그래프 DB - Cypher 기초

그래프 데이터베이스의 질의 언어인 Cypher를 처음부터 따라해 볼 수 있는 가이드입니다. 데이터 생성, 검색, 변경, 삭제에 필요한 기초 구문들을 배웁니다.
그래프DB - Cypher 기초
이전에 그래프 데이터베이스 Neo4j에 대해 소개글을 쓴 적이 있습니다. 그 글에서는 그래프 DB에 대한 간단한 설명, Neo4j 샌드박스 DB 생성과 연결까지만 다뤘었는데요. 오늘은 그 DB에 어떻게 쿼리를 날릴지 좀 더 자세히 배워봅니다. Neo4j는 Cypher라는 그래프 모델에 특화된 선언적 질의 언어를 사용합니다. 생긴 건 SQL과 비슷한데, 저는 사실 SQL도 업무에서 잘 안 써서 다른 언어 대비 사용이 느린 편이므로 완전히 처음 보는 마음으로 이 Cypher라는 언어를 한 번 봐 보겠습니다.
예시 DB
Sandbox DB 리스트 중 Movie DB를 골라봤습니다. 연결이 되면 다음과 같이 DB 정보를 간단하게 확인할 수 있습니다.
이전 글에서 다뤘듯 그래프를 구성하는 것은 노드(Node)와 관계(Relationship) 이며, 우리는 좌측의 DB 정보를 통해 다음과 같은 사실을 알 수 있습니다.
- 노드는 라벨을 가질 수 있다.
- 라벨에는
Movie와Person이 있는 걸로 보아 여기 있는 노드들은 모두 영화이거나 사람(배우, 감독 등)이다.
- 라벨에는
- 관계는 타입을 가진다.
- 관계 타입에는
ACTED_IN,PRODUCED,DIRECTED등이 있다. - 예를 들면 영화 매트릭스에 대해 워쇼스키들은 감독했고(
DIRECTED) 키아누 리브스는 출연했다(ACTED_IN).
- 관계 타입에는
- 노드와 관계는 프로퍼티(속성)를 가질 수 있다.
- 프로퍼티는 키와 값으로 이루어져 있는데, 키에는
born,name,rating,released등이 있다. - 예를 들어 매트릭스는 1999년에 개봉했다 =
{released:1999}라는 프로퍼티를 가진다. 라나 워쇼스키는 1965년에 태어났다 ={born:1965}라는 프로퍼티를 가진다.
- 프로퍼티는 키와 값으로 이루어져 있는데, 키에는
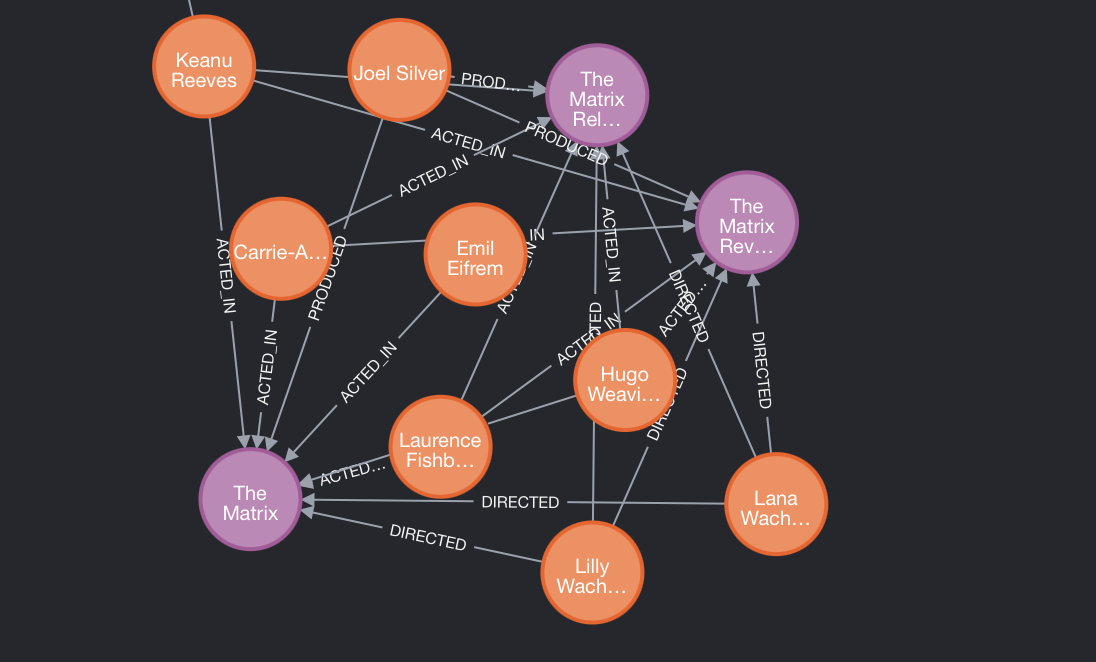 그래프의 일부
그래프의 일부
기초 구문
기본 syntax 알아보기 (노드, 관계, 패턴)
- 노드의 표현
()를 사용. 필요시 안에 변수명/프로퍼티/라벨을 포함한다. 아무 정보도 포함하지 않으면 특정되지 않은 노드를 의미한다.
1 2 3
(gonegirl) (gonegirl: Movie) (gonegirl: Movie {title: 'Gone Girl', released:2014})gonegirl이라는 변수에 지정해서 다음에 다른 부분에서 사용할 수 있다.변수명:라벨+ 키와 값의 형태로 프로퍼티(Title과released)를 저장한다.
- 관계의 표현:
--를 쓰되, 만약 방향성이 있다면<--처럼 화살표를 붙여준다.- 변수명/프로퍼티/타입을 표현하고 싶다면
[]를 사용하는데, 주의점은 대시 2개 사이에 와야 한다는 것이다.
1 2 3
--> -[role:ACTED_IN]-> -[role:ACTED_IN {roles:['Amy']}]->- 이번에도
role이라는 이름의 변수로 지정했다. ACTED_IN이라는 타입의 관계이며, 배역 이름이 Amy라는 프로퍼티(roles)도 정해줬다.
조금 전에 그래프DB를 기본적으로 구성하는 요소는 위의 노드와 관계라고 했습니다. 여기서 조금 더 나아가서 패턴이라는 개념을 생각해 보겠습니다. 공식 문서에 따르면 노드와 관계는 저레벨의 레고블락 같은 것이고, 1개 이상의 노드와 관계가 모아져서 만들어지는 패턴이 바로 Neo4j 데이터 구조의 핵심이라고 합니다. 하나의 노드나 관계에 담을 수 있는 정보는 매우 적지만 만약 다양한 패턴을 구성하게 된다면 매우 복잡한 정보들을 쉽게 저장하고 조회하고 처리할 수 있다고 하네요.
패턴을 표현하는 방법은,
- 간단한 패턴 (1개의 노드와 1개의 관계로 구성)
벤 애플렉은 나를 찾아줘라는 영화에 출연했다. (배역 이름: Nick)
1
(ben:Person:Actor {name: 'Ben Affleck'})-[role:ACTED_IN {roles: ['Nick']}]->(gonegirl:Movie {title: 'Gone Girl'})다음처럼
acted_in이라는 이름의 변수를 지정할 수도 있다.1
acted_in = (ben:Person)-[:ACTED_IN]->(gonegirl:Movie)
- 살짝 더 복잡한 패턴 (관계와 노드가 1개씩 더 늘어난다면)
길리언 플린은 나를 찾아줘라는 소설을 썼는데 그 소설은 동명의 영화로 만들어졌다.
1
(:Person:Writer {name:'Gillian Flynn'})-[:WROTE]->(:Book {title: 'Gone Girl'})-[:MADE_INTO]->(:Movie {title:'Gone Girl'})
- 점점 더 복잡한 패턴 (그래프 DB가 필요한 이유)
- 길리언 플린은 나를 찾아줘라는 소설을 썼는데 그 소설은 동명의 영화로 만들어졌고 그 영화에는 벤 애플렉이 출연했는데 벤 애플렉은 딥 워터라는 영화에 출연했고 딥 워터의 원작은 심연이라는 소설인데 그 소설은 퍼트리샤 하이스미스가 썼고 퍼트리샤 하이스미스의 이토록 달콤한 고통이라는 소설이 출간될 때 길리언 플린이 추천사를 썼다.
- 이 패턴을 그래프가 아닌 다른 형태로 표현한다면?
 대체 뭔소리예요 그게 뭔소리냐고
대체 뭔소리예요 그게 뭔소리냐고- 하지만 그래프로는 이 패턴을 좀 알아보기 쉽게 표현할 수 있지 않을까?
- 길리언 플린은 나를 찾아줘라는 소설을 썼는데 그 소설은 동명의 영화로 만들어졌고 그 영화에는 벤 애플렉이 출연했는데 벤 애플렉은 딥 워터라는 영화에 출연했고 딥 워터의 원작은 심연이라는 소설인데 그 소설은 퍼트리샤 하이스미스가 썼고 퍼트리샤 하이스미스의 이토록 달콤한 고통이라는 소설이 출간될 때 길리언 플린이 추천사를 썼다.
데이터 생성 (CREATE)
제가 만들려는 패턴은 원래 DB에 없기 때문에 한번 만들어보도록 하겠습니다. CREATE 를 사용하면 다음과 같이 새로운 노드 2개와 관계 1개를 만들 수 있습니다.
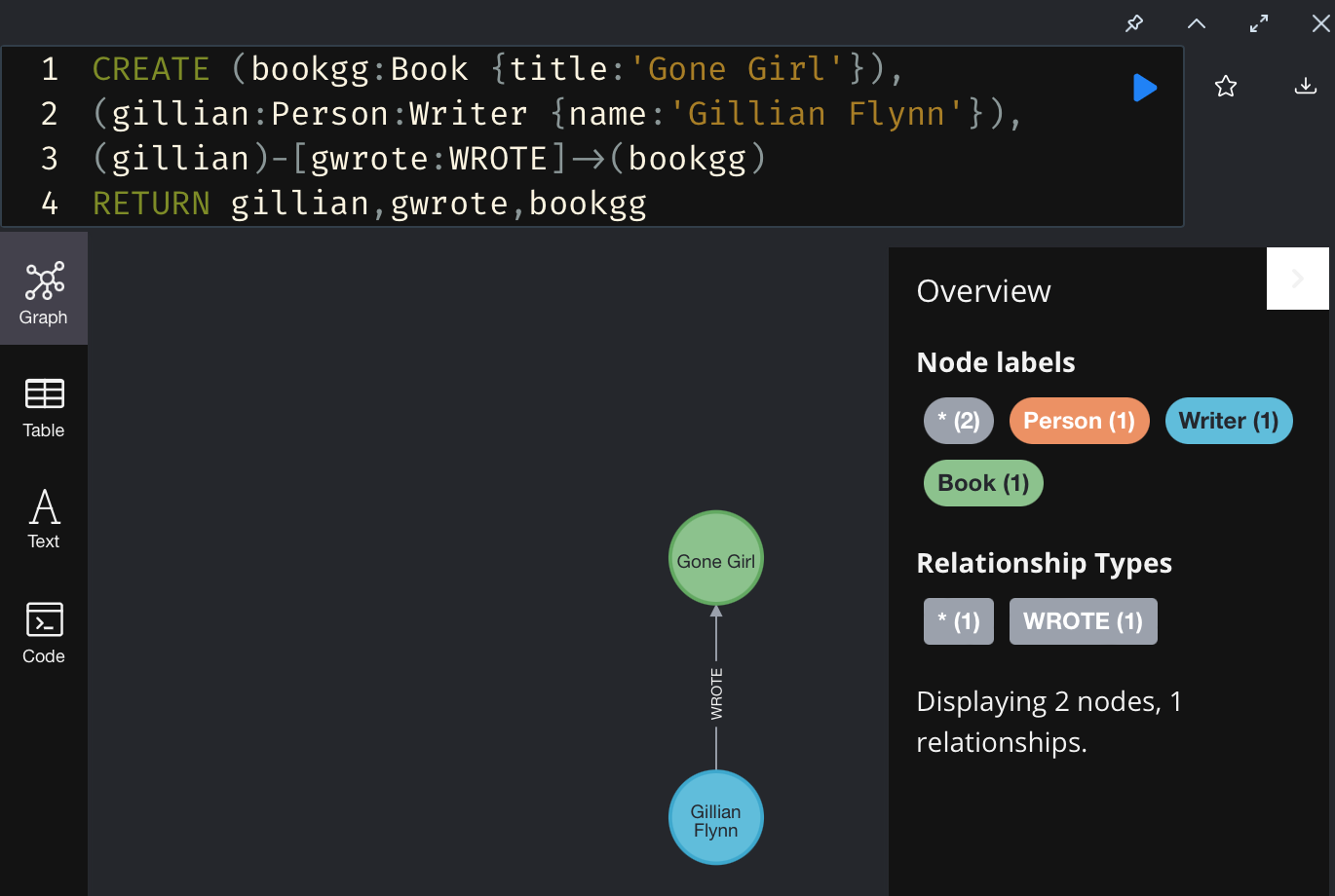
마지막에 RETURN을 사용해서 결과물을 리턴하도록 했습니다.
데이터 검색(MATCH)
MATCH 를 통해 지정된 패턴을 검색할 수 있고, 이때 WHERE를 사용해서 조건을 설정할 수 있습니다.
예를 들어, 길리언 플린이라는 이름을 가진 사람이 쓴(관계 타입: WROTE으로 연결된) 책을 찾고 싶다면 다음과 같이 조회합니다.
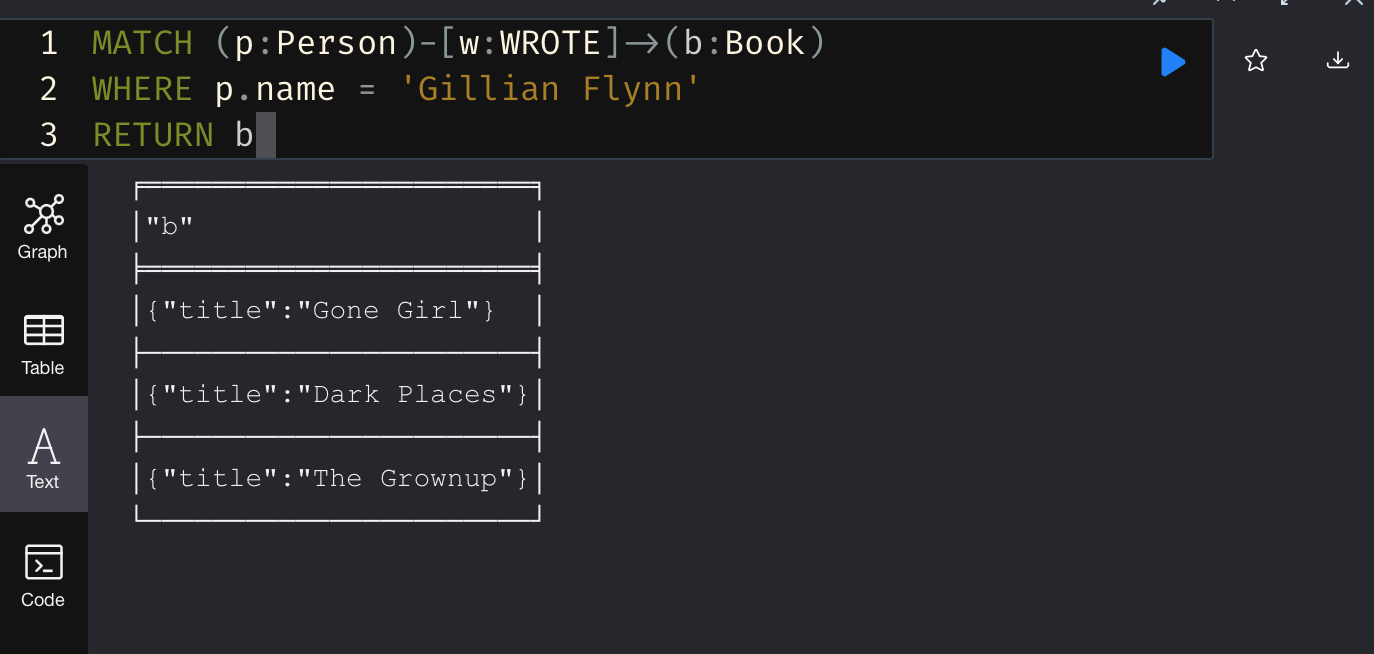 그래프 모양뿐 아니라 이렇게 텍스트로도 조회 결과를 확인할 수 있다.
그래프 모양뿐 아니라 이렇게 텍스트로도 조회 결과를 확인할 수 있다.
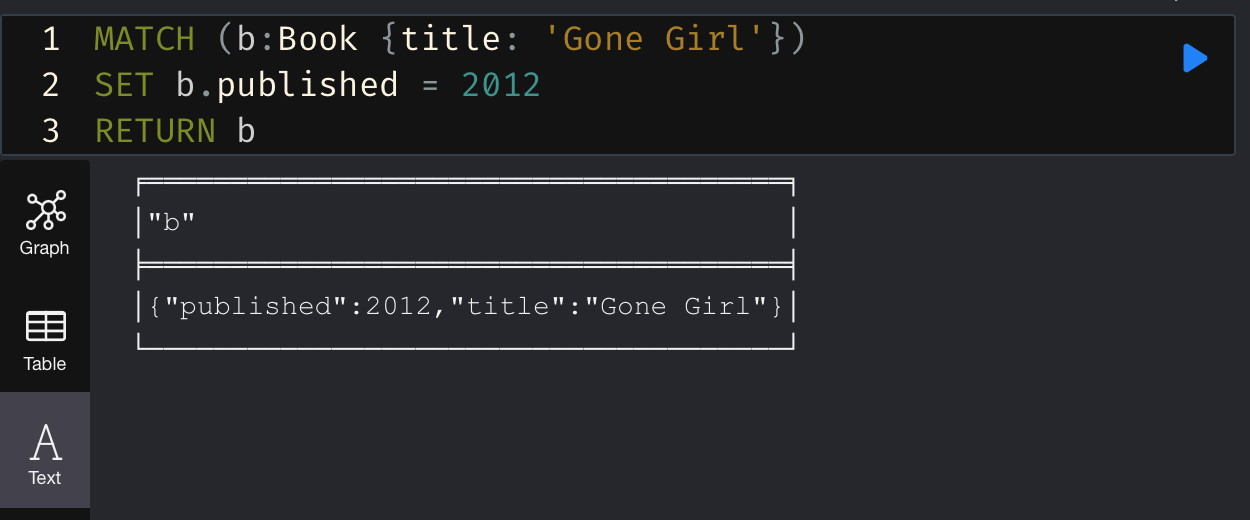
프로퍼티 추가/변경 (SET)
이제 조금 전 만든 노드에 프로퍼티를 추가하고 싶습니다. 나를 찾아줘는 2012년에 출간되었습니다.
데이터 조회와 생성을 한번에 (MERGE)
이제 저는 영화 나를 찾아줘를 추가해보려고 합니다. 그런데 이게 원래 영화 DB 였기 때문에, 그 영화가 이미 DB에 있었는지도 모르겠어요. 이럴 때 MERGE를 사용하면 됩니다. MERGE는 MATCH와 CREATE를 합친 것으로, 만약 만들려는 게 이미 DB에 존재하면 단순히 MATCH로 기능하고, 없으면 CREATE로 기능해서 생성을 해줍니다. (만약 그냥 CREATE를 썼는데 이미 그 노드가 있으면 에러가 나요.)
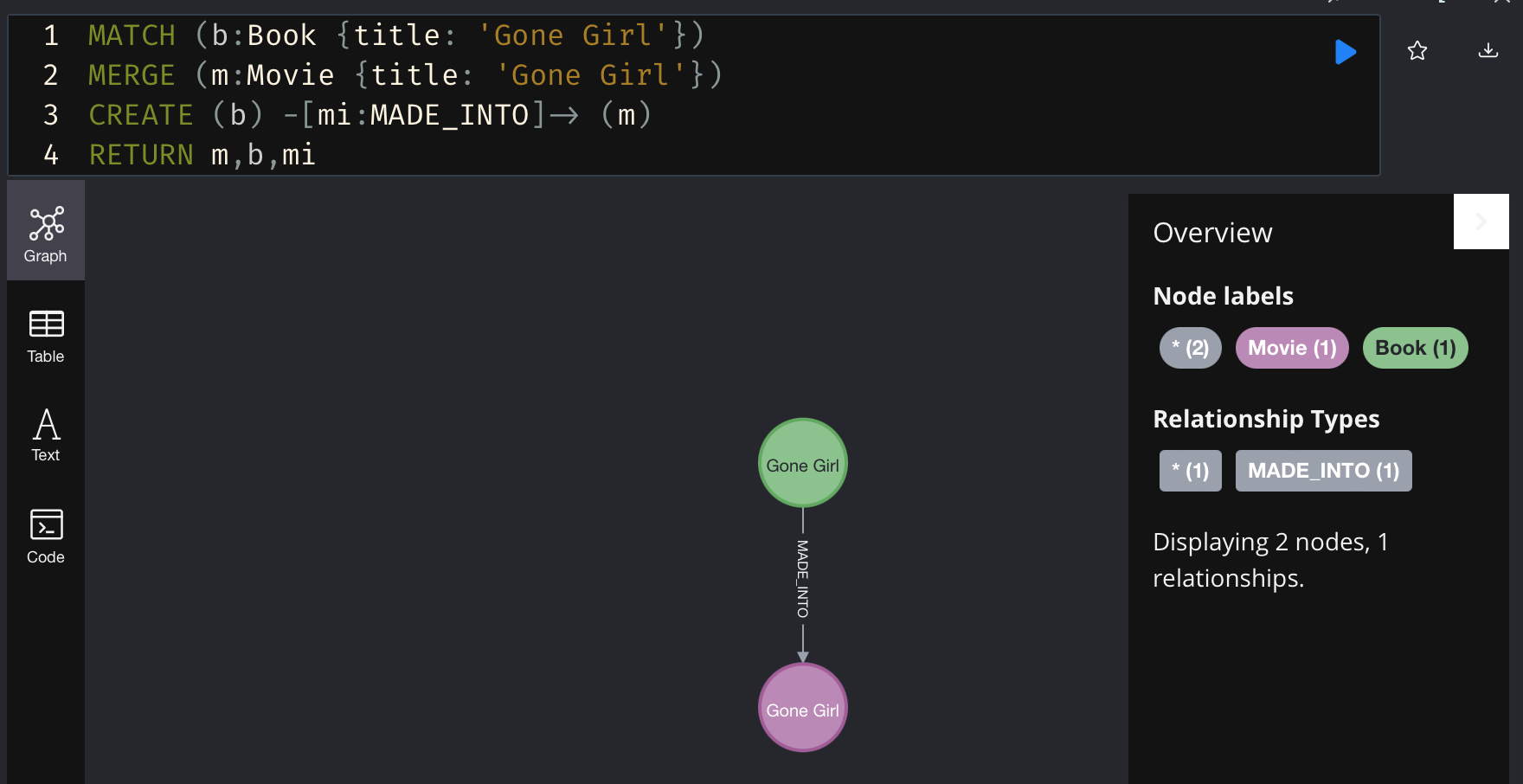 영화가 있으면 그냥 조회, 없으면 생성
영화가 있으면 그냥 조회, 없으면 생성
데이터 삭제(DELETE)
만약에 지우고 싶으면, 나를 찾아줘 노드를 찾아서 연결된 관계까지 다 지웁니다.
 친절하게 몇 개의 노드와 몇 개의 관계를 지웠는지 말해준다.
친절하게 몇 개의 노드와 몇 개의 관계를 지웠는지 말해준다.
최종적으로, 제가 만들고 싶었던 패턴은 이렇게 생겼습니다.
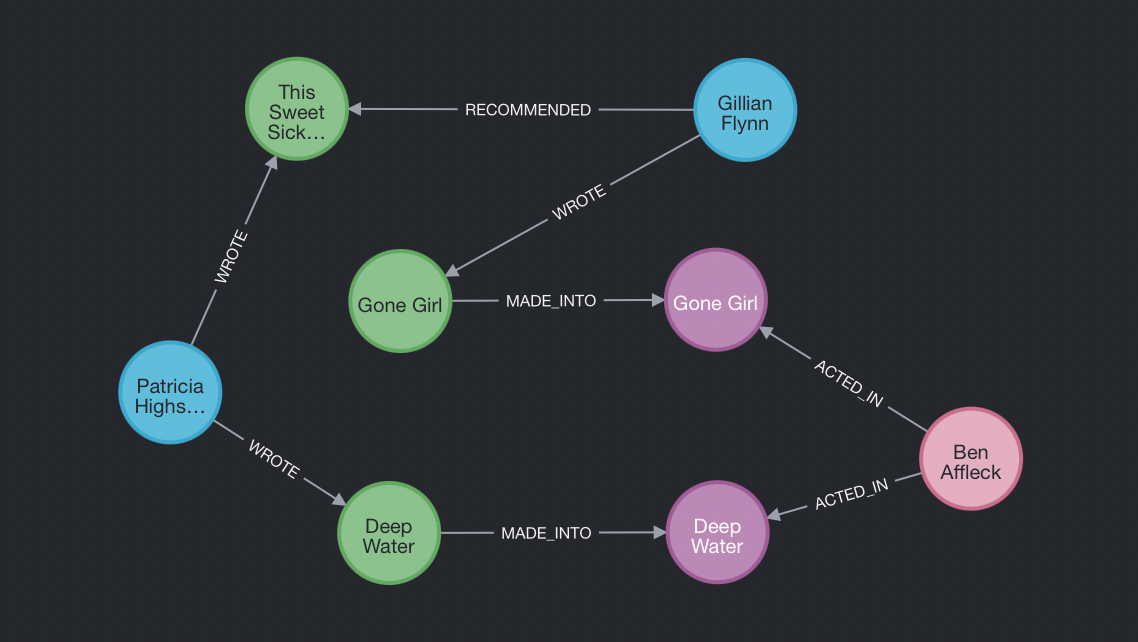
기초는 여기까지입니다. 기본적으로 데이터를 생성, 변형 및 조회할 수 있게 되었으니 다음 스텝은 Neo4j 데이터에 다양한 그래프 알고리즘을 적용해보는 것인데요(경로 찾기, 중심성 계산, 랜덤 워크, PageRank, 연결 요소, 커뮤니티 탐지 등 진짜 웬만한 거 다 됩니다. 참고) 이 내용들은 다음에 다른 글로 자세히 다뤄보도록 하겠습니다.
참고한 글
- 공식 문서 Introduction to Cypher