GPT가 내 일자리를 뺏을 가능성은?

GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models (2023) 를 읽어보았습니다.
AI가 우리 일자리를 뺏어갈까? 라는 질문은 사실 AI라는 단어가 나오면서부터 계속 화두였습니다. 딱히 신선한 질문은 아니고, 굉장히 오래된 불안거리라는 소리죠. 오늘은 Large Langaue Model(이하 LLM)이 여러 분야의 노동 시장에 미칠 영향을 들여다 본 OpenAI의 논문을 가져왔습니다.
우선 이 논문의 제목은 GPT는 GPT다 인데요. 이게 무슨 동어반복이지? 싶은데, 여기서 앞의 GPT와 뒤의 GPT는 다른 뜻입니다.
- 앞 GPT: Generative Pre-trained Transformer (이하 그냥 GPT)
- OpenAI가 개발한 LLM, 요즘 지겹게 듣는 그 GPT
- 뒤 GPT: general-purpose technologies (이하 범목적기술)
- 전세계적으로 & 전체 산업 분야로 퍼진, 혁신적인 변화와 진보를 일으킨 기술을 말함
- 예를 들면 인쇄술이나 증기기관
즉 이 논문이 대답하고자 했던 것은 현 GPT-4 수준의 LLM이 과연 인쇄술이나 증기기관에 버금가는 영향력을 지닌 기술인가? 라는 질문이고, 결론부터 말하면 그렇다! 라고 답을 냈다고 볼 수 있습니다. 그 답까지 가는 과정을 한번 살펴보겠습니다.
사용한 데이터
- O$*$NET (미국의 직업 정보 시스템) 데이터베이스
- 총 1,016개의 직종에 대해 각각의 상세 직업 행동(Detailed Work Activities)과 작업(task)을 포함한 데이터
- DWA란 예를 들면, “프로젝트 요구 사항을 결정하기 위해 스크립트를 공부한다”와 같은 각 직종에서 특정 작업에 필요한 세부 행동을 의미함
- 하나의 작업은 여러 개의 DWA로 이루어질 수 있음
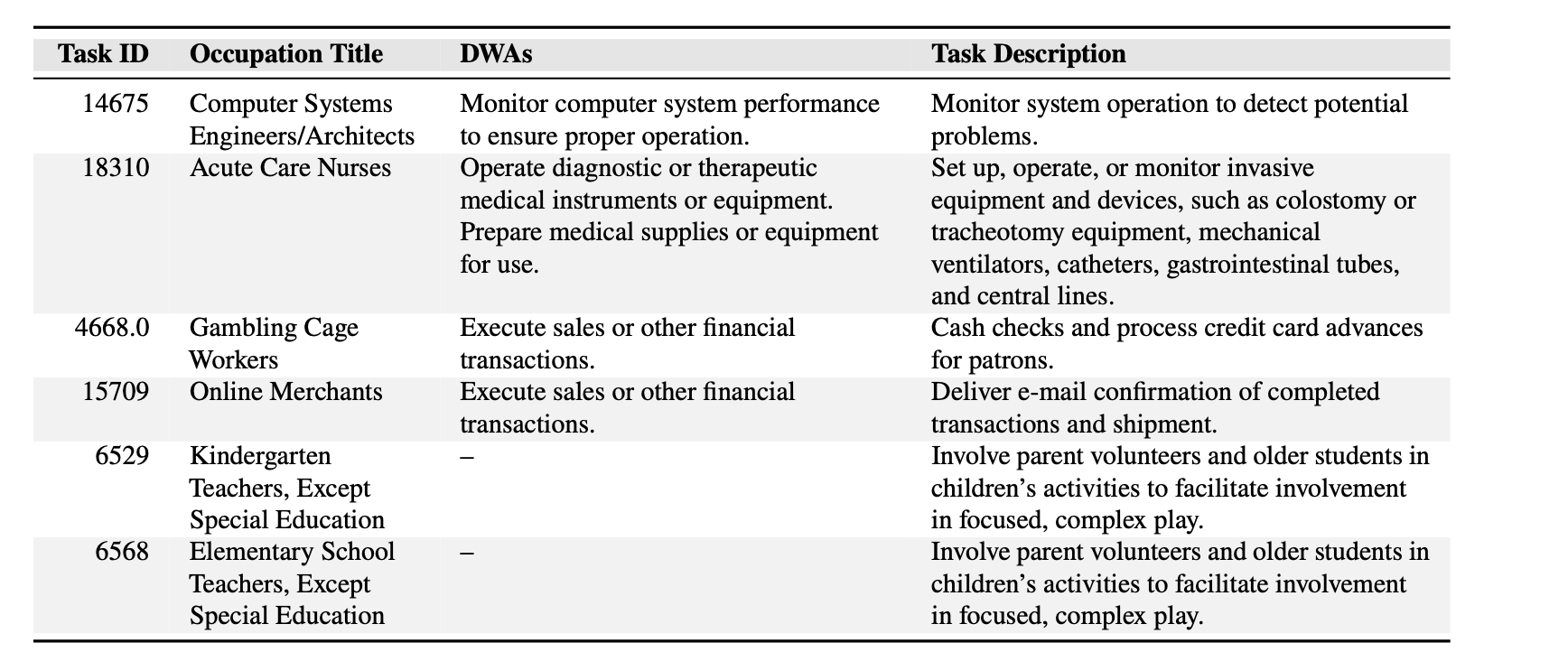 Task 와 DWA의 예시. 재미있는 점은, DWA가 같더라도 직종에 따라 그걸 온라인으로 하는지 면대면으로 하는지 달라질 수 있음(Gambling Cage Worker와 Online Merchant)
Task 와 DWA의 예시. 재미있는 점은, DWA가 같더라도 직종에 따라 그걸 온라인으로 하는지 면대면으로 하는지 달라질 수 있음(Gambling Cage Worker와 Online Merchant)
- 총 1,016개의 직종에 대해 각각의 상세 직업 행동(Detailed Work Activities)과 작업(task)을 포함한 데이터
- 노동청 통계의 고용 및 임금 데이터
- 각 직종의 노동자 수, 2031년 고용 예측치, 직종 진입을 위한 평균적인 교육 수준과 OJT 수준까지 포함
연구 방식
- 노출(Exposure)라는 개념을 정의
- LLM으로 대체당할 위험에 대한 노출이라고 직관적으로 이해하면 편함
- 어떤 일을 하면서 LLM을 이용할 때 결과의 질을 일정하게 유지하되 절반 이상 작업 시간이 단축되는 것으로 정의 (50%라는 수치는 임의적이지만 라벨 다는 사람의 해석의 용의성을 위해 설정됨)
- 노출 단계에 대한 설명문 요약
- E0 (=노출 없음) : LLM을 사용해도 작업 완료까지 시간이 줄어들지 않거나, LLM 사용이 작업 결과의 질을 떨어뜨리는 경우
- E1 (=직접 노출) : LLM 사용 시 작업 완료까지 절반 이상 시간이 단축되는 경우
- E2 (= LLM+ 노출) : LLM만 사용하면 시간이 단축되지 않지만, LLM 과 다른 소프트웨어(ex.이미지 생성 시스템)를 같이 사용하면 작업 완료까지 절반 이상 시간이 단축되는 경우
- 위 설명문이 주어졌을 때, 인간과 GPT-4에게 앞서 언급된 직종, DWA, 작업의 정보를 주고 어떤 노출 단계에 해당하는지 라벨을 달아달라고 요청함
- 대부분의 직종에서 인간과 GPT-4의 생각(이 일이 LLM에 의해 대체될 위험이 높을까? 에 대한 대답)이 매우 비슷하다는 사실을 알 수 있었음
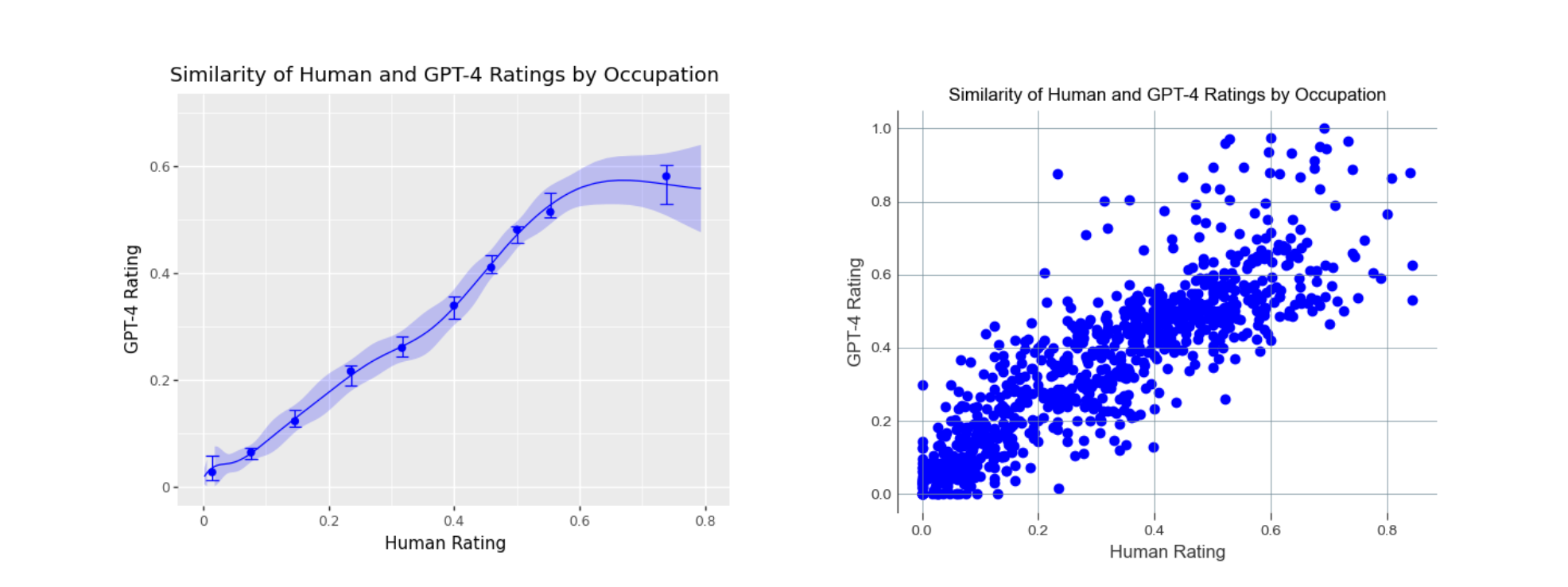 대체로 비슷하지만, 0.8구간에서 꺾이는 선을 보아 GPT의 상한이 살짝 더 낮다
대체로 비슷하지만, 0.8구간에서 꺾이는 선을 보아 GPT의 상한이 살짝 더 낮다
- 대부분의 직종에서 인간과 GPT-4의 생각(이 일이 LLM에 의해 대체될 위험이 높을까? 에 대한 대답)이 매우 비슷하다는 사실을 알 수 있었음
결과
요약
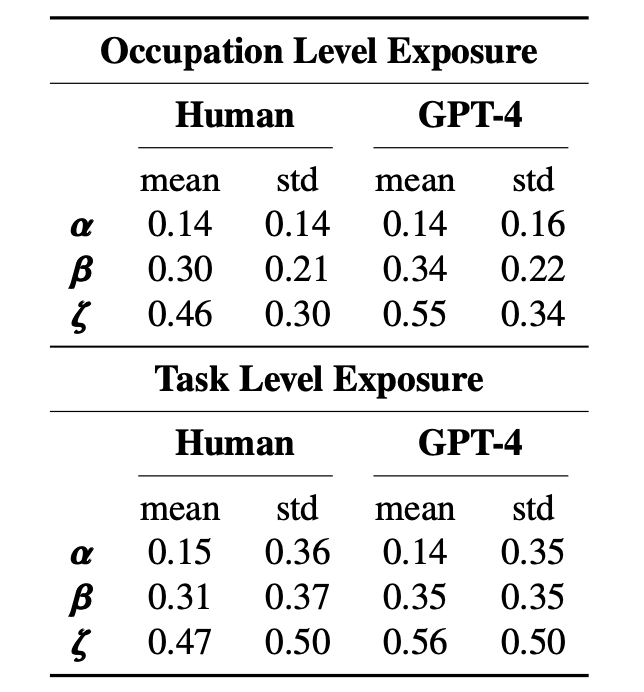
- 이 연구의 3개의 target variabe은 다음과 같음
- $\alpha$ = E1 (LLM 직접노출)
- $\beta$ = E1 + E2*0.5 (LLM 직접노출 + 가중치를 절반만 둔 다른 소프트웨어와 결합 노출)
- $\zeta$ = E1 + E2 (LLM 직접노출 + 가중치를 동일하게 둔 다른 소프트웨어와 결합 노출)
- 즉 전체 직종 중 약 14~15%가 LLM에 직접 노출되어 있고 ($\alpha$), $\beta$ 기준으로는 40%대, $\zeta$ 기준으로는 50% 가까이 올라감
- 물론 작업 기준인지 직종 기준인지 / 직종의 수를 볼 건지 거기 속한 사람의 수를 볼 건지는 구분해서 생각해야 하는데,
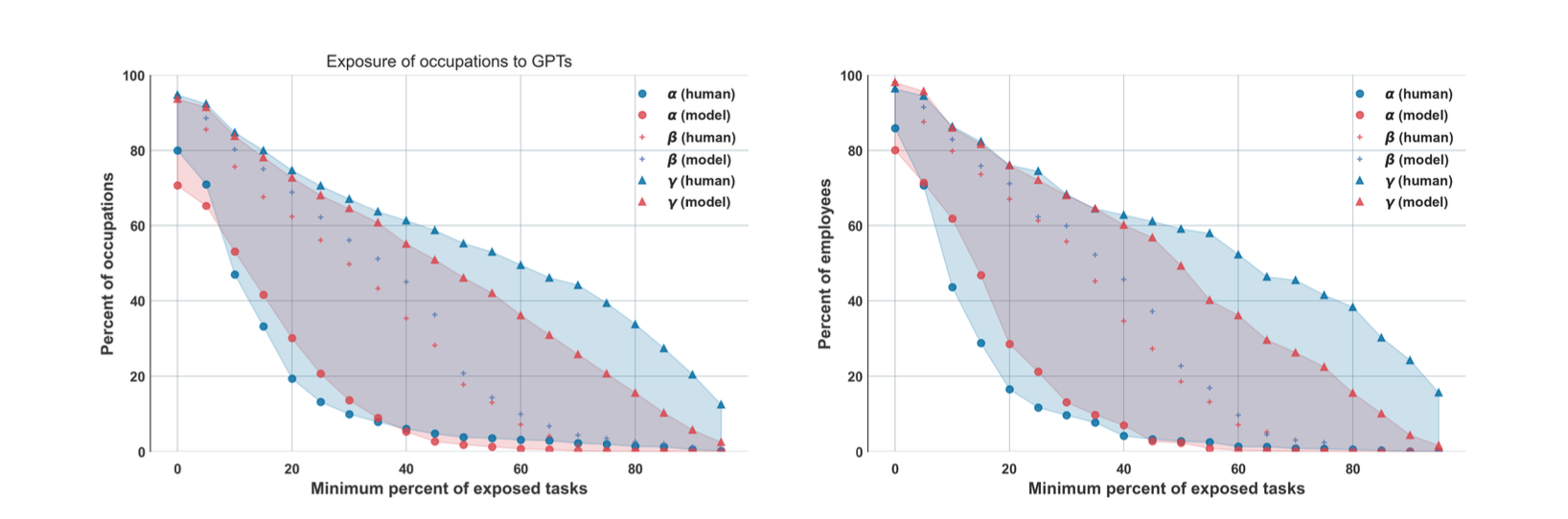
- $\beta$ 기준으로 고용 데이터와 결합하여 볼 때, 80%의 노동자가 최소 10% 작업(task)이 LLM에 노출된 직종에서 일하고 있으며, 19%의 노동자가 절반 이상의 작업이 LLM에 노출된 직종에서 일하고 있음
임금과 고용 수준에 따라
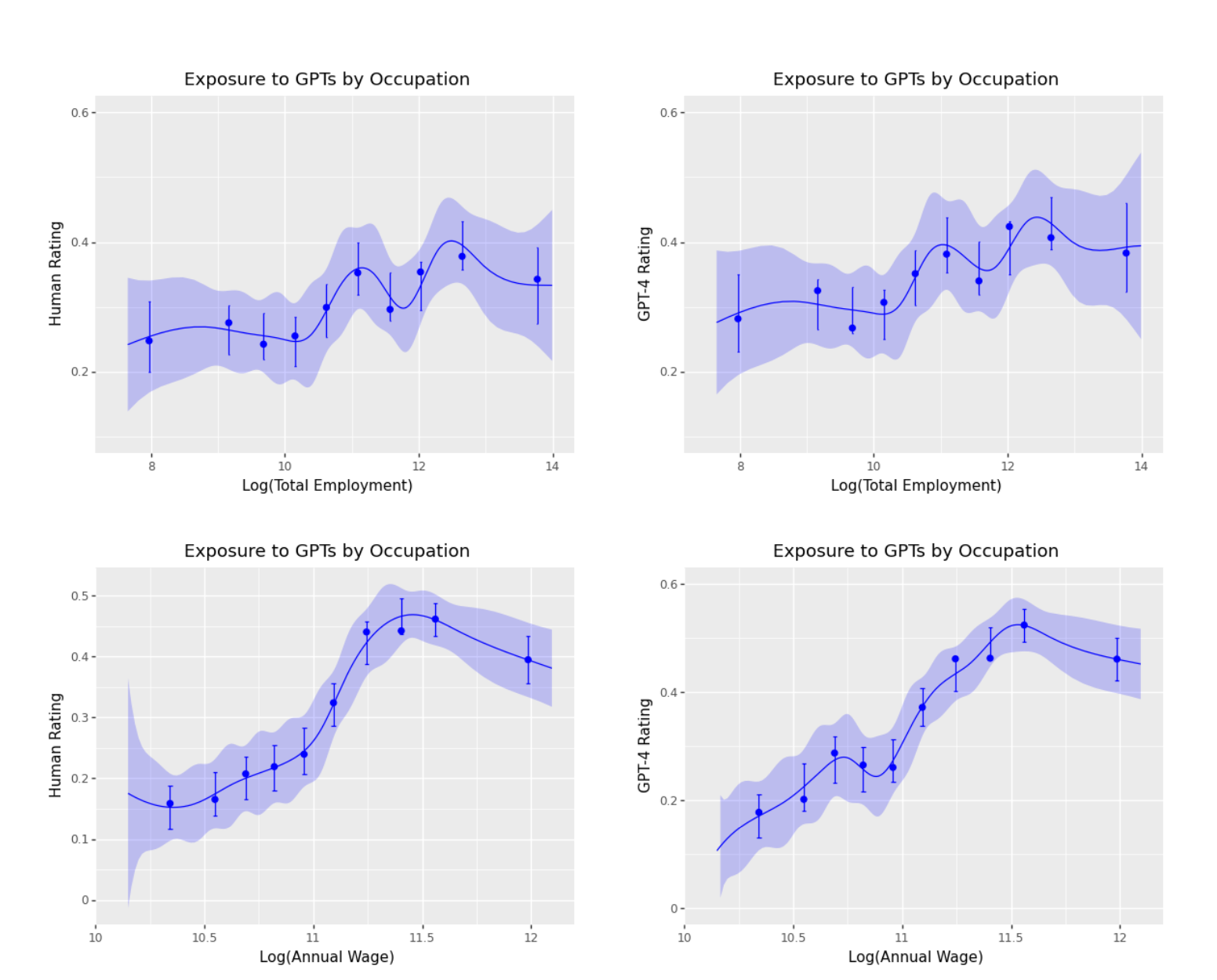
- 고용 수준(일하는 노동자의 수)는 큰 영향을 안 주는 듯함
- (일반적인 생각과 다르게) 고연봉의 직업일수록 노출도가 높음(LLM으로 대체될 가능성이 높음)
- 다만 가장 높은 연봉 구간에서는 선이 약간 꺾여서 낮아지는 경향 있음
필요한 능력에 따라
- O$*$NET이 제공하는 skill importance(그 일을 하는데 이 능력이 얼마나 중요한가?)를 정규화하고, 노출도( $\alpha$, $\beta$, $\zeta$)와의 관계를 파악하기 위해 회귀분석을 함
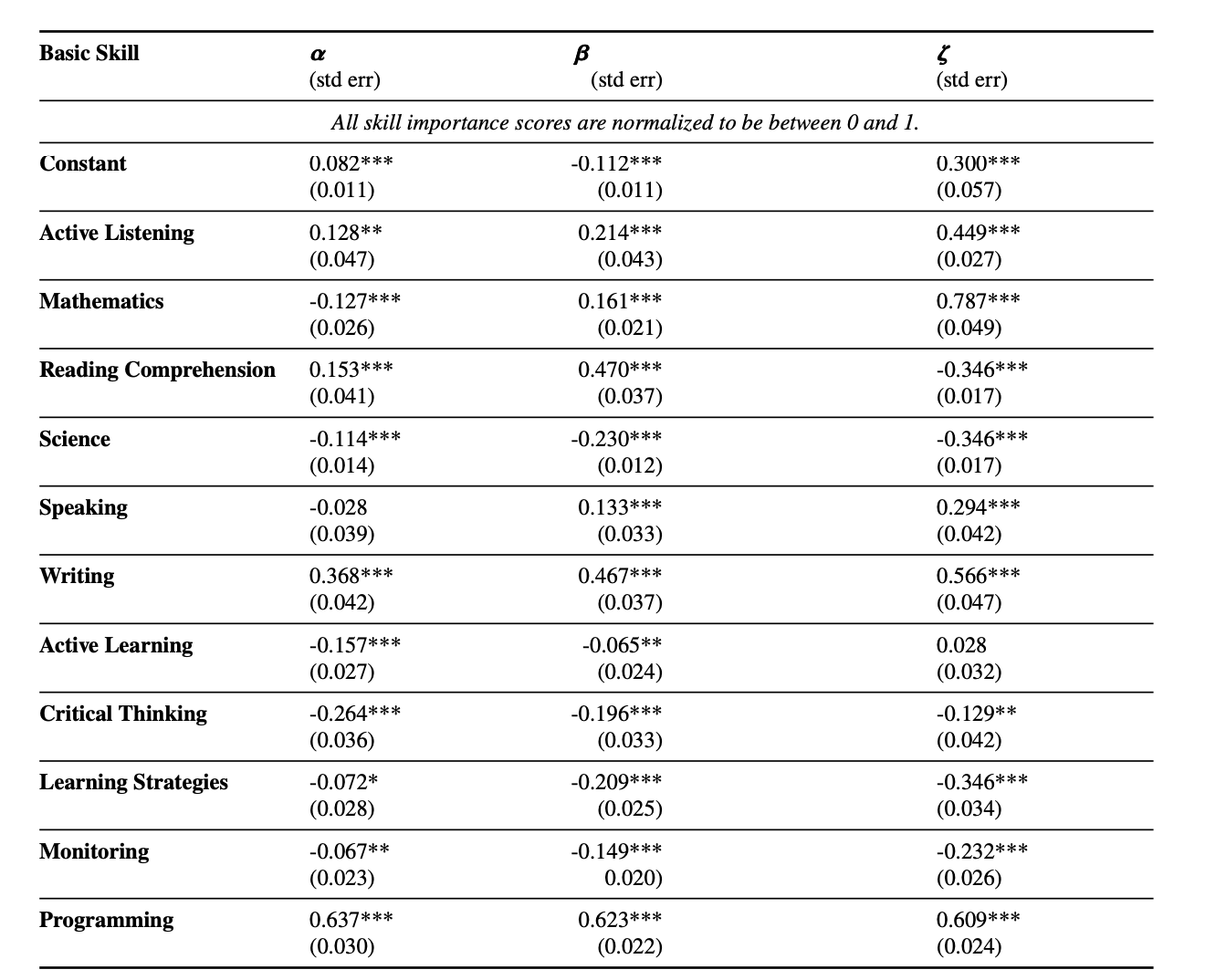
- 표에 기재된 값은 회귀계수로, 쉽게 말하면 음수이고 값이 클 경우 노출도와 반대의 관계, 양수이고 값이 클 경우 노출도와 같이 올라가는 관계라고 볼 수 있음
- $\beta$ 기준으로,
- 가장 LLM이 대체하기 어려운 능력: 과학, 비판적 사고
- 가장 LLM이 대체하기 쉬운 능력: 프로그래밍, 글쓰기
- $\alpha$, $\beta$, $\zeta$를 다 보면 흥미로운 부분들: 수학과 같은 능력은 $\alpha$ 나 $\beta$를 보면 노출도가 많이 높진 않은가? 싶은데 LLM+다른 소프트웨어가 덧붙여진다면 위험해보임(= $\zeta$가 매우 높음)
- $\beta$ 기준으로,
진입장벽에 따라
- 각 일의 진입장벽은 다음 두 가지로 나눠 볼 수 있음
- 처음 진입할 때 얼마나 높은 수준의 교육이 필요한가? 예를 들어 어떤 직종은 박사 학위를 요구하는 반면 다른 직종은 그렇지 않음
- 처음 진입할 때 얼마나 긴 기간의 훈련 기간이 필요한가? 예를 들어 어떤 직종은 일반적인 능력 수준에 도달하기 위해 신입에게 3년 이상의 수습/훈련 기간을 필요로 하지만 다른 직종은 바로 시작해도 기존 직원과 비슷하게 일할 수 있는 편임
- O$*$NET의 Job Zone은 이런 정보를 반영하는데, 1에서 5까지의 Job Zone이 있고, 숫자가 높을수록 진입장벽이 높은 직종을 의미함
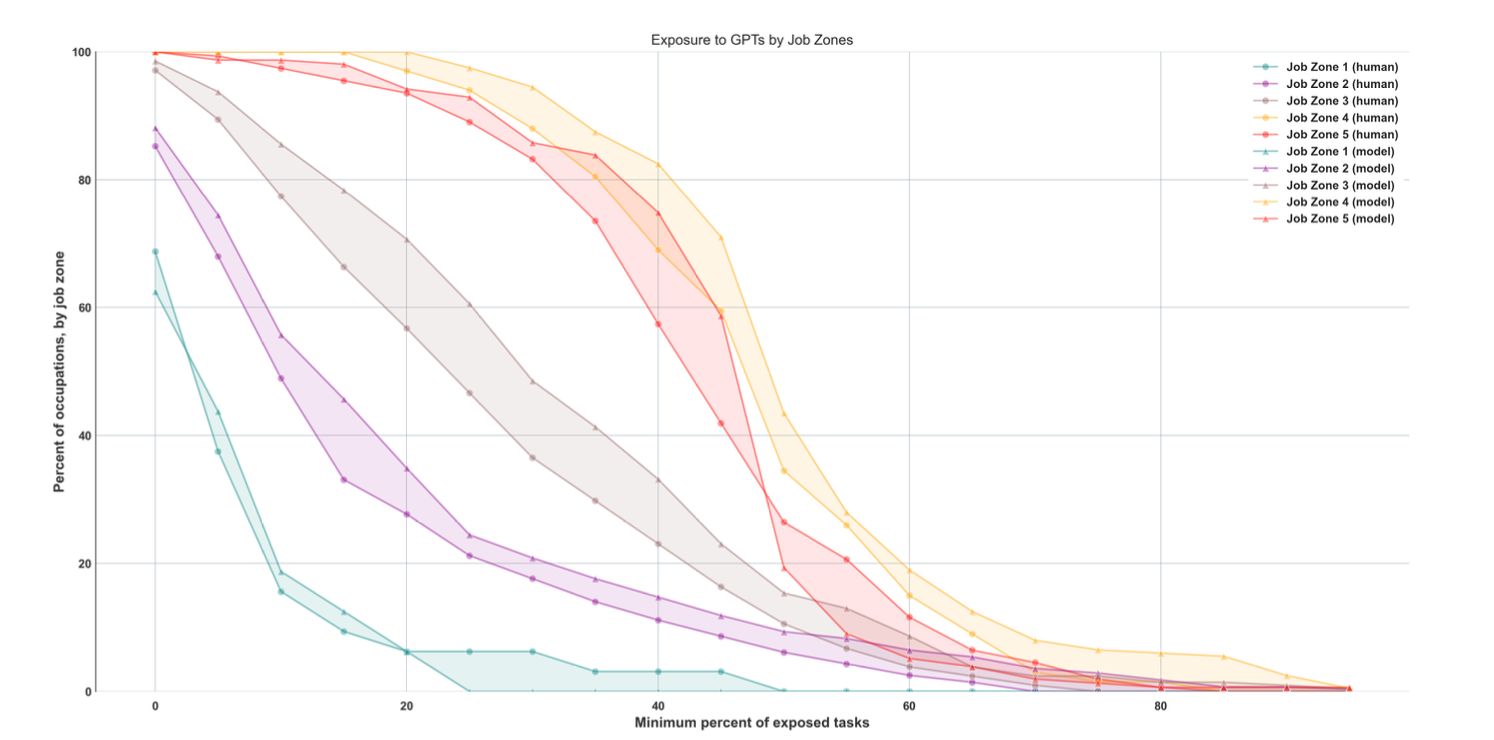
- 이 그림은 각 Job Zone 별로 $\beta$ 기준 노출도를 그린 것
- x축이 노출도
- y축이 해당 노출도 퍼센트에 해당되는 직종의 비중
- 역시 흔히 예측할 수 있는 것과 다르게 가장 진입장벽이 높은 Zone 4와 Zone 5(노란색, 빨간색)가 가장 노출도가 높음!
- 다만 위 연봉 그래프에서 가장 높은 존에서 선이 약간 꺾이는 것과 마찬가지로, Zone 5가 Zone 4보다 낮음 (직관적으로 이해는 안 되고 설명도 없어서 실제 zone 별 직종 리스트가 궁금하긴 함. 고연봉/고숙련 직업일수록 대체되기 쉬운 경향이 있지만, 아주 최상위 고연봉/고숙련은 대체 가능성이 약간 떨어진다는 뜻인데, 어쨌든 그럼에도 저연봉/저숙련보다 높은 것은 사실)
노출도가 높은 TOP 5 직종
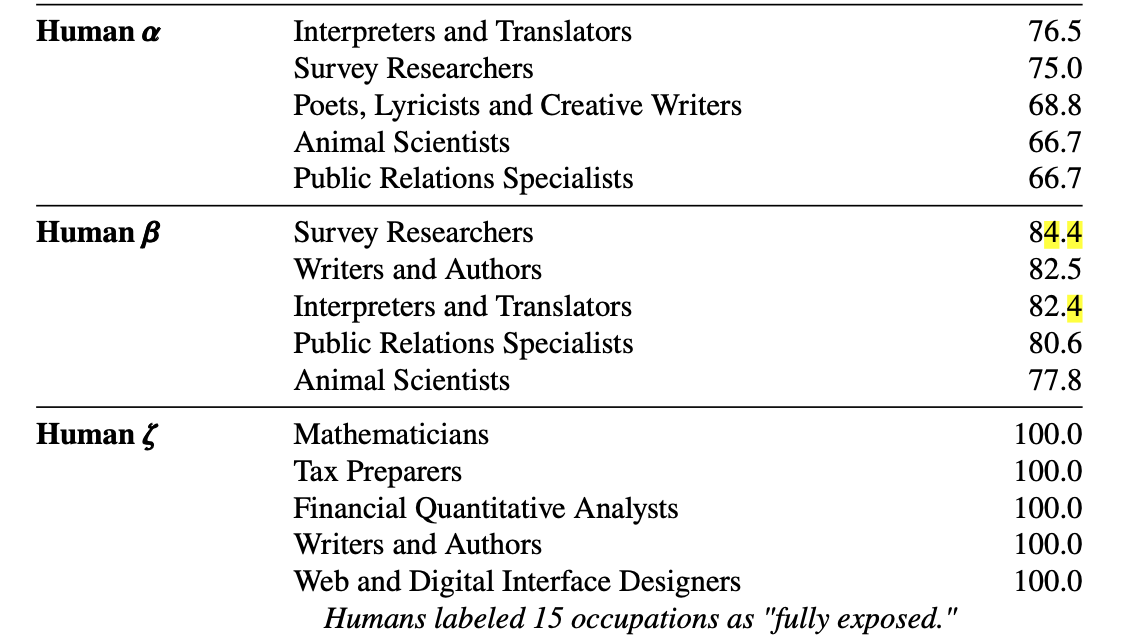 인간이 생각한 가장 노출된 직종 5개
인간이 생각한 가장 노출된 직종 5개
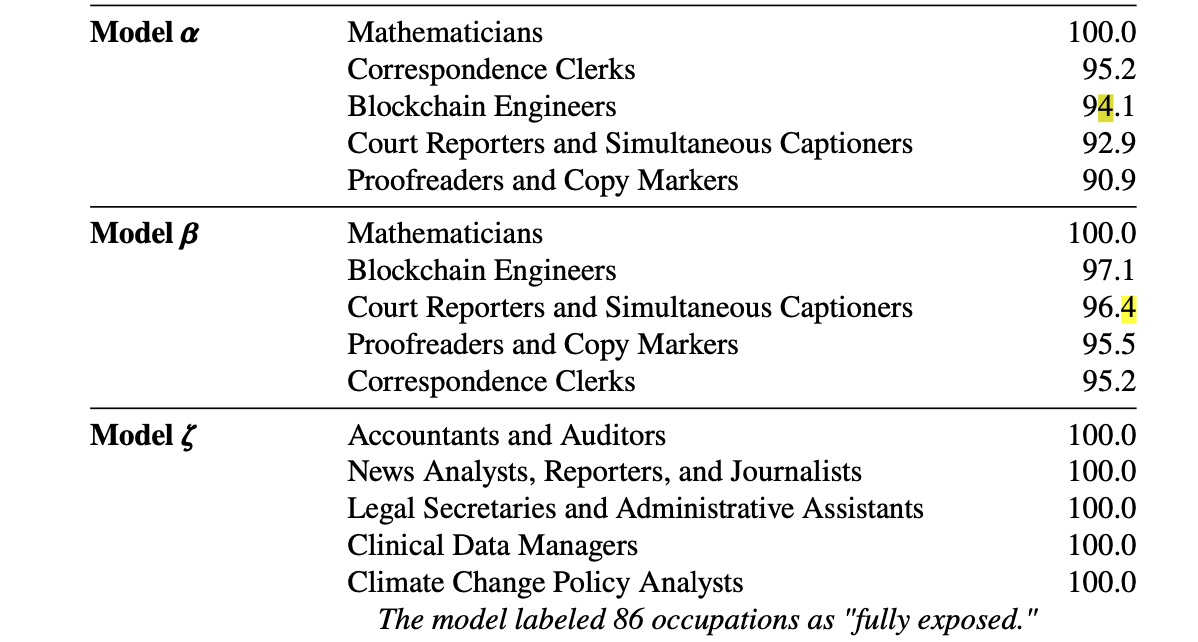 GPT-4가 생각한 가장 노출된 직종 5개
GPT-4가 생각한 가장 노출된 직종 5개
🤔 여기서 잠깐, 이제 결과를 대략적으로 훑어 봤으니 이 글의 제목에 답을 해봅시다. 제 직업은 데이터 분석가입니다. “흔히 알려져 있기로” 연봉이 적진 않고(모두 그렇지는 않음) 종종 석사 이상의 학위를 요구하며(역시 모두 그렇지는 않음) 필요한 스킬셋은 수학, 프로그래밍, 글쓰기, 비판적 사고(저 표에 나열된 것중에서는)입니다. 그러니까 지금까지의 내용을 참고해보면, 다행히 TOP5는 피했지만 노출도가 상당히 높아 보이네요? “흔히 알려져 있기로”가 맹점이지만, 사람이 하든 GPT가 하든 라벨링을 할 때 모든 직종에 대해 ‘흔히 알려져 있는 정보’에서 벗어나기 어렵기 때문에, 그건 이 연구 자체의 맹점이기도 하겠습니다.
결론
여기까지 살펴봤으니 이제 제목에서 던진 도발적인 선언(GPT는 범목적기술이 맞다)으로 요약되는 결론을 서술할 차례입니다.
선행 연구에 따르면, 범목적기술은 다음과 같이 3가지의 조건을 만족해야 합니다.
- 시간이 지날수록 발전해야 한다.
- 경제 전반(전 영역)에 침투해야 한다.
- 상호보완적인 다른 혁신(발명)을 이끌어내야 한다.
지금까지 수많은 과거 문헌들은 LLM의 1번 특성(시간이 지날수록 발전한다)을 증명해왔고, 사실 요 부분은 뭐 더 설명할 필요도 없이 대부분 인정할 만한 사실인 것 같습니다. 이 논문은 이 연구가 2번, 3번 특성을 보여준다고 말하고 있는데요. 전체 노동자 중 80%가(2. 전 영역에 침투) LLM에 노출된 작업을 포함하는 직종에서 일하고 있고, 특히 $\zeta$ 값으로 보여지는 다른 소프트웨어나 디지털 도구를 통해 (3. 상호보완적인 발명) 노출되고 있다는 면에서 그렇습니다.
특히 3번 관해서는 이 그림을 다시 보면요, y축(직종의 비중)에 대해 $\zeta$ (LLM+다른 소프트웨어)와 $\alpha$(only LLM)의 차이를 구하면 그게 바로 LLM과 상호보완적 역할을 할 다른 소프트웨어에 의한 노출도라고도 볼 수 있는데요. 이 값은 인간 생각에는 0.32이고, GPT 생각에는 0.42라고 합니다. $\alpha$ 값인 LLM 혼자만의 노출도(0.14 전후) 보다도 훨씬 높은 값입니다. 그러니까, LLM-powered 소프트웨어의 영향도가 LLM 자체의 영향도보다 두 배 이상으로 큰 것이죠. 따라서 앞으로 LLM을 이용한 도구들이 얼마나 추가적으로 발명되느냐에 따라 지금보다 더 크고 사실상 짐작하기 어려울 영향력을 가져올 수도 있다는 뜻이겠습니다. 모델에 상대적으로 간단한 UI 개선만 붙인 것이 ChatGPT가 일으킨 붐이 되지 않았느냐는 말도 함께 언급을 하고 있습니다.
이렇듯 경제 전반에 파급적인 영향력이 있을 것이고, 인간의 노동을 분명 더 효율적으로 만드는 부분이 있겠지만, 실제 노동 생산성에 미치는 결과에는 다른 사회적, 경제적, 법적, 기타등등의 요소들이 있을 거라는 당연한 말과 함께, 따라서 기업가들과 정책을 만드는 사람들이 이 발전의 궤적을 충분히 이해하고 따라가면서 결정을 내릴 수 있어야 한다는 결론으로 논문이 마무리가 됩니다. 마지막에 GPT 보고 이 연구 결론을 요약해봐 라고 해서 적은 부분이 있는 게 인상적이네요.
