GPU OOM과 이별하는 법
GPU를 사용한 모델 개발 중 메모리가 모자라다는 문제(CUDA OutOfMemory)에 대한 해결책을 모아보았습니다. 다른 머리 아픈 에러도 많은데 이 친구랑은 오래 보지 않도록 합시다.
GPU 메모리 상황 확인하는 법
OOM이라는 건 마치 어느 날 길에서 붕어빵 사먹고 계좌이체 하려고 송금 버튼을 눌렀는데 야 니 통장 잔고 0원임! 이라는 느닷없는 오류 메시지를 받은 상황이나 다름없습니다. 하지만 지금까지 아무 생각도 기록도 없이 물흐르듯 돈을 쓰고 있었던 입장에서 이런 짧은 정보는 너무 당혹스럽습니다. 돈을 지금까지 어디다 어떻게 쓰고 있었던 건지, 잔고가 텅텅 비기 전에 한 10만원 쯤 남았을 때 미리 알 수는 없었는지 하는 생각들이 듭니다. 일종의 가계부처럼 메모리 사용량을 확인할 수 있는 수단이 필요하겠습니다.
nvidia-smi
nvidia-smi는 터미널에 입력하는 명령어로, 현재 가지고 있는 모든 GPU의 상태와 어떤 프로세스에 얼만큼의 메모리를 쓰고 있는지 보여줍니다.
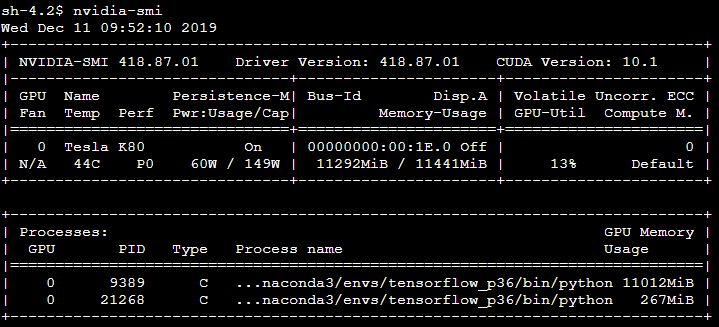
이 경우 GPU가 0번 GPU 1개인 상황이고, 하단의 Processes에 보면 어떤 실행 중인 프로세스가 얼만큼의 메모리를 사용하고 있는지를 볼 수 있습니다. 그 외에도 사용량, 드라이버 버전이나 Fan, 온도 상태, 여러 성능 관련된 지표를 같이 확인할 수 있고요. 특히 GPU-Util의 경우 당장 OOM 상황에서 눈이 안 갈 수 있으나 전반적으로 비싼 리소스를 내가 알차게 잘 뽑아먹고 있는가?라는 관점에서 중요한 값이 되겠습니다.
1
watch -d -n 1 nvidia-smi
위와 같이 -n 1을 입력하면, 값들이 1초마다 업데이트되도록 할 수 있습니다. -d 는 계속 변경되는 부분을 하이라이트 처리 해줍니다.
nvitop
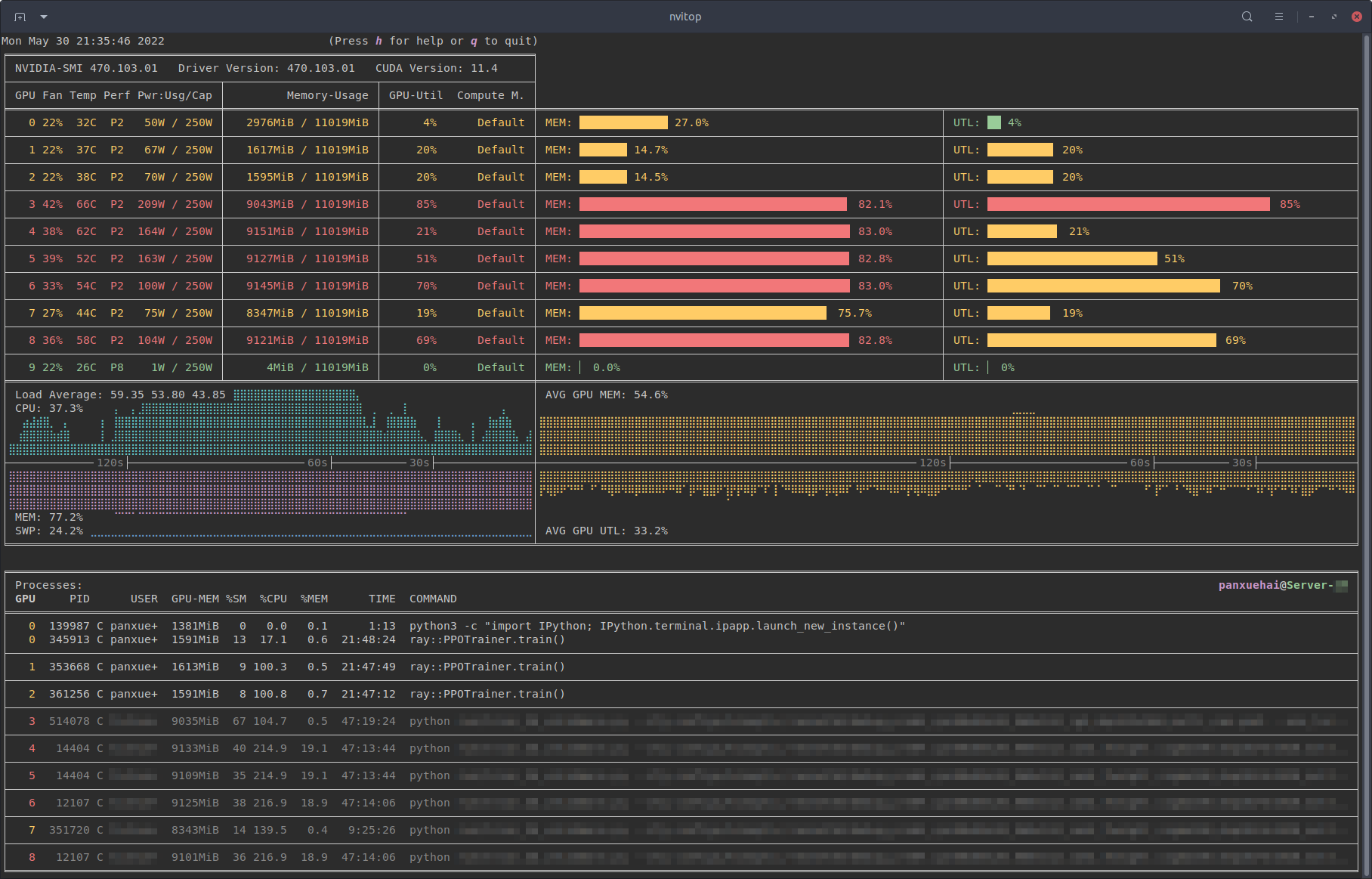
역시 유사한 목적으로 nvidia GPU를 모니터링할 수 있게 해주는 도구입니다. nivida-smi 대비 더 시각적으로 화려하고 보기 편합니다. pip install nvitop 해서 설치할 수 있습니다.
GPUtil
마찬가지로 pip install GPUtil로 설치합니다.
1
2
3
import GPUtil
GPUtil.showUtilization()
그러면 다음과 같은 포맷으로 GPU Util과 memory usage를 출력하고요.
1
2
3
ID GPU MEM
--------------
0 0% 0%
위 두 개의 도구 대비 상당히 간단한 정보이지만 현재 시점의 스냅샷이 아닌 iteration마다 메모리 변동을 계속 출력해서볼 수 있다는 점에서 유용합니다. 다음과 같이 학습 중에 별도의 스레드로 모니터링할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import GPUtil
from threading import Thread
import time
class Monitor(Thread):
def __init__(self, delay):
super(Monitor, self).__init__()
self.stopped = False
self.delay = delay # 몇초간격으로 GPUtil call할건지
self.start()
def run(self):
while not self.stopped:
GPUtil.showUtilization()
time.sleep(self.delay)
def stop(self):
self.stopped = True
monitor = Monitor(10)
monitor.stop() #모니터링 종료할 때
Pytorch API
Pytorch도 메모리 상황에 대해 확인해볼 수 있는 함수를 제공합니다. memory_reserved와 memory_allocated가 있는데, 이 둘 차이를 이해하려면 pytorch의 메모리 할당 방식인 caching memory allocator를 이해해야 합니다. pytorch는 GPU 메모리를 매번 계속 할당하는 대신 우선 큰 block으로 확보(예약)하고, 이 메모리 풀에서 내부적으로 메모리를 분할해서 필요한 GPU 연산에 사용합니다.
torch.cuda.memory_reserved(): pytorch가 미리 예약한 전체 메모리의 양torch.cuda.empty_cache()는 이 예약한 메모리 중 실제로 쓰지 않는 것을 GPU에 반환하는 것임
torch.cuda.memory_allocated(): pytorch가 예약한 메모리 중 실제로 모델이 사용 중인 메모리의 양
가끔 이게 필요한 이유는 pytorch가 찜해두었지만 실제로 쓰지 않는 메모리도 위의 nvidia-smi로 봤을 때는 사용 중으로 나오기 때문입니다. 실제로 pytorch가 내 모델 학습에 쓰고 있는 메모리를 알고 싶다면 memory_allocated를 확인하는 것이 좋습니다.
자 이제 해결 방법들을 두 가지 경우로 나눠서 보도록 하겠습니다.
진짜 메모리가 모자랄 때
첫번째 케이스는 실제로 내 모델 코드가 많은 메모리를 사용하고 있는 상황에서 알뜰하게 아껴 쓰도록 변경하는 방향의 팁들입니다. 물론 더 비싼 GPU를 쓰라는 간단한 해결책은 쓰지 않았습니다. 그렇게 된다면 물론 좋겠지만, 그게 가능했으면 이런 글을 찾아보고 있지 않으셨겠죠. 저도 마찬가지입니다.
다시 가계부 비유로 돌아가서, 돈이 없다는 걸 인지한 후에 앞으로 현재 소비 중 식비에서 줄일지 친구들 만나는 걸 줄일지 그 카테고리를 결정해야 하는 순간이 옵니다. 일반적으로 딥러닝 모델이 어떻게 작동하는지 생각해보면, 보통 학습 과정에서 GPU 메모리는 다음 항목들에 사용됩니다.
- 모델 그 자체 (weights and biases)
- forward pass할 때 - activations (각 레이어의 출력값)
- backward pass할 때 - gradients, optimizer value
모델의 경우, 당연히 작은 모델일수록 저장해야 할 파라미터 수가 적으므로 더 작은 모델을 쓰는 것도 근본적인 해결책으로는 검토해 볼 만하겠지만, 이 부분도 사실 GPU 스펙처럼 건드리기 어려운 상황인 경우가 많습니다. 너무 필수적인 항목이어서 약간 월세 같은 거랄까요. 아무리 돈이 없대도 고시원으로 이사가기는 정말 최후의 수단으로 고려해보는 게 좋겠습니다. 그래서 대부분의 해결책은 forward/backward시 사용되는 메모리를 줄이는 것을 목적으로 합니다.
배치 사이즈 줄이기
가장 단순한 해결책이지만 제일 먼저 점검해볼 만한 가능성입니다. 가용한 메모리에 비해 너무 큰 배치 사이즈를 올리고 있지 않은지 배치 크기를 줄여가면서 OOM이 뜨는지 테스트해볼 필요가 있습니다.
Checkpointing
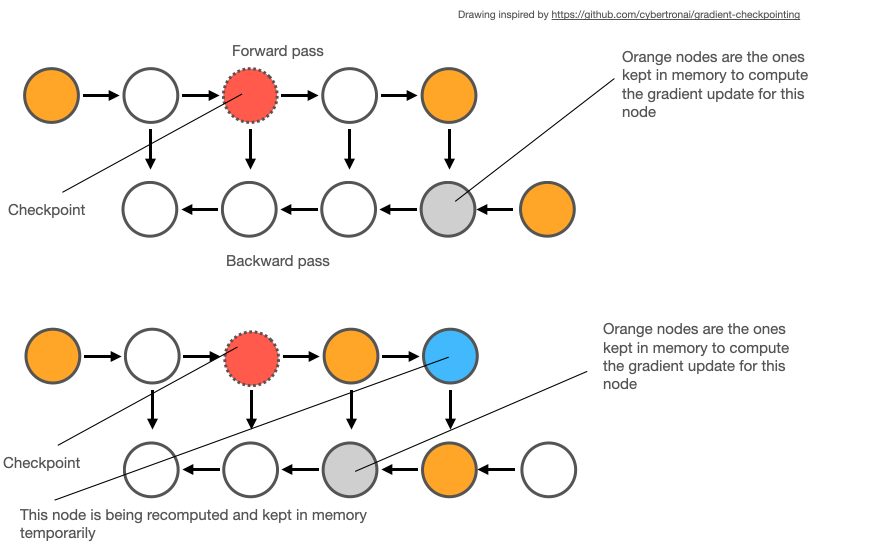
Gradient Checkpointing(또는 Activation Checkpointing)은 forward pass할 때 activation의 일부만을 저장해서 메모리를 절약하는 방법입니다. 만약에 나중에 backward시에 그래디언트를 계산할 때 삭제된 activation 값이 필요하다면 그때 그냥 다시 계산하면 된다! 라는 전략으로, 당연히 메모리를 얻는 대신 (재계산에 쓰이는) 시간을 잃습니다(trade-off).
1
2
3
4
5
6
import torch
from torch.utils.checkpoint import checkpoint
def forward(layer, input):
#### ...
return checkpoint(layer(input))
그래디언트 저장이 꼭 필요하지 않을 때
그래디언트 저장이 필요 없는 상황(추론)에서는 당연히 그래디언트 저장을 하면 안 됩니다.
1
2
with torch.no_grad():
#...
비슷한 맥락에서 반복문에서 사용되는 변수에 대해 꼭 텐서여야 할 필요가 없는 값은 텐서가 아닌 수치형으로 저장하도록 합니다. 텐서로 유지할 경우 단순히 우리가 필요한 그 값만 저장되는 것이 아니라 미분에 필요한 computational graph가 계속 생성되기 때문입니다.
Optimizer 선택
특정 종류의 옵티마이저는 optimizer state를 따로 저장해서 사용해야 합니다. 예를 들어 SGD 같은 경우는 각 파라미터에 대해 파라미터와 그래디언트 외의 다른 값을 저장하지 않고 state의 크기도 파라미터 크기와 동일합니다. 그러나 Adam, AdamW 이런 친구들은 그 방식 상 1차,2차 모멘텀(그래디언트의 이동평균, 제곱 이동평균)까지 저장해야 해서 파라미터의 세 배만큼 공간을 잡아먹습니다. 따라서 메모리가 부족한 상황이라면 메모리를 덜 잡아먹는 optimizer를 쓰는 걸 고려해볼 수 있겠죠. 다만 이 경우에도 당연히 optimizer는 학습의 성능과 안정성에 영향을 끼치기 때문에, 어떤 옵티마이저를 쓰느냐에 따라 그런 부분과 메모리 사이의 trade-off는 발생할 수 있습니다.
Mixed Precision Training
모든 연산에 FP32(32비트 부동소수점)을 사용하지 않고, FP16(16비트 부동소수점)과 섞어서 쓰는 전략입니다. FP16 연산이 속도가 훨씬 빠르고 메모리를 절반만 사용하므로, 모델의 weight나 activiation 텐서 값들은 FP16으로 캐스팅해서 쓰되 손실값처럼 수치적인 안정성이 중요한 값들은 FP32로 쓰는 방식이죠. Pytorch는 Automatic Mixed Precision(AMP)라고 해서 자동으로 Mixed Precision Training을 지원합니다. 사용자가 직접 나는 어떤 부분에서 FP16을 쓰고 어떤 부분에서 FP32를 쓰겠어 라고 만져 줄 필요 없이 pytorch가 적절히 혼합해서 써주는 것입니다.
또 FP16 연산 시 매우 작은 값에 대해서(손실값, 그래디언트값)에 대해 언더플로우가 발생할 수 있고 이로 인해 학습이 제대로 진행되지 않을 수 있기 때문에 loss값에 대해서 일정 배수로 스케일링해서 크게 만든 다음에 그래디언트를 계산하고 backpropagation 이후에 원래 스케일링으로 돌려주는 loss scaling 방식을 사용하기도 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import torch
from torch.cuda.amp import autocast, GradScaler
model = YourModel().cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
scaler = GradScaler() # Loss scaling
for data, target in dataloader:
data, target = data.cuda(), target.cuda()
with autocast():
output = model(data)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
청소는 그때그때
이건 꼭 GPU 메모리에만 해당되는 말은 아니지만 필요 없어진 변수는 del로 그때그때 정리하는 것이 최선입니다. 불필요하게 for문에서 중간변수를 쌓고 있다면 반복이 끝나면 지워주고요. 유의해야 할 점은 del은 해당 변수와 메모리 간의 관계를 끊는 것이고 할당된 메모리를 없애 주는 게 아니라는 것입니다. 해당 메모리 주소는 사용하지 않는 캐시가 되며, 이런 부분들은 잘 비워줘야 합니다. 🗑️
1
torch.cuda.empty_cache()
사실 메모리가 모자란 건 아닐 때
두번째 케이스는 실제로는 내 모델이 메모리를 탈탈 털어서 쓰고 있다기보단 살짝 다른 결의 문제가 있는 케이스입니다. 학습 이제 막 시작했는데 그렇게 큰 모델/데이터도 아닌데 갑자기 메모리가 없다고? nvidia-smi 띄워봐도 프로세스 실행 중인 거 없는데 시작하자마자 메모리가 없다고? 🤯
좀비 프로세스 킬하기
일단 nvidia-smi를 입력했을 때 뭔가 메모리를 많이 쓰고 있는 프로세스가 보인다면 다음과 같이 킬을 해버리면 됩니다.
1
kill -9 [PID]
[PID] 값에는 nvidia-smi에서 확인되는 PID(프로세스 ID) 값을 넣어주면 됩니다. -9 시그널은 강제 종료한단 의미입니다.
그런데 Processes 항목에 아무것도 안 보이는데 자꾸 OOM이 뜨기도 합니다. 이전에 실행되었던 무언가가 메모리를 차지하고 있는데 명확히 뭔지 안 보이는 상황인 거죠. 특히 주피터 노트북 환경에서 실행 중인 셀을 키보드 인터럽트로 중단시키는 걸 여러 번 반복하면 이전에 실행하던 학습이 메모리 할당만 받고 제대로 종료되지 않는 현상이 발생할 가능성이 커집니다.
이럴 때는 다음과 같이 해당 GPU에서 실행되고 있는 모든 python 프로세스를 날려버릴 수 있습니다.
1
for i in $(sudo lsof /dev/nvidia0 | grep python | awk '{print $2}' | sort -u); do kill -9 $i; done
nvidia0: 0번 GPU를 사용하고 있을 경우 (메모리를 정리하고 싶은 GPU를 입력)grep python: python 프로세스를 검색awk '{print $2}': process id를 알아내서sort -u: 정렬, 중복제거- 알아낸 모든 process에 대해 반복문으로 강제종료
메모리 조각화 이슈
다음 케이스는 진짜 이전에 뭘 실행한 적이 없고(프로세스가 쌓일 리가 없고) 방금 띄운 커널에서 학습 시작하자마자 메모리가 없다는 경우입니다. 이 경우 메모리 조각화(memory fragmentation)이 발생했을 확률이 높습니다. 메모리 공간이 파편화된 상태로 사용되어 빈 공간이 연속적이지 않아서 우리가 필요한 만큼 텐서를 저장할 공간이 없어지는 것을 의미합니다. pytorch가 큰 사이즈의 메모리를 예약해둔 뒤 학습 과정에서 동적으로 메모리를 할당하기 때문에 발생하는 문제입니다.
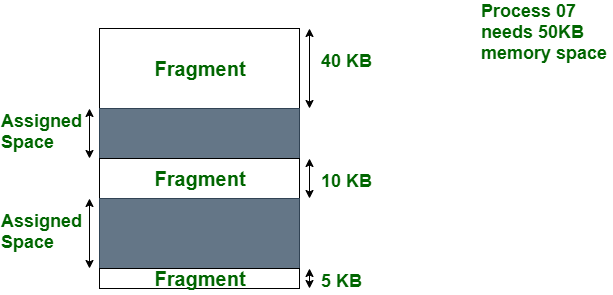 사실 다 합치면 필요한 만큼의 공간이 있지만 쪼개져 있어서 사용할 수가 없음(그림 출처)
사실 다 합치면 필요한 만큼의 공간이 있지만 쪼개져 있어서 사용할 수가 없음(그림 출처)
이 문제를 해결할 수 있는 옵션이 max_split_size_mb입니다. 이 옵션은 pytorch가 예약하는 메모리 풀의 크기를 제한해서 더 작은 크기의 블록으로 예약을 나누도록 합니다. 따라서 왕창 예약해놓고 비연속적으로 끊어서 쓰는 상태를 방지하고, 만약 예약한 메모리보다 부족하다면 다른 블록을 예약해서 별도로 사용하도록 해서 낭비하는 공간 없이 털어서 쓰게끔 하는 거죠. 이 옵션을 사용할 때의 주의할 점(제가 처음 이 옵션을 알았을 때 실수했던 점)은 만약 이 값을 줄여서 메모리 풀을 작게 했다면 내 모델 코드에서 실제로 한번에 메모리에 올리는 양도 같이 줄여줘야 한다는 점입니다. 블록이 작은데 여기에 큰 배치 사이즈가 올라가면 OOM이 뜨는 건 똑같습니다. 그리고 이 값을 너무 작게 가져가게 되면 여러 메모리 블록을 관리하는 오버헤드가 발생할 수 있고 오히려 성능이 떨어질 수도 있다는 점을 유의해서, 적절히 변경해가며 실험을 해보는 것을 추천합니다.