내 스파크 잡을 구해줘 (아마도 성능 향상 팁들)
주로 데이터 편향에서 비롯되는 스파크 성능 저하 또는 처참한 실패에 부딪혔을 때, 시도해 볼 수 있는 코드 작성 수준의 스파크 성능 최적화 방법들을 알아보았습니다.
이 글을 쓰게 된 이유
저는 회사에서 일정 시간마다 돌아가는 스파크 배치 잡을 pyspark로 작성하는 일이 많습니다. 며칠 전에 등록한 배치 잡이 실패한 일이 있었는데요. 처음에 실패한 거 보고 엇 뭘 잘못했지? 근데 테스트 할 땐 좀 오래 걸리긴 했어도 문제 없이 돌아갔는데? 라는 생각을 했죠.
실행 로그를 확인해 보니,
java.lang.OutOfMemoryError로 시작함 = 메모리 없어서 니가 시킨 거 중간에 킬됐어! 라는 소리
코드 에러는 아니었지만, 일정에 쫓긴다는 이유로 코드를 호다닥 거지같이 작성한 탓이었습니다. 너무 많은 데이터를 셔플링 하게 되었고 공간 부족으로 실패했던 것입니다. 어쩌다 다행히 실패하지 않더라도, 느려서 배치가 연달아 지연되는 것도 큰 문제입니다.
저는 피할 수만 있다면 이 OOM 친구를 다시 만나고 싶지 않았습니다. 그래서 스파크에서 구린 성능의 코드를 작성하는 것을 어떻게 피할 수 있는가? 를 한 번 찾아보았습니다.
우선 모니터링을 하자 👀
언제 어디서나 제일 중요한 것은 상황 파악입니다. 내가 시킨 일이 망했나? 망했다면 어느 포인트에서, 뭘 하다가 망했나? 를 알아봐야 합니다.
스파크는 웹 UI를 제공해서 실행 중인 애플리케이션과 워크로드에 대한 지표를 화면에 띄워줍니다. 드라이버와 익스큐터가 어떤 상태인지를 체크하고, 각 잡, 스테이지, 태스크에서 어떤 일이 일어났는지를 체크해야 개선이든 디버깅이든 할 수가 있겠죠.
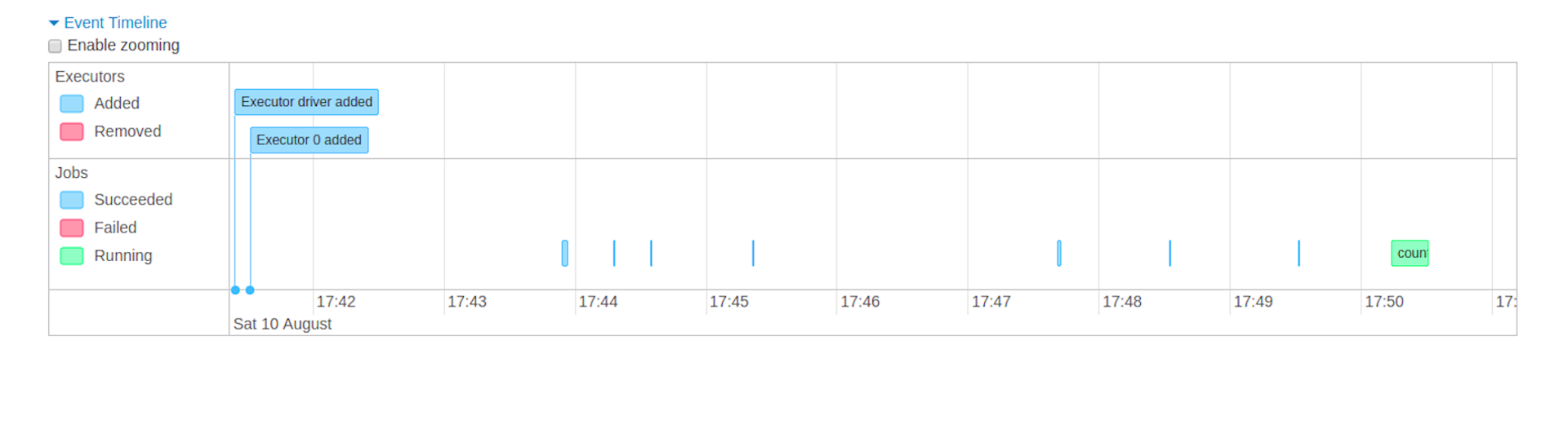
위와 같은 타임라인부터, 각 스테이지가 실행될 때 스파크가 수행하는 DAG를 시각화해 볼 수도 있고요.
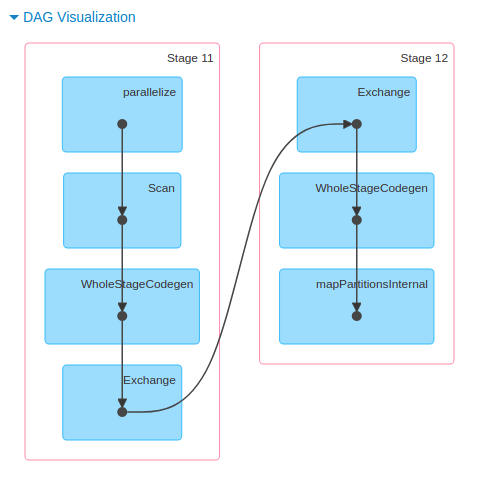
각 태스크 별 요약 통계를 제공하는 탭도 있습니다. 어떤 잡 어떤 스테이지가 제일 오래 걸렸는지, 익스큐터들이 골고루 일을 하고 있는지(일부가 놀고 있어서 느려지는 건 아닌지), 셔플링을 너무 많이 하고 있진 않은지 등을 확인할 수 있어요.
스파크 UI에 대한 더 자세한 내용이 궁금하다면 공식 문서에서 확인하면 됩니다.
자 이제 그럼 정확히 어떤 문제가 있을 수 있고, 나는 어떻게 해야 하는가의 단계로 넘어가보겠습니다.
🛣️ 성능 최적화에는 크게 두 갈래의 길이 있습니다. 하나는 스파크 컨피그 설정을 잘 만지는 것이고 다른 하나는 코드를 잘 작성하는 것입니다. 전자도 알아둘수록 물론 매우 좋겠지만! 제가 업무에서 담당하는 영역은 아니기 때문에 오늘은 후자를 위주로 살펴보겠습니다.
가장 흔한 문제, 데이터 편향 (Data Skewness)
스파크는 모든 익스큐터가 병렬로 작업을 수행할 수 있도록 파티션이라고 불리는 청크 단위로 데이터를 분할합니다. 파티션은 클러스터 머신에 존재하는 로우의 집합으로, 쉽게 말하면 데이터를 물리적으로 나눈 방식을 뜻합니다(파티션이 하나라면 아무리 많은 익스큐터가 있어도 병렬 수행이 아닙니다).
따라서 이상적인 상황이라면, 데이터를 잘 파티셔닝해서 고르게 분배되도록 해야 최적의 성능을 볼 수 있을 것입니다. 하지만 특정 트랜스포메이션에 의해 일부 파티션에 데이터가 쏠리게 되는 경우가 있는데, 이를 데이터 편향(skew) 이 발생했다고 부릅니다.
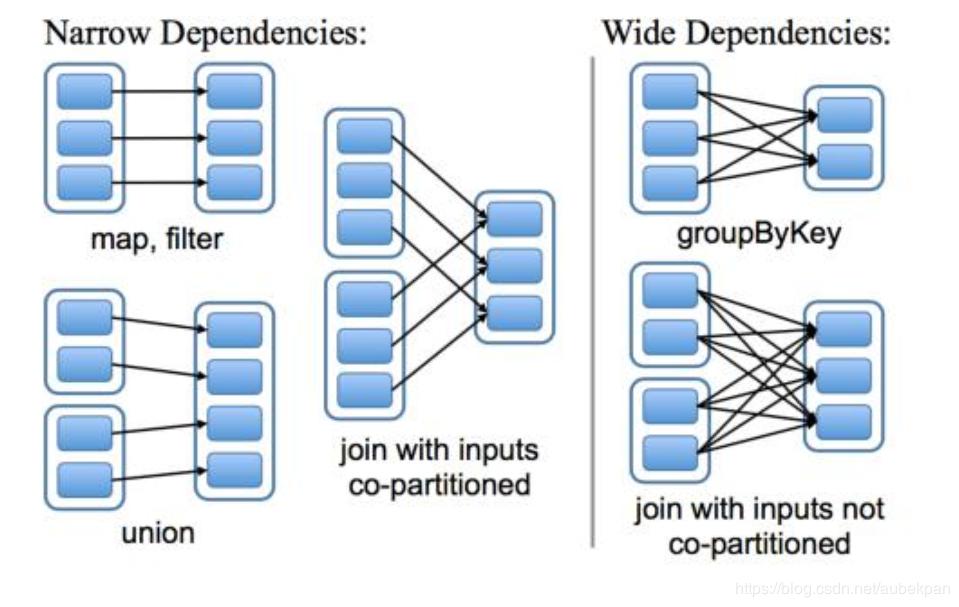
복잡한 앱을 작성하다보면 사실 어느 단계에서 편향이 발생하는지도 확인하기 어려울 텐데요. 어찌 되었든 한쪽으로 쏠린 데이터는 특히 셔플(shuffle) 시에 문제가 됩니다. 셔플은 각 파티션 내에서만 트랜스포메이션이 영향을 끼치는 게 아니라(narrow transformation), 서로 다른 파티션 간에 영향을 미칠 때(wide transformation) 발생합니다. 예를 들어 조인의 경우 조인하고 자하는 특정 키 값에 대해 동일한 키가 동일한 파티션 내에 있도록 해야 하기 때문에 후자에 속합니다.
한 파티션의 데이터를 다른 파티션에 이동하거나 재구성하면서 모든 익스큐터 간 통신이 발생해야 하므로 셔플은 비용이 많이 드는 작업입니다. 편향된 데이터에 수행하게 되면 아주 느려지게 됩니다. 200개 태스크 중 199개의 태스크는 금방 끝났는데 하나만 왜 이렇게 세월아네월아 하고 있지? 하는 경우도 많고요(너 하나만 일하면 내가 퇴근할 수 있는데!). 심하면 제가 경험했던 것처럼 Out of memory로 잡이 실패할 수 있습니다.
이때 시도해볼 수 있는 방법들은 다음과 같습니다.
(재)파티셔닝
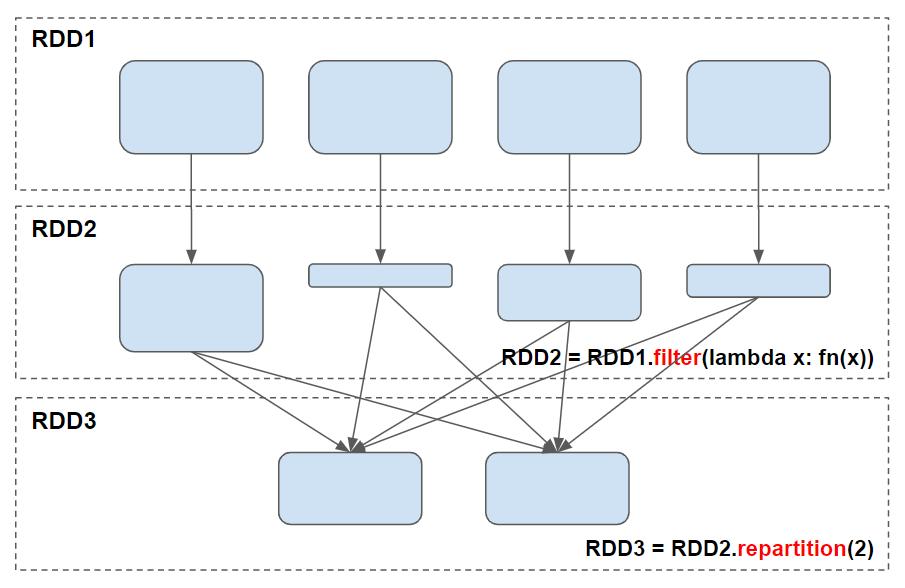 이미지 출처
이미지 출처
위의 예시는 필터 트랜스포메이션을 통해 데이터 편향이 발생한 경우, 파티셔닝 방법을 사용하여 다시 파티션을 설정해준 것을 도식화한 내용입니다.
repartition(): 파티션 개수를 늘이거나 줄일 수 있음, 셔플 발생coalesce(): 파티션 개수를 줄일 수만 있음
단, repartition 메서드는 무조건 전체 데이터를 셔플하게 됩니다. 파티션 개수를 늘리거나, 컬럼을 기준으로 파티션을 만드는 경우에만 사용하는 것이 좋습니다. (df.repartition(F.col("column_name")))
반면 coalesce 의 경우 파티션을 늘릴 순 없으나, 셔플을 하지 않는 버전의 repartition 이기 때문에 파티션 개수를 줄여서 병합하고 싶으면 coalesce 를 씁시다. 두 메소드 모두 목적하는 파티션의 개수와 기준 칼럼을 인자로 받을 수 있습니다.
브로드캐스트 조인
스파크에서 기본 조인은 셔플 조인입니다. 파티셔닝 없이 전체 익스큐터 노드 간의 통신이 발생하기 때문에, 테이블의 크기가 크고 데이터가 편향되어 있을수록 더 매우 많은 자원이 필요합니다.
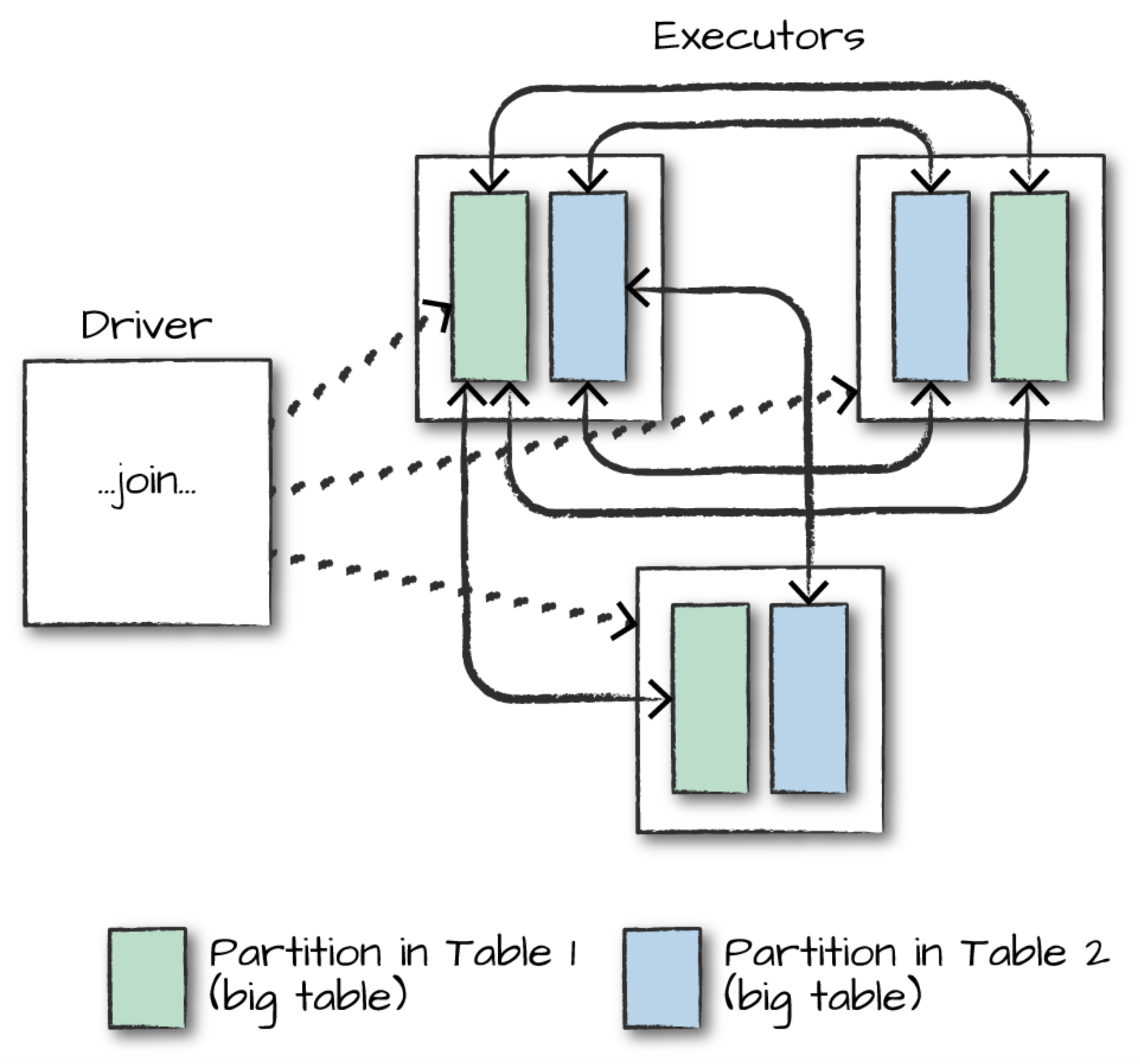 셔플 조인
셔플 조인
하지만 만약 작은 데이터프레임과 큰 데이터프레임을 조인하고 싶다면, 아래와 같은 브로드캐스트 조인을 선택할 수 있습니다.
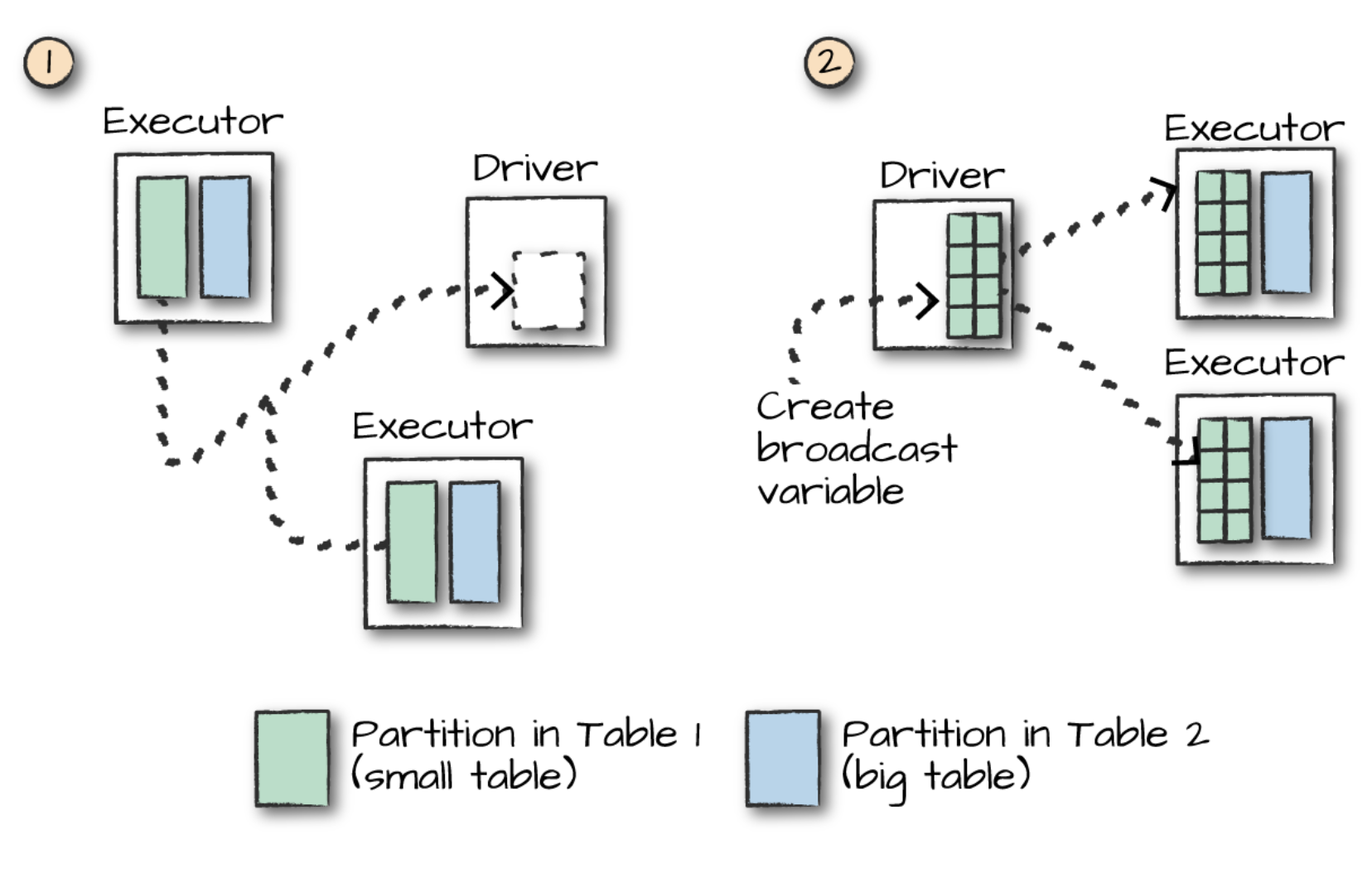 브로드캐스트 조인
브로드캐스트 조인
브로드캐스트 조인이란, 둘 중 더 작은 테이블을 한꺼번에 드라이버에 복사해놓고 쓰는 것입니다. 그래서 이 첫 단계(복제)만 지나가면 그 다음부터는 워커 간 통신이 필요하지 않고, 각 단일 익스큐터가 개별적으로 조인을 하면 되기 때문에 훨씬 효율적입니다.
주의해야 할 점은 다음과 같습니다.
- 하드코딩된 제한이 있다(8GB 이상이거나 로우의 개수가 512000000 이상이면 안 됨).
- 작지 않은 데이터프레임을 브로드캐스트로 메모리에 올려버리면 오히려 메모리가 부족해서 망할 수 있다.
- 스파크SQL은 옵티마이저가 알아서 브로드캐스트 조인을 해줄 수도 있다. 세팅을 통해 조절하거나 힌팅이 가능하긴 하다.
Salting
뭔가 편법 같으면서도 오 이런 팁이? 싶기도 한, 개인적으로 굉장히 재미있게 느꼈던 방법입니다. Salting은 간단히 말하면 랜덤한 값을 가지는 칼럼을 추가한 뒤 이걸 이용해서 파티션이 잘 나눠지도록 하는 건데요. 무슨 말인지 잘 이해가 안 갈 것 같으니 예시를 들어 보겠습니다.
큰 테이블 A와 비교적 작은 테이블 B를 조인해야 하는데, A에서 우리가 조인해야 하는 키 값의 분포가 상당히 편향되어 있다고 칩시다. 예를 들면 키 값 별로 페퍼로니는 30개, 포테이토는 50개, 치킨 바베큐는 100개, 하와이안은 1만개의 레코드가 있다면요? 이 키 값만 가지고 조인을 하게 되면 파티션 간 데이터가 매우 불균형한 결과물을 얻게 될 겁니다.
이때 A를 가지고 0부터 N까지 랜덤 정수 값을 갖는 칼럼을 옆에 살짝 뿌려줍니다. 🧂 그다음에 이 두개를 합친 것을 새로운 조인 키 (Salted Key) 로 쓰겠습니다.
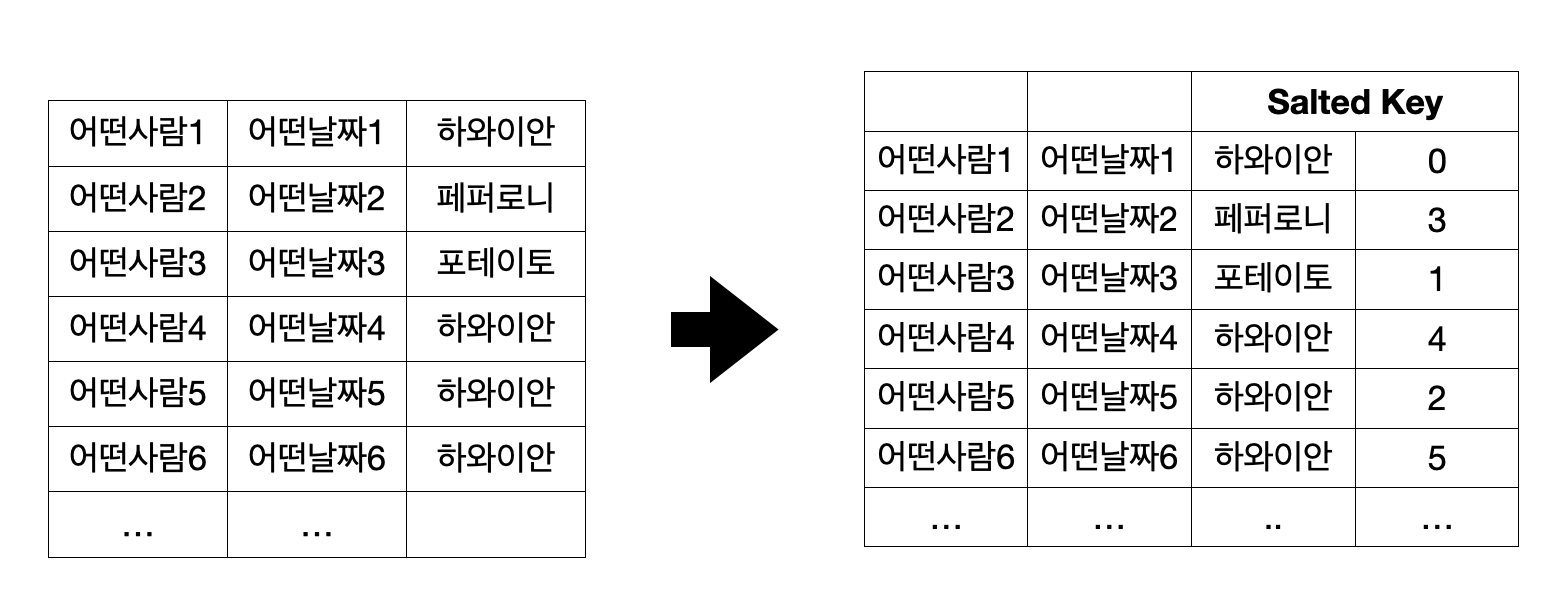
원래 키와의 차이점은 Salted key가 비교적 더 고르게 분포되었다는 점입니다. 딱봐도 이전에는 하와이안 4개가 반복해서 나올 때 새로운 데이터에서는 하와이안0, 하와이안3, 하와이안2, 하와이안5 이렇게 여러 개가 나오니까요.
그러면 작은 테이블 B에는 무슨 짓을 해야 할까요? B는 dimension table처럼 매우 크기가 작은, 예컨대 가격표라고 해봅시다. 여기다도 저 숫자 키를 넣어줘야 하는데요, 이때는 숫자 키의 크기, N=9였다면 10만큼 B를 뻥튀기를 해줍니다. 이제 B에도 저 Salted key 변수가 만들어졌죠.
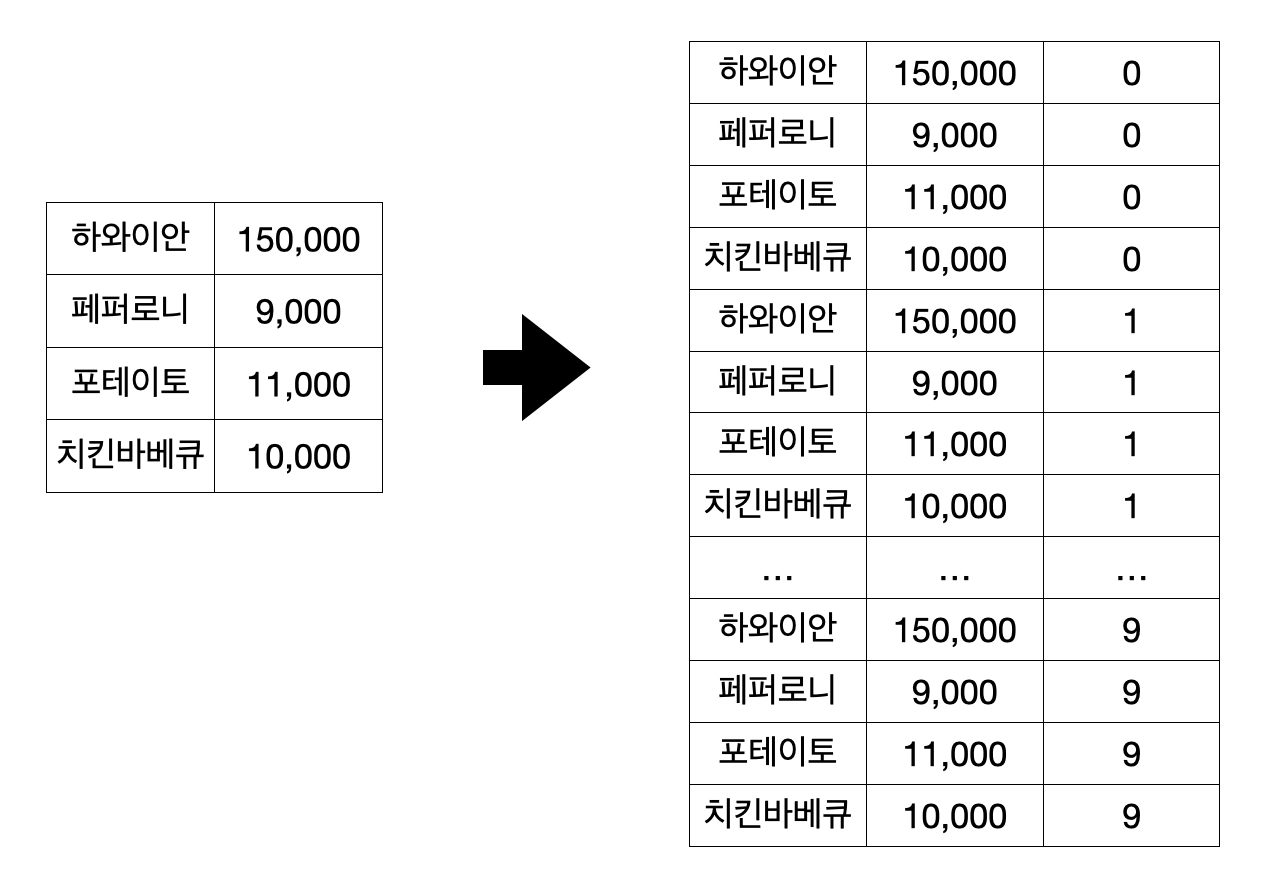
그다음에 이 새로운 키로 조인을 하게 되면, 이 랜덤한 정수가 일종의 파티션ID 역할을 해서 각 파티션에 고르게 데이터를 나눠줄 수 있습니다! 그다음에 정수 칼럼은 버려도 됩니다.
(적절한) 캐싱
스파크는 lazy evaluation 원칙에 따라 액션이 진행되기 전에는 실제 트랜스포메이션을 아무것도 실행하지 않고 기다리며, 같은 프로그램 내에서도 액션을 할 때마다 모든 연산을 다시 시작해야 합니다. 따라서 데이터를 메모리/디스크에 캐싱하면 반복되는 연산을 줄일 수 있는 이점이 있습니다. 데이터프레임은 cache(), RDD는 persist() 를 이용합니다.
물론 캐싱은 만능치트키는 아닙니다. 예를 들어 한번 데이터를 캐싱해버리면 그 다음부터 옵티마이저가 선택할 수 있는 최적의 갈래가 줄어들기도 합니다. 그러니 캐싱은 셀프 조인이라든지, ML 모델을 훈련시킨다든지 하는 것처럼 해당 데이터를 반복적으로 사용해야 할 경우에만 적절히 사용하는 것이 좋습니다.