라벨은 없지만 이상치는 찾고 싶어
자기지도학습(Self-Supervised Learning)으로 이상치를 탐지하는 방법을 제시한 논문(Learning and Evaluating Representations for Deep One-class Classification)를 읽어 봅니다. 제목은 베스트셀러처럼 지어 봤습니다.
(들어가기 전) 라벨 유무에 따른 이상치 탐지 방법들
일반적으로 라벨이 전부 주어져 있는 학습 데이터를 사용하여 모델을 훈련시키는 것을 지도학습(Supervised Learning)이라고 부릅니다. 이상치 탐지를 할 때는, 이상인 데이터와 이상이 아닌 정상 데이터의 라벨이 모두 달려 있는 경우를 말하겠죠. 정답이 완전히 주어져 있다면 당연히 그 정답을 기반으로 훈련시킨 모델의 정확도도 높아집니다.
문제는 어떤 경우든 간에 데이터 라벨링에는 상당한 비용이 소모되는 데다가, 설사 우리가 자원이 충분하여 모든 데이터에 라벨링을 할 수 있더라도 이상치는 (그 정의 상) 필연적으로 정상치에 비해 그 수가 매우 적을 수밖에 없다는 것입니다. 즉 만약 지도학습 방식을 사용하고 싶다면 매우 높은 수준의 라벨 불균형이 가장 먼저 해결해야 하는 이슈가 됩니다. 10만 개 중 1개 꼴로 이상치가 나온다면, 현실적으로 모델이 학습할 만한 개수의 이상치 라벨을 모으긴 어려울 것입니다.
그래서 이상치 탐지에서는 주로 준지도학습 또는 비지도학습 방식을 많이 사용합니다. 가능한 접근을 요약하면 다음과 같습니다.
- 준지도학습 (Semi-supervised Learning)
- 정상치 데이터들만 가지고 이 데이터들을 둘러싸는 경계(boundary)를 학습하도록 모델을 훈련시킨다. 이 경계를 벗어나는 데이터를 이상치로 탐지하게 된다.
- 하나의 라벨/클래스(=정상)만 사용하기 때문에 One-Class 분류라고도 한다.
- 비지도학습 (Unsupervised Learning)
- 따로 라벨링 없이 가지고 있는 데이터들이 정상치라고 가정하고 이 데이터들 자체의 특징을 학습하도록 한다.
- 예를 들어 가지고 있는 데이터로 오토인코더를 훈련시키면, 정상 데이터 기반으로 학습되었기 때문에 이상치에 대해서는 디코딩이 제대로 되지 않는 것을 이용해 이상치를 탐지한다.
둘 다 장단점이 있습니다. 준지도학습의 경우 그럼에도 정상치 라벨링이 필요하며 지도학습에 비하면 정확도가 떨어질 수 있겠고, 비지도학습은 라벨링 비용 없이 좋은 결과를 낼 수 있는 방법이지만 오토인코더와 같은 모델은 파라미터 설정에 큰 영향을 받기도 합니다.
(그리고 완전히 분류를 하기 애매한 부분도 있는데요. 예를 들면 대표적인 One-Class 분류 방식인 OC-SVM은 실제로 정상 데이터만 수집해서 사용할 수도 있지만 ‘이상치는 말 그대로 발생 빈도가 매우 낮은 이상치이기 때문에 내 데이터도 높은 확률로 다 정상치일 것이다’라는 가정 하에 라벨링 없이 적용할 수도 있습니다. 반대로 비지도학습 설명에서 언급된 오토인코더를 사용한 방식 역시 정상치로 라벨링이 이미 된 데이터에 사용할 수 있고, 그렇게 되면 성능이 더 보장되기도 하겠죠.)
어쨌든 오늘 읽어 볼 논문은, 이 두 가지를 결합하여 자기지도학습(Self-supervised Learning)을 통한 이상치 탐지 방식을 제안한 내용입니다.
Learning and Evaluating Representations For Deep One-Class Classification
이 논문이 제시하는 방식은 2개의 단계로 이어지는데요, 처음에는 자기지도학습으로 representation을 얻고, 그 다음에 기존에 널리 알려진 one-class 분류 알고리즘을 적용하는 것입니다.

논문에서는 첫번째 단계에서는 rotation prediction 또는 contrastive learning를, 두번째 단계에서는 OC-SVM 또는 KDE를 사용했지만, 사실 이 방식은 어떤 특정 representation learning 방식이나 one-class 분류기에만 한정된 것은 아니며 사용자가 원하는 대로 다양한 알고리즘을 적용할 수 있는 확장성이 장점입니다.
이어서 각 단계에서 사용한 방법들을 간단히 살펴보도록 하겠습니다.
1. Self-Supervised Representation Learning
Rotation Prediction
- 논문: Unsupervised Representation Learning By Prediction Image Rotations
- Pretext 방법의 일종으로, 간단히 말하면 우리가 정의한 특정 문제를 모델이 푸는 과정에서 데이터의 표현을 학습할 수 있도록 하는 것이다.
- 이 경우에는, 인풋 이미지를 회전시킨 각도를 예측하는 것을 모델에게 과제로 준다.
- 몇 도 돌렸을까? (0, 90, 180, 270) 클래스 4개짜리 분류 문제 → 회전 각도를 알아보려면 이미지의 물체의 위치와 특징을 알아야 한다.

- ImageNet Classification 기준으로 기존의 다른 pretext 이용 비지도학습 기반 표현 학습 모델들에 비해 더 뛰어난 성능을 보였다고 한다.
- 몇 도 돌렸을까? (0, 90, 180, 270) 클래스 4개짜리 분류 문제 → 회전 각도를 알아보려면 이미지의 물체의 위치와 특징을 알아야 한다.
Contrastive Learning
- SimCLR로 알려진 방법
- 대조 학습은 그 이름대로 각 이미지에 서로 다른 변환을 적용한 뒤, 같은 이미지로부터 나온 positive pair와 다른 이미지로부터 나온 negative pair를 구분하도록, 즉 positive pair의 임베딩 벡터는 유사하고 negative pair의 임베딩 벡터는 멀어지도록 모델을 학습시키는 것이다.
- 다양한 방식의 이미지 변환

- 저 위의 회전 각도 예측이나 직소 퍼즐 문제처럼 pretext task를 설정하는 방식은 해당 과제를 벗어나면 일반화 성능이 떨어지는 편인데, 대조학습은 그에 비해 이미지의 일반적인 시각적 특징을 잘 잡아내는 것으로 알려져 있다.
- 다양한 방식의 이미지 변환
- 다만, 이상치 탐지 분야에서는 이 contrastive learning의 결과물이 다소 문제가 있는데, 그것은 바로 아래 그림의 (a)와 같은 representation의 uiformity다. 표현 공간 상에서 데이터가 아래처럼 균등하게 퍼져 있을 때 우리의 2단계인 one-class classifier를 적용하면, (대부분의 분류 알고리즘은 테스트 데이터가 얼마나 정상치와 가까운지를 보고 이상치 여부를 판단하기 때문에) 이상치도 정상치와 상당히 가까운 것으로 나타날 수 있다.
- 이 문제를 해결하는 방법: 훈련 데이터를 뒤집거나 회전시킨 것을 더 추가해줌으로써 인위적으로 훈련 데이터가 균등하게 분포하지 않도록 바꿔주면 된다. 사실 그냥 데이터 증강과 비슷하지만 분포 증강(distribution augmentation)이라는 말을 쓴다. - 그림(c)
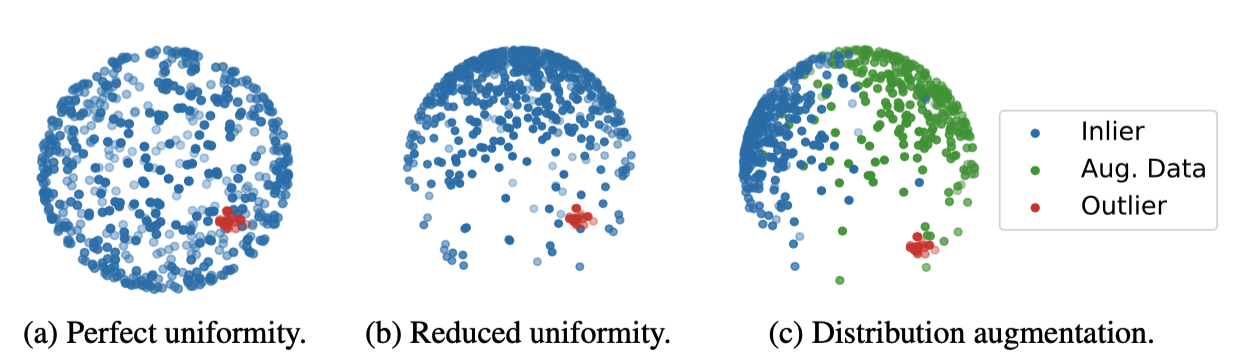
- 이 문제를 해결하는 방법: 훈련 데이터를 뒤집거나 회전시킨 것을 더 추가해줌으로써 인위적으로 훈련 데이터가 균등하게 분포하지 않도록 바꿔주면 된다. 사실 그냥 데이터 증강과 비슷하지만 분포 증강(distribution augmentation)이라는 말을 쓴다. - 그림(c)
2. One-Class Classification
OC-SVM (One Class Support Vector Machine)
- 논문: Support Vector Method for Novelty Detection
- 일반적인 SVM이 주어진 클래스들을 가장 큰 마진으로 갈라놓는 hyperplane을 찾는 것처럼, OC-SVM은 주어진 데이터들을 원점과 가장 잘 분리하는 최대 마진의 hyperplane을 찾고
- 그 support vector를 기준으로 해서 이상치로 판단한다.
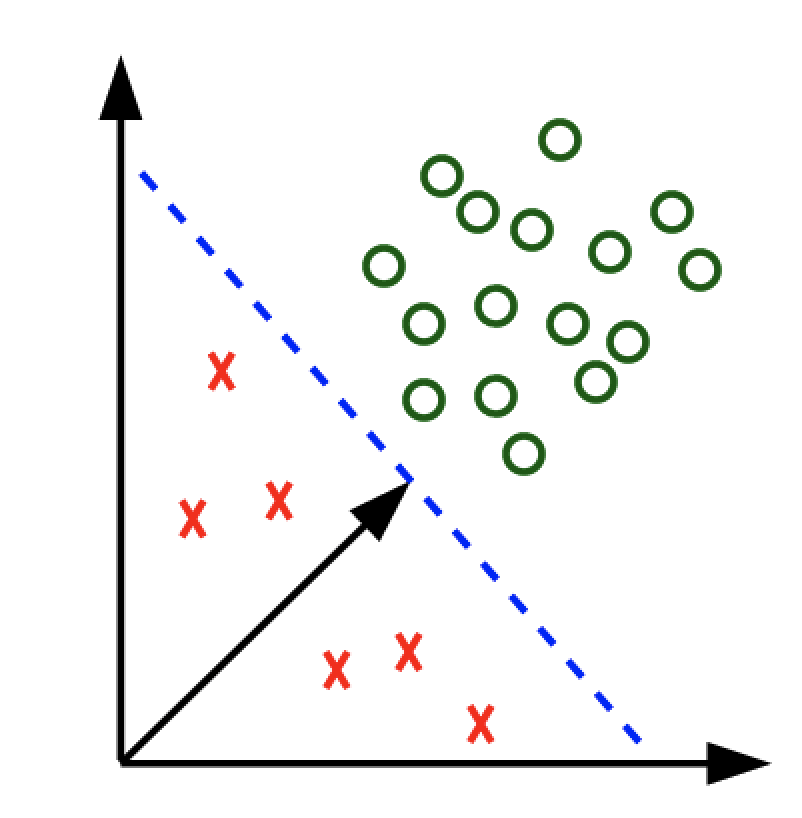
- 그 support vector를 기준으로 해서 이상치로 판단한다.
KDE (Kernel Density Estimation)
- KDE는 분포에 대한 가정 없이 non-parametric하게 확률 밀도 함수를 추정하는 방식이다.
- 전반적인 확률 밀도 함수 추정과 KDE에 대한 설명 참고
- 이를 이용해 이상치를 탐지하는 방식의 기본적인 아이디어는 정상치들의 확률 밀도 함수를 추정해 본 다음에, 이 함수 상으로 확률이 아주 작은, 즉 정상치의 분포 상에서는 등장하기 매우 어려운 관측치는 이상치로 판단하는 것이다.
성능
이제 실험 결과(AUC 값)을 살펴봅시다. CIFAR-10/100, fashion MNIST, Cat-vs-Dog, CelebA, MVTec AD 와 같은 데이터셋에서 SOTA 수준의 좋은 성능을 보였다고 합니다. 대부분 데이터셋이 2개 이상의 클래스를 지닌 이미지 데이터셋인데, one-vs-all 방식으로 각 클래스에 대해 해당 데이터를 정상치로 보고 다른 클래스에 속하는 데이터는 이상치로 간주했다고 보면 됩니다. (ex.고양이 클래스에 대해서는 고양이가 정상치, 그 외의 모든 동물은 이상치)
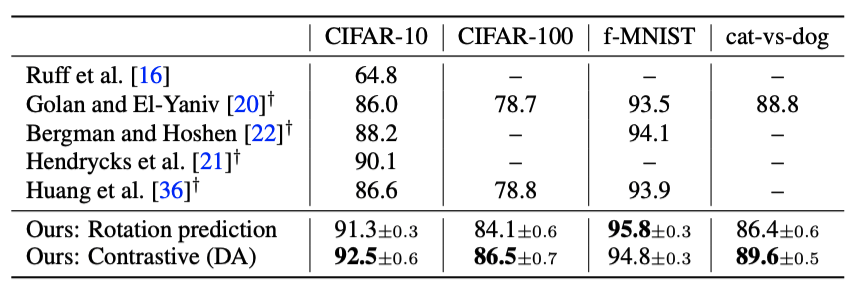
Rotation prediction의 경우 전반적으로 KDE와의 조합이 OC-SVM에 비해 성능이 좋았고, 따라서 위 표에 기술된 값도 2단계에서 KDE를 사용했을 때의 값입니다.
Contrastive learning의 경우 위에 서술한 것처럼 Distribution augmentation을 했을 때가 기존의 uniform한 분포를 보정하지 않았을 때보다 성능이 좋았으며, 대부분의 데이터셋에서 KDE보다는 OC-SVM과 조합했을 때 성능이 미세하게 더 좋았습니다. 따라서 위 표에 기술된 값도 추가 데이터 증강(DA) 후 2단계에서 OC-SVM을 사용했을 때의 값입니다.
모든 데이터셋에 대한 성능을 평균 낸 값은 Contrastive learning + Distribution augmentation + OC-SVM조합이 가장 좋았고, 그 값은 89.9입니다.
비교한 선행 연구들은 다음과 같습니다.
- Deep one-class classification → SVDD(Support Vector Data Description), OC-SVM과 유사하되 hyperplane이 아닌 hypersphere 수준에서 적용한 방법.
- Deep anomaly detection using geometric transformations → 회전이나 뒤집기 등 이미지 변환을 통해 변환을 맞히도록 하는 분류기를 학습하고 잘 예측하지 못하면 이상치로 탐지하는 자기지도학습 방법.
- Classification-based anomaly detection for general data → 위 방식을 이미지 외의 데이터로 일반화함.
- Using self-supervised learning can improve model robustness and uncertainty → 자기지도학습이 robustness, uncertainty 모두를 개선할 수 있다는 측면에서 이상치 탐지를 태스크 중 하나로 포함.
- Inverse-transform autoencoder for anomaly detection → 오토인코더를 사용한 원 데이터의 복구가 잘 되지 않는 경우 이상치로 탐지하는 방법.
테스트 데이터가 전부 공통적이진 않지만 어쨌든 전반적으로 이전 방식들에 비해 뛰어난 성능을 보이고 있습니다. 어떤 연구들인지 간략히 서술해 두었지만, 간단히 말하면 이 이전 방식들이란 완전히 비지도학습(자기지도학습만)으로 접근하거나 one-class 분류 모델만 사용한 경우들입니다.