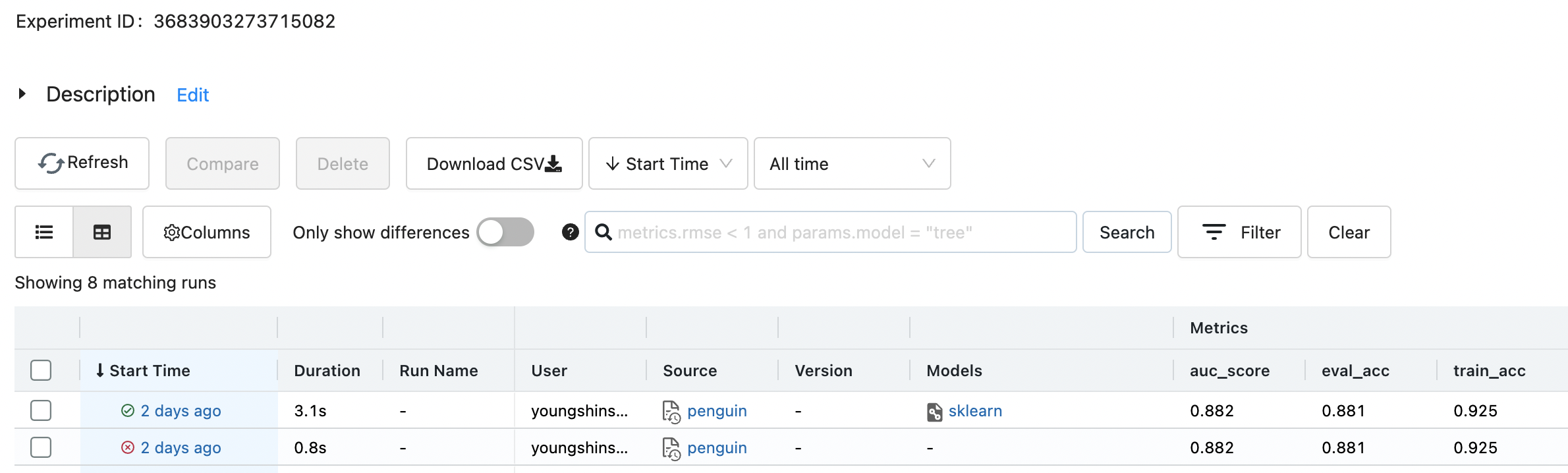
- 특정 실행의 정보를 볼 수 있고
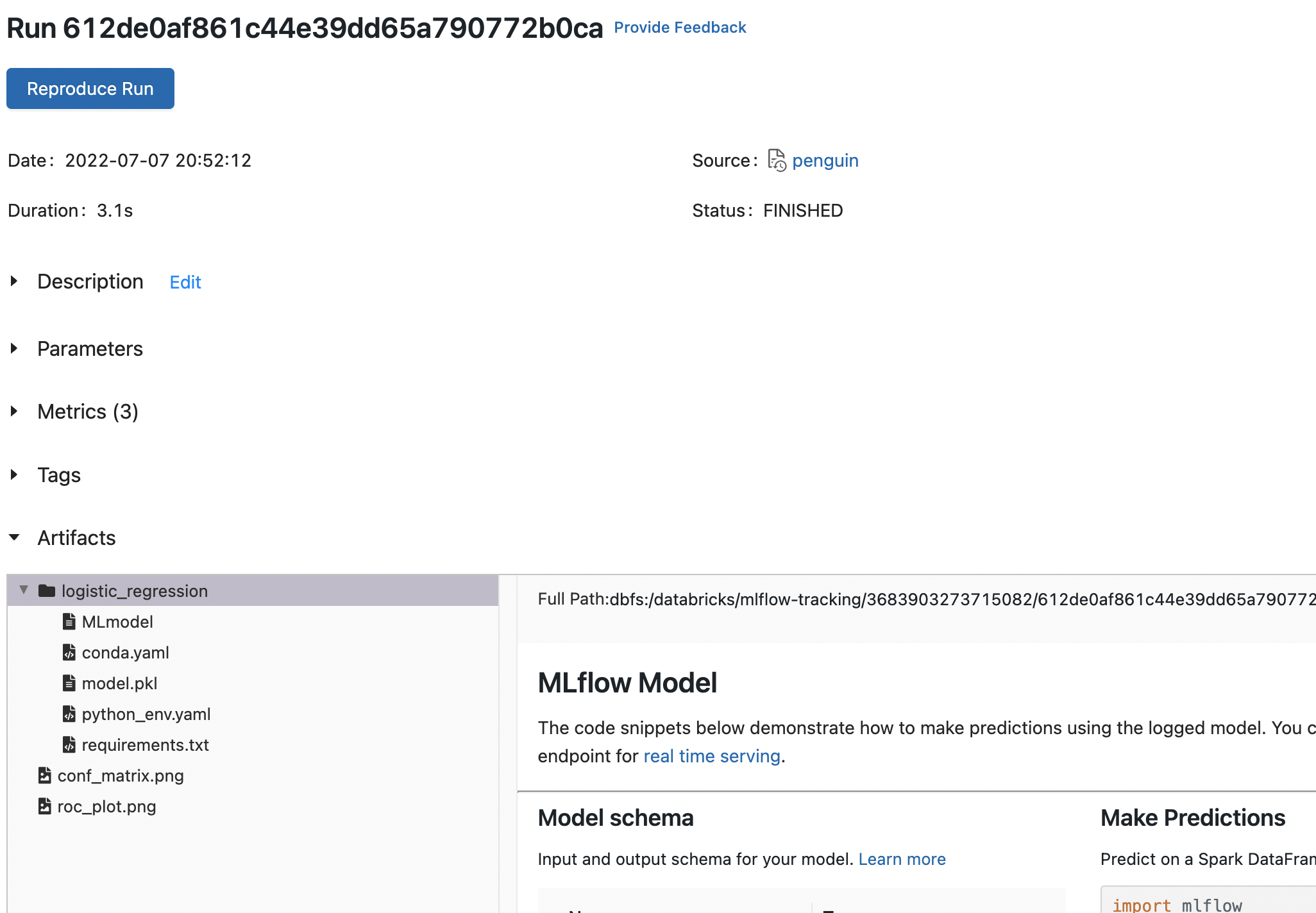
- 우리가 저장한 Metrics 3개를 확인할 수 있습니다.
- Artifacts에는 모델과 플랏도 잘 저장된 것 같습니다.
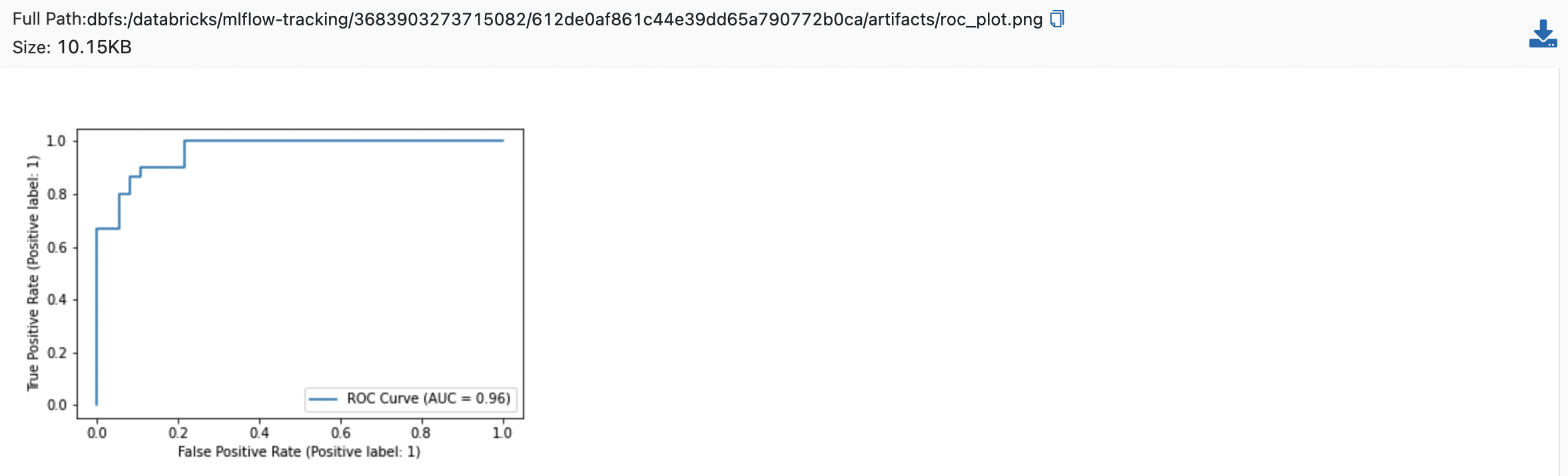
- 실험의 전체 실행들을 볼 수 있고
- 저장한 모델은 어떻게 불러올까요?
mlflow.sklearn.load_model()을 쓰면 간단하게 저장된 모델을 불러와서 다시 사용할 수 있는데요. 모델 경로를 따로 저장해두지 않았다면 저 위의 화면에서 모델을 누른 다음 Full Path를 베껴오면 됩니다. 플랏을 불러올 때도 마찬가지고요.1 2
loaded_model = mlflow.sklearn.load_model("dbfs:/databricks/mlflow-tracking/3683903273715082/18e2bcc166cf4e259fb45944295208a3/artifacts/logistic_regression") loaded_model.score(scaled_x_test, y_test)

- 점수를 출력해보면, 아까 실행할 때와 동일한 점수를 확인해볼 수 있습니다.
파라미터 서치
⛳ 나머지 정보들로 몸무게 예측, 근데 파라미터를 그리드 서치 해서 최적의 모델을 찾고 싶다.
- 다시 XY 만들기, 필요한 거 불러오기
1
2
3
4
5
6
7
8
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
features=['bill_length_mm', 'bill_depth_mm','flipper_length_mm','sex_encoded','species_encoded','island_encoded']
X = penguins[features].values
y = penguins['body_mass_g'].values
- MLflow로 metrics와 artifacts 뿐 아니라 모델 파라미터도 기록할 수 있습니다. 간단하게 파라미터 그리드서치를 해보겠습니다. 대상은 릿지 회귀의 alpha 값입니다.
- 사실 아까처럼 명시적으로
mlflow.log_parameter()해줄 수도 있는데요. 이번엔 하나하나 명시해주지 않아도 보다 간단하게 많은 정보를 기록해주는sklearn.autolog()를 써보겠습니다.
- 사실 아까처럼 명시적으로
1
2
3
4
5
6
7
8
9
10
11
mlflow.sklearn.autolog()
parameters = {'alpha':[0.05, 0.1, 0.5, 1, 2, 5]}
model = Ridge()
ridge_reg = GridSearchCV(model, parameters, scoring='neg_mean_squared_error',cv=5)
mlflow.set_experiment("/Users/your_id/penguin_ridge_regression")
with mlflow.start_run() as run:
ridge_reg.fit(X, y)
mlflow.end_run()
- 이렇게 한번의 실행에 제가 지정한 파라미터 그리드만큼의 학습이 이루어진 것을 확인할 수 있습니다.

- autolog 기능으로 저장할 메트릭, 파라미터를 따로 지정하지 않아도 알아서 이렇게 기록해줍니다.
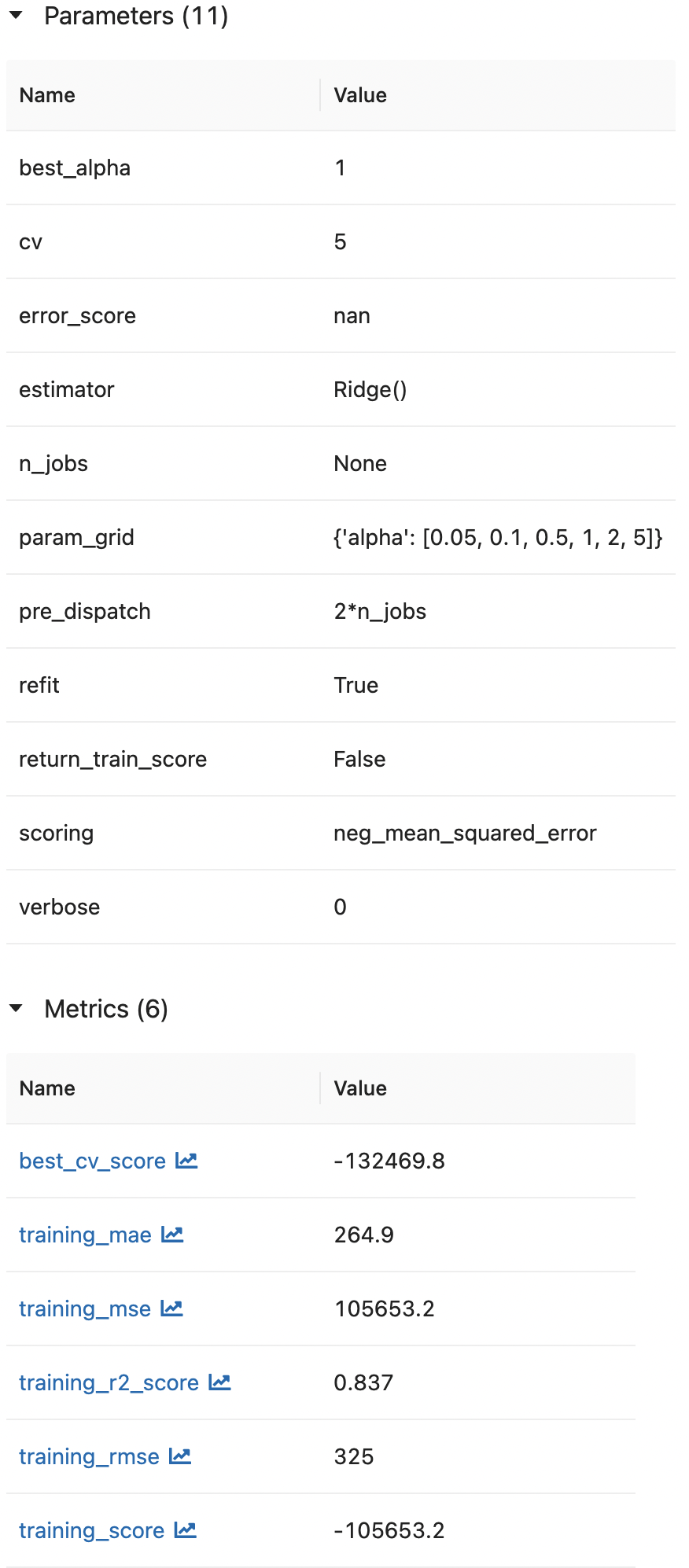
- 최종적으로는 best estimator 모델이 저장됩니다. cv results도 따로 확인할 수 있고요.

- autolog 기능으로 저장할 메트릭, 파라미터를 따로 지정하지 않아도 알아서 이렇게 기록해줍니다.
Pyspark ver.
⛳ 나머지 정보들로 아델리인지 젠투인지 턱끈인지 예측, 근데 pyspark 로 하고 싶다.
- 우선 스파크 DF로 변경하고 필요한 것들을 불러옵니다.
1
2
3
4
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import LogisticRegression
penguins_sdf = spark.createDataFrame(penguins)
VectorAssembler로 피쳐들을 모아주는 부분 빼고 나머지는 사실 이전과 거의 똑같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
features = ['bill_length_mm', 'bill_depth_mm','flipper_length_mm', 'body_mass_g','island_encoded', 'sex_encoded']
va = VectorAssembler(inputCols = features, outputCol = 'features')
data = penguins_sdf.select(F.col('species_encoded').alias('label'), *feature_list)
trainData, testData = data.randomSplit([0.8, 0.2])
trainData = va.transform(trainData)
testData = va.transform(testData)
def train(model, train_data):
model = model.fit(train_data)
trainingSummary = model.summary
mlflow.log_metric("train_acc", trainingSummary.accuracy)
print("Training Accuracy: ", trainingSummary.accuracy)
return model
def evaluate(model, test_data):
evaluationSummary = model.evaluate(test_data)
mlflow.log_metric("eval_acc", evaluationSummary.accuracy)
print("Evaluation Accuracy: ", evaluationSummary.accuracy)
lr = LogisticRegression(featuresCol = 'features', labelCol = 'label', maxIter = 10)
mlflow.set_experiment('/Users/your_id/penguin_logistic_regression_pyspark')
with mlflow.start_run():
lr = train(lr, trainData)
evaluate(lr, testData)
mlflow.spark.log_model(lr, "logistic_regression_pyspark")
mlflow.end_run()
![]() 올?
올?
- 모델 로깅 결과 sparkml 모델이 잘 저장된 걸 볼 수 있습니다.
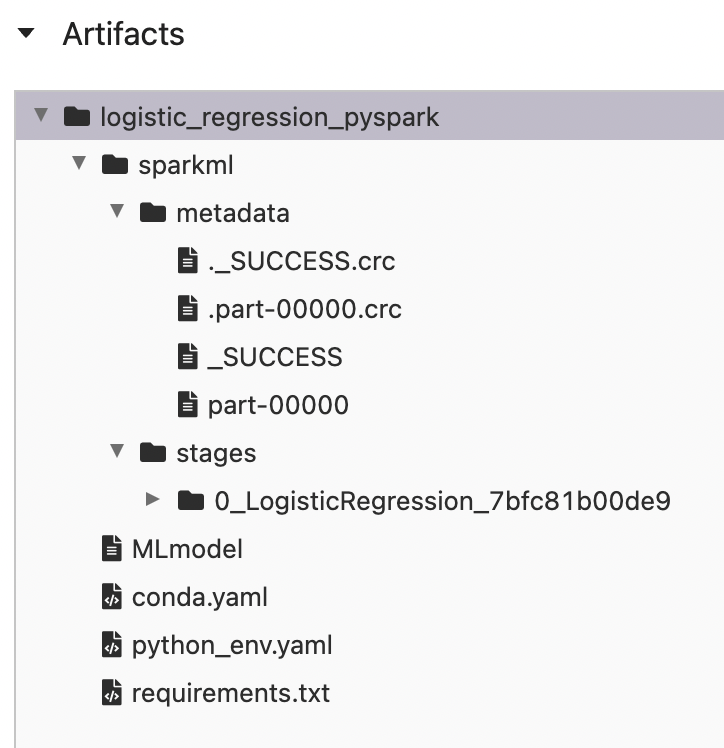
같은 실험인데 그룹별로 나눠서 할래
⛳ 라벨을 쓰지 않고 클러스터링을 할 건데 파라미터를 실험해보고 싶다. 근데 데이터에 나오는 섬이 3개인데 섬마다 딱 맞는 파라미터가 다를 것 같아서 섬 별로 나눠서 하고 싶다.
- (TMI) 사실 이게 제가 MLflow를 써서 해보고 싶었던 태스크와 직접적으로 연관이 있는 찐 찐 목적입니다.
- 일단 어떻게 할 건지 설명은 이렇습니다.
- 클러스터링도 해도 돼? : 사실 처음에 남의 코드를 복붙하고 싶은 강렬한 희망사항이 있었는데 안타깝게도 클러스터링 mlflow 치면 아무것도 안 나옵니다. 하지만 안 될 건 딱히 없는 게 커스텀 메트릭도 얼마든지 로깅할 수 있고 클러스터링도 평가지표들이 많기 때문입니다.
- 내가 쓰고 싶은 알고리즘이 sparkml에 없는데 어떡해? : 그럼 그냥 UDF 쓰고 그 안에서 mlflow run 하면 됩니다.
- 그룹별로 파라미터 실험은? : groupBy 로 pandas UDF을 쓰면서 mlflow run을 하는데, nested run 을 하면 됩니다. 즉 하나의 섬 (예를 들면 Biscoe 섬)에서의 실행이 parent run이 되고, 파라미터값이 0.1일때의 run이 child run이 되도록 합니다.
- 말이 길었으므로 코드로 보여드리면 (하지만 코드가 더 김)
- Pandas UDF를 작성한다.
- 이 안에서는 펭귄이 서식하는 섬 별로 클러스터링(DBSCAN)을 수행하는데 이때
- MLflow run 안에서
- 주어진 파라미터 (eps 값) 순서대로 수행하면서 로깅한다.
- 여러가지 커스텀 지표를 로깅한다.
- sklearn이 제공하는 클러스터링 평가 지표들과 S-Dbw
- 평가지표는 아니지만 만들어진 클러스터의 개수와 노이즈가 아닌 클러스터로 분류된 데이터의 개수도 궁금하니까 로깅한다.
- 각 실험의 결과를 담은 스파크 데이터프레임을 리턴하도록 한다.
- MLflow run 안에서
- 이 안에서는 펭귄이 서식하는 섬 별로 클러스터링(DBSCAN)을 수행하는데 이때
- Pandas UDF를 작성한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
from pyspark.sql.functions import pandas_udf, PandasUDFType
from sklearn.cluster import DBSCAN
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
from s_dbw import S_Dbw
return_schema = T.StructType([
T.StructField('island', T.StringType()),
T.StructField('eps', T.FloatType()),
T.StructField('silhouette', T.FloatType()),
T.StructField('calinski-harabasz', T.FloatType()),
T.StructField('davies-bouldin', T.FloatType()),
T.StructField('s-dbw', T.FloatType()),
T.StructField('n_clusters', T.IntegerType()),
T.StructField('n_clustered_records', T.IntegerType()),
T.StructField('model_path', T.StringType())
])
def clustering(pdf: pd.DataFrame) -> pd.DataFrame:
island = pdf['island'].iloc[0]
run_id = pdf['run_id'].iloc[0]
feature_list = ['bill_length_mm', 'bill_depth_mm','flipper_length_mm', 'body_mass_g']
X = pdf[feature_list].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
n_clusters_list = []
n_clustered_records_list = []
slh_list = []
island_list = []
model_path_list = []
for eps_val in eps_list:
island_list.append(island)
with mlflow.start_run(run_id=run_id):
with mlflow.start_run(run_name=str(island)+'-eps'+str(eps_val), nested=True) as run:
mlflow.log_param("eps", eps_val)
model = DBSCAN(eps=eps_val, min_samples=3)
model.fit(X_scaled)
labels = model.labels_
num_labels = len(set(labels[labels>=0]))
if num_labels -1 >= 1 :
clustered_label = labels[labels>=0]
clustered_data = X[np.where(labels>=0)[0]]
clustered_data_cnt = len(clustered_data)
#scores
slh = silhouette_score(clustered_data, clustered_label)
ch = calinski_harabasz_score(clustered_data, clustered_label)
db = davies_bouldin_score(clustered_data, clustered_label)
s_dbw = S_Dbw(X_scaled, labels, alg_noise='filter')
else:
slh = -1
ch = -1
db = -1
s_dbw = -1
clustered_data_cnt = 0
mlflow.sklearn.log_model(model, str(island)+str('-')+str(eps_val))
mlflow.log_metric("silhouette", slh)
mlflow.log_metric("calinski-harabasz", ch)
mlflow.log_metric("davies-bouldin", db)
mlflow.log_metric("s-dbw", s_dbw)
mlflow.log_metric("n_clusters", num_labels)
mlflow.log_metric("n_clustered_records", clustered_data_cnt)
artifact_uri = f"runs:/{run.info.run_id}/{island}" + str(eps_val)
model_path_list.append(artifact_uri)
n_clustered_records_list.append(clustered_data_cnt)
n_clusters_list.append(num_labels)
slh_list.append(slh)
ch_list.append(ch)
db_list.append(db)
sdbw_list.append(s_dbw)
returnDF = pd.DataFrame({'island':island_list, 'eps':eps_list, 'silhouette': slh_list, 'calinski-harabasz':ch_list, 'davies-bouldin': db_list, 's-dbw':sdbw_list, 'n_clusters':n_clusters_list, 'n_clustered_records':n_clusters_list, 'model_path':model_path_list})
return returnDF
- 메인 부분은 간단합니다. 리턴된 데이터프레임을 통해 ui로 보지 않아도 실험 결과들과 모델 경로를 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
with mlflow.start_run(run_name="섬 별 클러스터링") as run:
run_id = run.info.run_uuid
eps_list = [0.1, 0.2, 0.3, 0.5, 0.7, 0.9, 1.1, 1.3, 1.5]
modelDF = (penguins_sdf
.withColumn("run_id", F.lit(run_id))
.groupby("island").applyInPandas(clustering, schema = return_schema)
)
display(modelDF)
![]()
- 물론 Experiments 탭에서도 이전과 똑같이 확인할 수 있고요.
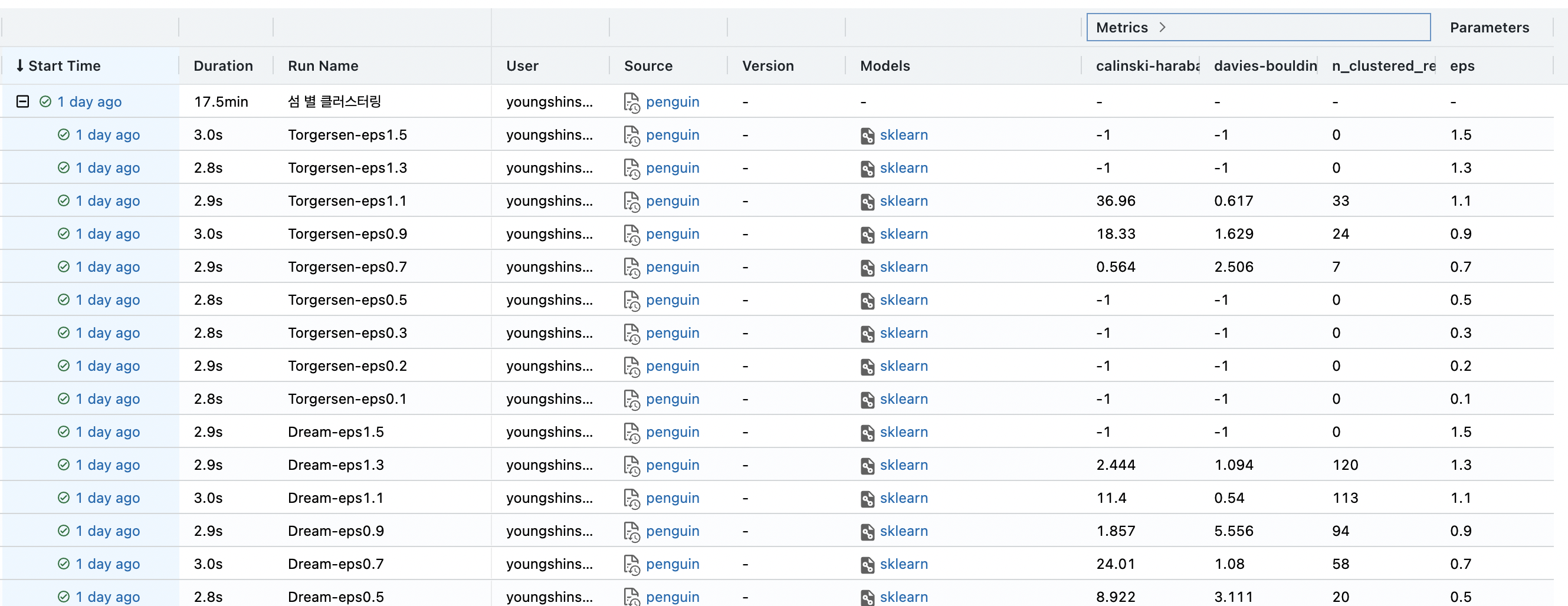
- 어떤 평가지표를 사용하느냐에 따라 다르지만, 만약 s-dbw가 낮은 걸 고르겠다면 Biscoe에서의 eps값과 Dream에서의 eps 값은 다르게 설정되어야 할 것 같습니다.
- 같은 섬에서 파라미터 값에 따른 평가지표 값을 비교해볼 수도 있습니다. 데이터브릭스의 기본적인 플랏 기능을 사용해봤습니다.
1
display(modelDF.filter(F.col('island')=='Dream').orderBy('eps'))
![]()
참고한 책과 글
- MLFlow를 활용한 MLOps
- (사족: 몇달전에 충동구매한 책인데 묵혀두고 있다가 이번에 급하게 참고하기는 나쁘지 않았으나 두께에 비해 내용이 엄청 풍부하진 않아요. 그냥 구글링해서 나오는 문서들이 나을 수도)
- Manage and Scale Machine Learning Models for IoT Devices
This post is licensed under CC BY 4.0 by the author.