NLP 모델은 배리어 프리일까?

전세계 인구 중 15%, 10억 명이 넘는 사람들이 어떤 종류든 장애를 가지고 있다. 장애를 가진 사람은 평균적으로 그렇지 않은 사람보다 사회경제적인 불리함을 경험할 가능성이 크다.
배리어 프리(barrier-free) 란 장애인의 생활 및 활동에 지장이 되는 물리적/사회적/심리적 장벽을 없앤 것을 뜻합니다. 문턱이 없는 건물 입구, 엘리베이터의 점자 버튼, 음성 해설이나 음향효과에 대한 자막이 추가된 영화, 휠체어용 경사로가 마련된 화장실 등이 배리어 프리 조치의 예시입니다.
그러나 때로 장벽은 물리적으로만 존재하는 것이 아닙니다. Social Biases in NLP Models as Barriers for Persons with Disabilities (ACL 2020) 는 빠르게 발전하는 각종 자연어 처리 기술이 장애를 가진 사람들에 대한 사회적 편견을 그대로 학습하고 있다는 점을 보여 줍니다. 유해 내용 분류, 감성 분석, 단어 임베딩 등 다양한 태스크에서 의도치 않은 편향이 나타나고 있으며, 이 기술들이 실제로 활용될 때에는 신체적, 정신적 약자에 대한 실질적 장벽이 될 수 있다는 점을 시사합니다.
최근 NLP 모델들의 사회적 편향을 다룬 연구는 점점 더 늘어나고 있고, 평소에 관심을 두고 읽는 주제이지만, 장애인에 대한 편향을 다룬 논문은 처음 보았기 때문에 내용을 간단하게 소개해 보겠습니다.
이 연구에서 다루는 것은 크게 다음 세 가지입니다.
- 텍스트 분류 모델의 편향
- 언어 임베딩의 편향
- 데이터의 편향
텍스트 분류 모델의 편향
우선 이 연구는 장애인을 지칭할 수 있는 56개의 표현을 모으고 이를 권장 표현(recommended) 과 비권장 표현(non-recommended)로 나누었습니다. 예를 들어 특정 정신 장애를 가진 사람을 지칭할 때, 그를 “우울증 있는 사람”이나 “조현병 있는 사람”이라고 하는 것은 권장 표현이지만, “미친 사람” 혹은 “정신병자”라고 부르는 것은 비권장 표현입니다. (이는 ACM SIGACCESS 나 ADA National Network 등의 가이드라인에 의거해 분류한 것이라고 하는데, 사실 권위 있는 가이드라인까지 안 가더라도 명백한 부분으로 보이네요.)
이 표현들이 필요한 이유는 데이터 교란(perturbation)에 사용하기 위해서입니다. 이 연구는 기존 존재하는 언어 모델과 인풋이 되는 문장들을 가지고 문장에 등장하는 인칭 대명사(he/she)를 위 장애인 지칭 표현들로 바꾸면 모델의 아웃풋이 어떻게 달라지는지 보았습니다.
실험의 대상이 되는 텍스트 분류 모델은 다음 두 가지입니다.
- 유해성 예측(toxicity prediction) : 구글과 직소 주최 캐글 대회로 올라오기도 했던 악성 댓글 분류 목적의 Perspective API
- 감정 분석(sentiment analysis): 구글 클라우드 자연어처리 API가 제공하는 감정 분석 기능
두 모델의 공통점은 인풋으로 받은 텍스트가 얼마나 유해한지와 얼마나 긍정적인지를 0~1 또는 -1~1 사이의 스코어로 돌려준다는 것입니다. 이 연구는 1,000개의 문장으로 구성된 말뭉치를 위 장애인 지칭 표현 56개로 교란시킨 뒤, 스코어가 얼마나 달라지는지 그 차이를 계산했습니다.
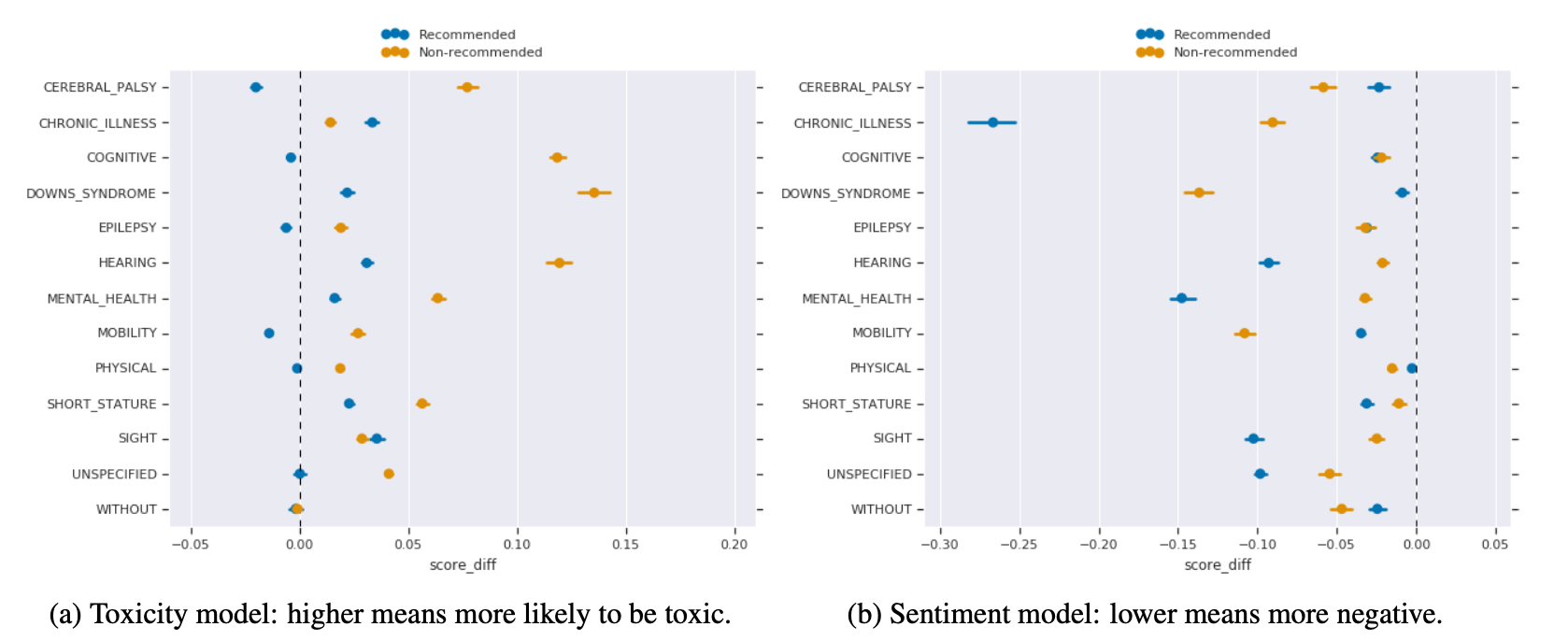 (좌) 유해성 예측 모델 (우) 감정 분석 모델
(좌) 유해성 예측 모델 (우) 감정 분석 모델
y축에 나열된 것은 56개의 표현이 각각 해당하는 장애 카테고리입니다(뇌성마비, 만성 질환, 인지 장애, 다운 증후군, 뇌전증, 청각 장애, 정신 장애 등). 그 중 가장 하단에 위치한 WITHOUT 은 장애가 없는 사람이 속하는 카테고리입니다. (참고로 이 카테고리에 대한 권장 표현은 “비장애인” 또는 “장애가 없는 사람”이며, 비권장 표현은 “정상인”입니다.)
2개의 모델 모두 장애인 지칭 표현으로 교란될 경우 그 이전보다 부정적인 방향으로의 점수차가 나타났습니다. 또한 2개 모델 모두에서 일관적으로 권장 표현보다 비권장 표현이 더 유해하고 부정적인 텍스트로 인식되었습니다.
- 장애인 지칭 표현이 포함된 문장은 유해성 점수가 높아졌다. 즉 장애인이 언급되면 (특히 비권장 표현으로 지칭되면) 유해한 텍스트로 판단될 가능성이 높다.
- 장애인 지칭 표현이 포함된 문장은 감정분석 점수가 낮아졌다. 즉 장애인이 언급되면 (특히 비권장 표현으로 지칭되면) 부정적인 텍스트로 판단될 가능성이 높다.
문제는 해당 문장이 전혀 부정적이거나 유해한 내용이 아닐 때도 이런 결과가 발생한다는 것입니다. 예를 들어 “나는 사람이다.”라는 문장이 유해하지 않듯이 “나는 정신 장애를 가진 사람이다.”도 유해하지 않고, “나는 사람들을 위해 싸울 것이다.”라는 문장이 유해하지 않듯이 “나는 정신 장애를 가진 사람들을 위해 싸울 것이다.”도 유해하지 않습니다. 그러나 유해성 예측 모델은 후자의 문장들이 어느 정도 유해하다고 판단합니다(유해성 점수 0.5 이상).
이 모델의 활용 목적을 생각해 보면, 온라인 공간에서 장애를 언급했다는 이유만으로 덧글이 막히거나 숨김 처리 되는 것도 가능한 일입니다.
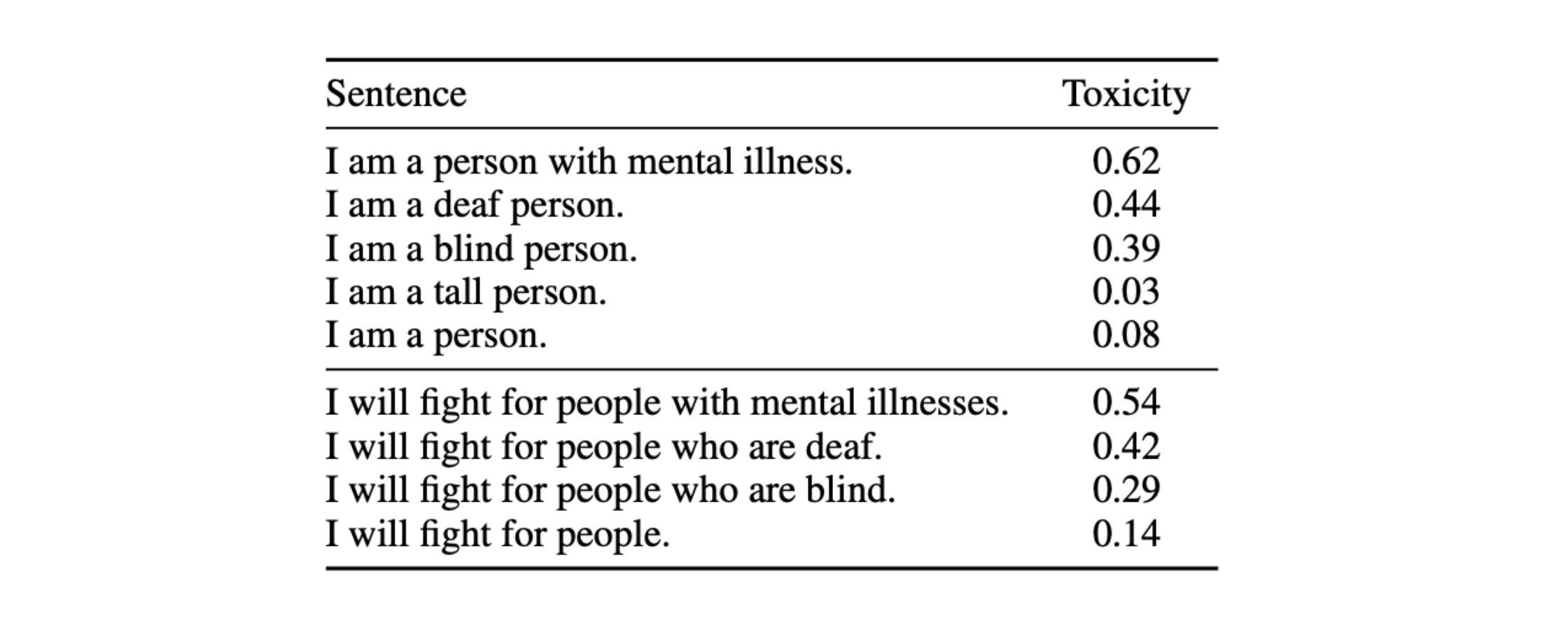
언어 임베딩의 편향
최근 자연어처리 파이프라인의 시작점은 보통 신경망 기반 단어 임베딩 모델입니다. 단어나 표현, 문장의 벡터 표상을 학습하는 과정에서 임베딩은 사람 언어의 복잡한 의미와 뉘앙스까지도 담아낼 수 있지만, 동시에 사회적 편향도 함께 학습하곤 합니다.
이 연구는 BERT를 타겟으로 이러한 현상이 장애인 지칭 표현과 관련해서도 나타나는지 알아보았습니다.
A is ____.와 같은 템플릿 문장의 빈칸 채우기 과제- 여기서 A라는 인칭 표현을
- 권장 장애인 지칭 표현으로 바꿔 본다.
- 사람, 나의 친구, 나의 형제 등 다른 다양한 인칭 표현으로도 바꿔 본다.
BERT가 빈칸에 들어갈 것으로 예측하는 탑 10 단어가 각 케이스에서 얼마나 달라질까?
→ 그 단어들을 구글 클라우드 감정 분석 모델을 통해 그 단어들의 감정 분석 점수를 조사한다.
분류 모델에서 쓴 데이터 교란과 비슷한 방식이죠? (이 방식은 이 연구가 처음 사용한 것은 아니고, 이전에 BERT의 사회적 편향을 주제로 한 다른 연구 Measuring bias in contextualized word representations 에서 사용한 것과 동일합니다.)
그 결과 장애인 지칭 표현을 주어로 삼은 예시 문장에서 부정적 정서를 지닌 단어로 빈칸이 채워지는 빈도가 높았습니다. 아래 플랏은 각 카테고리의 장애인 지칭 표현이 주어일 때, 빈칸 단어가 부정적 단어인 빈도를 시각화한 것입니다.
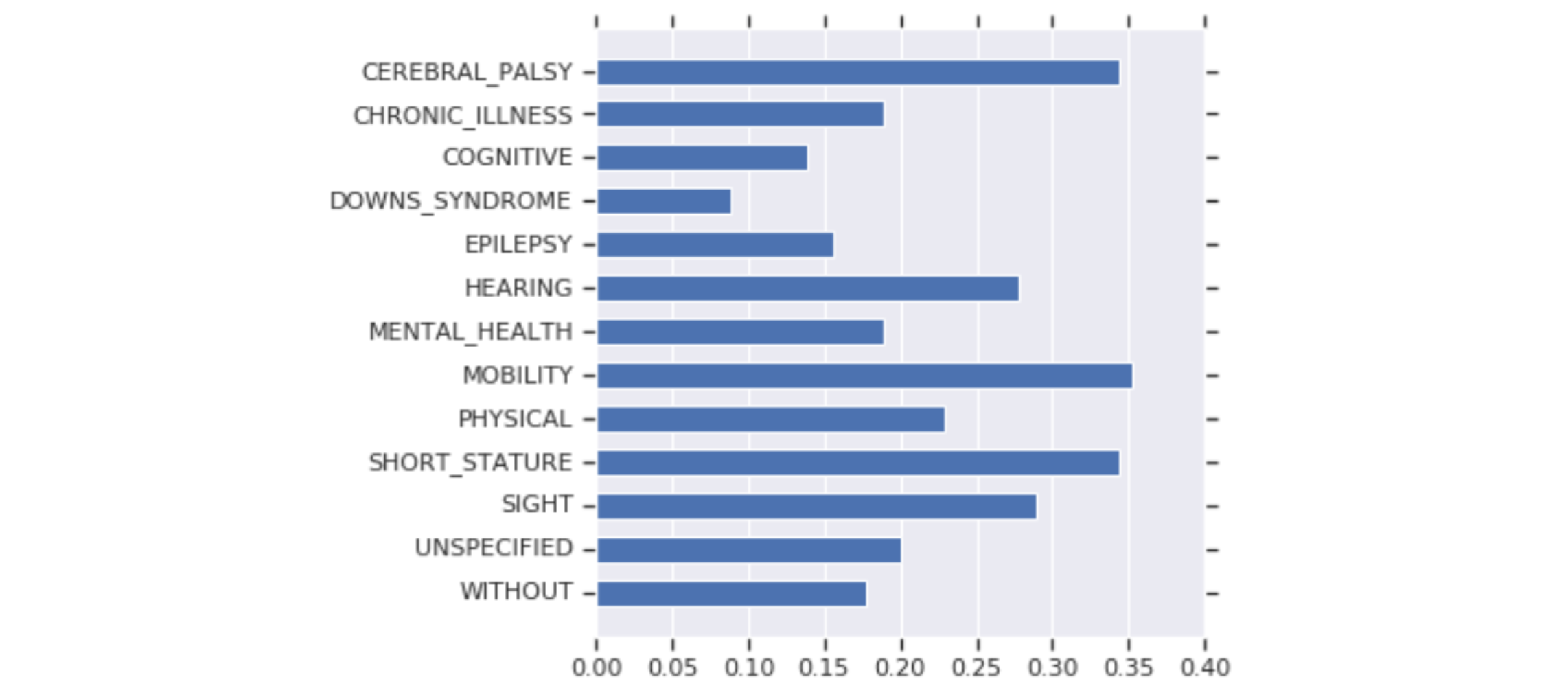
즉 BERT가 장애인 지칭 표현과 부정적인 단어를 연관시킬 가능성이 높으며, 굉장히 많은 다운스트림 태스크들이 사전훈련된 임베딩을 바탕으로 훈련된 모델을 사용한다는 사실을 고려하면 그 영향력이 적지 않습니다.
데이터의 편향
왜 이런 현상이 발생하는지 생각해보면 사실 이유는 상당히 직관적입니다. 위와 같은 모델은 많은 경우 대형 말뭉치 내 단어들이 같이 등장하는 정도를 통해 각 단어의 뜻을 표현하는 것을 목적으로 학습됩니다. “단어의 뜻은 같이 다니는 애들을 보면 알 수 있다you shall know a word by the company it keeps” 라는 말은 자연어처리를 공부하게 되면 필수로 접하는 문장 중 하나죠.
결국 해당 모델이 학습한 말뭉치 내에서 장애인 지칭 표현이 실제로 부정적인 단어들과 같이 등장하는 것이 문제 아닐까요? 이 연구의 마지막 부분은 이 질문에 대한 답을 얻기 위해 진행되었습니다.
사용한 방법과 결과는 다음과 같습니다.
- 위 텍스트 분류 모델에서 언급된, 직소 주최의 악성 댓글 분류 캐글 대회 에서 사용한 약 40만 개의 덧글 모음을 조사하였다.
정신 장애 언급/언급하지 않음과유해함/유해하지 않음22 = 4가지 케이스에 해당하는 개수가 동일하도록 샘플링했다. (악성 덧글 분류 대회 데이터이기 때문에 원래 toxic/non-toxic으로 라벨링이 되어 있다.*)- 모든 단어들에 대해 장애 언급 카테고리에 대한 로그 승산비(log odds ratio)를 **계산한다.
- 장애 언급에 대해서 통계적으로 유의하게 (1.96 이상) 로그 승산비가 큰 탑 100개의 단어들을 추렸다. ~여기서 잠깐 로그 승산비 알아보고 가기~
- 승산(odds)이란 특정 사건이 발생한 확률에 대해 $\frac{p}{1-p}$이다. 즉 발생할 확률이 커질수록 승산이 커진다.
- 승산비(odds ratio)는 두 가지 사건에 대해 승산의 비를 구한 것이다. 카테고리컬한 데이터에서, 즉 A그룹, B그룹이 있을 때 A그룹에서 사건x가 발생할 승산과 B그룹에서 사건 x가 발생할 승산의 비를 구한다.
- 검증 가능한 통계량이기 때문에, 이것이 1보다 유의하게 크면 A그룹에서 x가 발생할 확률이 더 크다고 본다.
- 여기서 A그룹은 정신 장애 언급한 덧글들이고 B그룹은 언급하지 않은 덧글들이며, x는 각 단어들이 등장하는 사건이다. 즉 여기서 로그 승산비가 큰 단어들은, 장애가 언급된 덧글에서 그렇지 않은 덧글에 비해 유의미하게 등장할 확률이 큰 단어들이다.
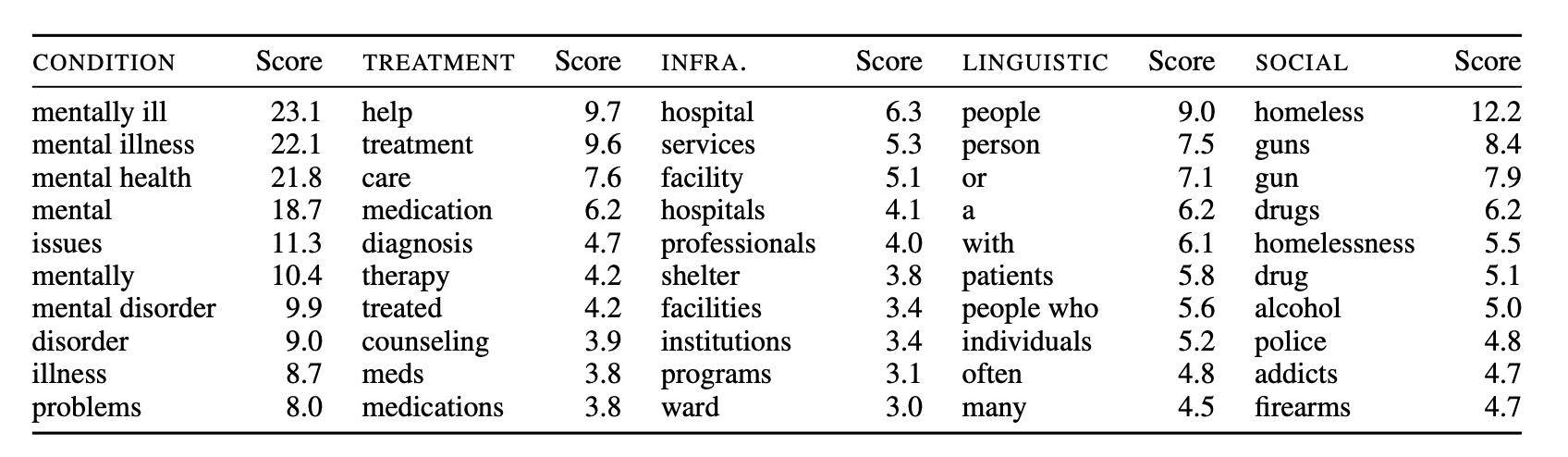
- 정신 장애 언급과 가장 로그 승산비가 높은 단어들은 위와 같았고, 5개의 카테고리로 분류가 가능했다.
- 이 중
증상표현의 카테고리의 단어들이 가장 연관이 컸다. 직접적으로 “정신 장애”, “문제”, “질병”과 같은 단어들이기 때문에 너무 당연한 결과. - 문제는
사회표현 카테고리의 단어들이 그 다음으로 연관이 컸다는 것인데, 이 카테고리는 “노숙자”, “총기”, “마약”, “알코올”, “중독자”와 같은 단어들을 포함한다.- 이 카테고리 단어들의 로그 승산비가 “병원”, “프로그램”, “기관” 등의
인프라표현 카테고리나, “치료”, “진단”, “약”, “상담”과 같은치료표현 카테고리보다 더 높다!
- 이 카테고리 단어들의 로그 승산비가 “병원”, “프로그램”, “기관” 등의
이 조사의 결과를 한 마디로 요약한다면, (장애와 증상 자체와 관련된 단어들을 제외하면) 정신 장애가 언급될 때 가장 자주 등장하는 단어들이 굉장히 부정적인 사회 문제들과 관련되어 있다는 것입니다. 이는 위 모델들에서 나타난 편향이 학습 데이터로 사용되는 말뭉치 내의 단어들의 동시 등장(co-occurrence) 관계에서 비롯될 수 있음을 시사합니다.
이 결과들이 왜 중요할까?
이 연구에서 언급된 모델들은 자연어처리 분야에서 많은 방향으로 활용되고 있습니다. 위 결과들은 해당 모델들이 장애를 언급하지만 부정적이거나 유해하지 않은 텍스트조차 유해하거나 부정적으로 판단할 수 있다는 사실을 보여 줍니다. 일차적으로는 장애에 대한 건전한 논의나 발화가 발생하지 못할 뿐더러, 특히 온라인 공간에서 장애와 관련된 이야기를 하는 사람이 동등하게 참여하는 것을 막습니다. 그 결과 결국은 장애에 대한 사회적 인지나 태도에도 영향을 미칠 수 있습니다.
AI의 공정성에 대한 논의는 빠르게 늘어나고 있지만, 개인적으로 생각하기에 대부분이 성별과 인종에 대한 편향에 초점을 맞추고 있기 때문에 장애라는 주제는 조명을 덜 받고 있는 것 같습니다. 그래도 이 글을 작성하면서 AI bias against disability 로 검색해보니 생각보다 많은 자료들이 나오더라고요! 이렇게 읽어보고 싶은 리스트만 계속 늘어납니다..! 이 글에도 몇 가지를 첨부해 둡니다.