자동화된 팩트 체킹은 어디까지 왔나
자연어처리 기술에 기반한 자동화된 팩트 체킹(Automated Fact Checking)의 현주소를 알아보고, ACL 2020에 등장한 관련 연구들을 소개합니다.
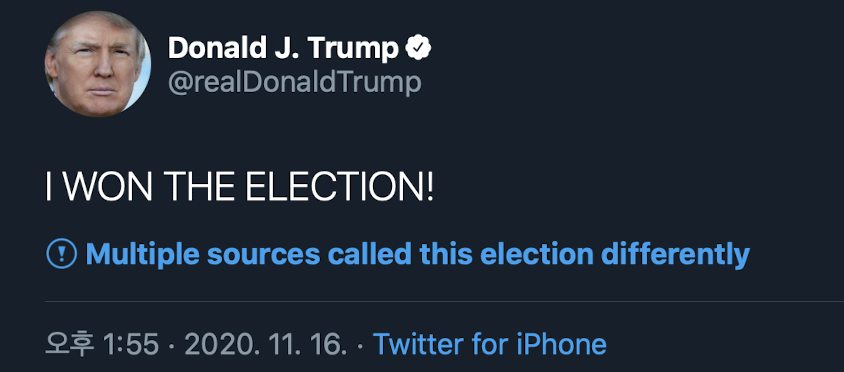
미국 대선을 볼 때마다 한국 사람으로서 가장 놀라운 점 중 하나는 개표 속도가 아닐까 합니다. 아니 선거가 11월 3일인데 7일에 당선인이 정해지다니! 게다가 (이번에도) 트럼프가 모든 여론 조사가 예측했던 것보다 더 선전했고, 박빙의 경합주에서는 두 후보 간 표차가 매우 적었던 상황이라 개표 중간에 섣불리 결론을 내리는 것에 대해 매우 조심스러워야 했던 상황이었습니다.
전세계 초미의 관심사이다 보니 잘못된 정보도 빠르게 퍼지기 쉽습니다. 잘못된 정보가 불러일으키는 위험은 코로나를 겪으면서 더욱 더 실감하게 된 문제이죠. 개표 기간 중에 트위터나 페이스북 같은 플랫폼에서는 아직 결정되지 않은 결과를 언급하거나, 이미 결과가 정해진 주에 대해서 잘못 이야기하는 게시물에 대해 자동으로 경고문을 붙이기 시작했습니다. “이 트윗이 작성되었을 때 아직 공식 결과는 발표되지 않았습니다.” 혹은 “여러 공식적인 출처에서 선거 결과를 이 글과 다르게 이야기합니다” 라는 식으로요.
그 결과 트럼프의 거의 모든 트윗에 파란 딱지가 달렸고, 경고 문구를 누르면 바이든 당선 기사로 연결되도록 표시되고 있습니다. (기사)
신비로운 자동 딱지의 향연을 보면서 오 이걸 어떻게 잘 할 수 있을까? 얼만큼 자동으로 할 수 있는 건가? 그냥 트럼프 트윗에 다 붙이는 건 아니겠지? 하는 궁금증이 생겼는데요. 궁금하면 해봐 Fact check 라고 리사님이 말씀하셨죠. 오늘은 자동화된 팩트 체킹이 어떻게 작동하는지, 그리고 어디까지 가능한지 살펴 보겠습니다.
자동화된 팩트 체킹(Automated Fact Checking; AFC)의 단계들
우선 전반적인 단계나 접근 방식은 이 문서를 주로 참고하였습니다.
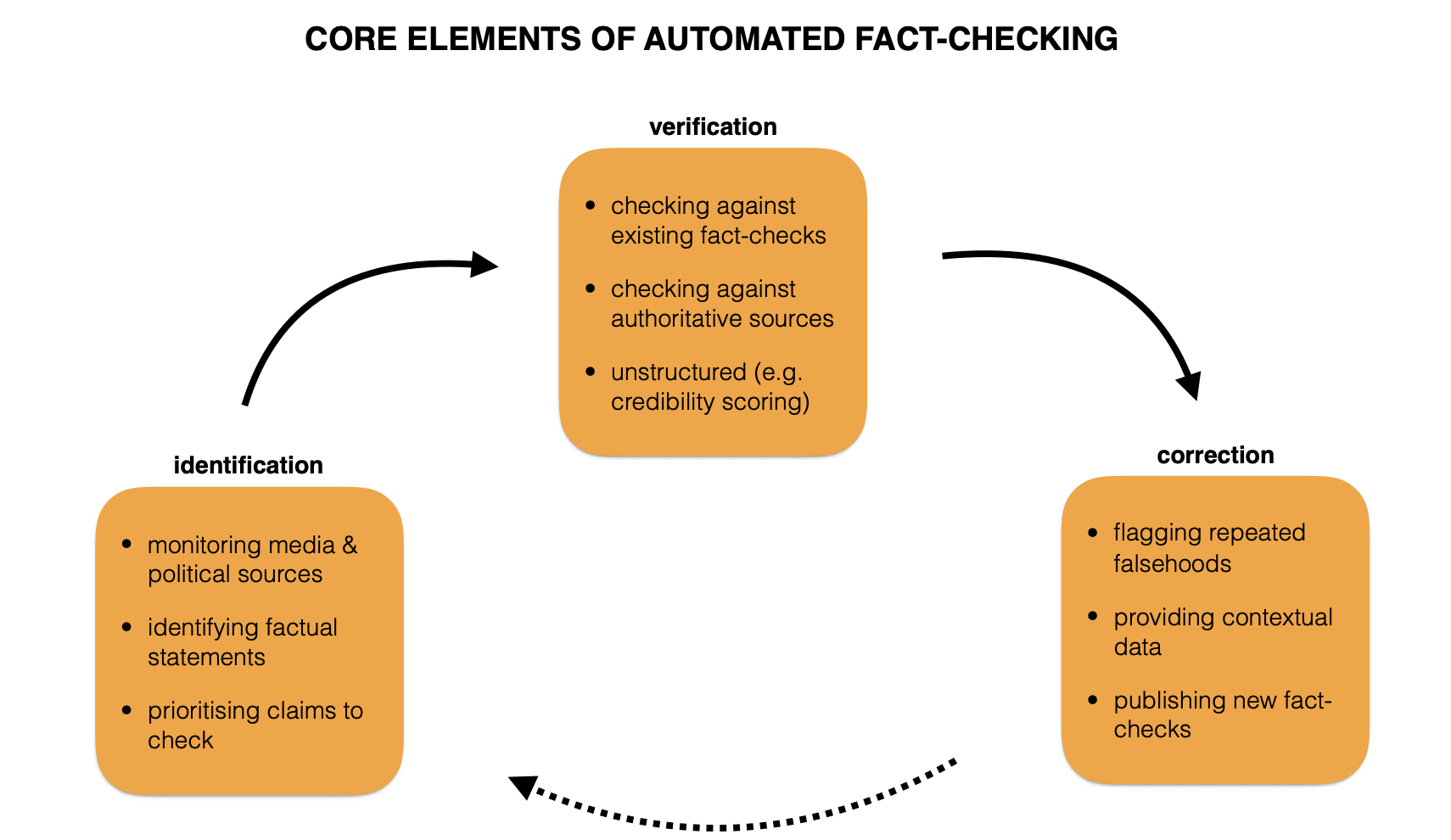
- 주장 발견하기 : 각종 미디어나 정치적 발언 등에 등장한 진술들 중 검증이 필요한 주장이 어떤 것인지 찾아내는 단계
- 주장 검증하기 : 다양한 방식으로 주장의 진실성을 검증하는 단계
- 주장 수정하기 : 잘못된 주장에 경고를 달거나 유관한 데이터를 함께 제공하거나 정정 보도를 하는 단계
3번 단계는 나온 결과를 활용하는 것에 가깝고, 가장 궁금한 부분은 어떤 주장을 팩트 체킹 할 것인지 찾아내는 것과 팩트 체킹을 어떻게 할 것인지 이 두 가지로 나뉘는 것 같네요.
단계별로 살펴보면서 ACL 2020에 등장한 동일 분야의 논문을 같이 소개하도록 하겠습니다. 올해 여느 때보다 더 많은 논문이 제출된 만큼 팩트 체킹 관련 연구 또한 많이 찾아볼 수 있었는데, 이 글에는 각 연구의 주요 컨트리뷰션 정도만 살짝 공유해 볼게요.
무엇을? : 주장 발견하기
자동화된 팩트 체킹이 발전하기 시작하기 이전의 팩트 체킹은 Politifact, factcheck.org, The Fact Checker 등 여러 기관이나 언론사에서 일하는 전문가들이 주요 기사나 정치인의 발언에 대해 직접 검증을 하는 방식으로 이루어졌습니다. 그러나 선거철 같은 때 매 순간 수많은 발언과 보도가 쏟아진다면, 사람이 모든 주장을 하나하나 검증하기는 어려울 것입니다. 그래서 자동화된 팩트 체킹이 이 전문가들을 도와줄 수 있는 가장 첫 단계는 검증할 가치가 있는 주장만 볼 수 있도록 추려 주는 것입니다. 또 이 단계는 NLP와 머신 러닝이 가장 눈에 띄는 성과를 보인 부분이기도 합니다.
팩트 체킹 도구 클레임버스터(ClaimBuster)는 특정 문장을 입력하면 해당 문장이 얼마나 검증할 만한 주장인지 0부터 1까지의 점수로 돌려줍니다. 검증할 만하다는 것은 일단 진위 여부가 갈리는 내용이어야 하며, 또 너무 뻔하거나 아무도 관심 없을 사소한 내용이어서도 안 된다는 뜻입니다. 개발 과정을 자세히 살펴보면, 클레임버스터는 과거 대선 토론에서 등장했던 2만 개의 문장들을 전문가에 의해 다음 세 가지 범주로 분류하여 훈련 데이터로 사용했습니다.
- Non-factual: 사실과 관련 없는 주관적 믿음을 담은 문장 - 예) “이제 우리는 미래에 대해 이야기할 때라고 생각합니다.”
- Unimportant Factual: 검증할 필요도 없을 정도의 사실이거나 진위 여부를 가릴 만큼 중요하지 않은 문장 - 예) “선거는 다음주 화요일입니다.” 혹은 “어제 우리 같이 점심 먹었죠.”
- Check-worthy Factual: 진위를 밝히기 어렵고 검증할 가치가 있는 문장 - 예) “현재 미국인의 HIV 유병율은 0.5%입니다.”
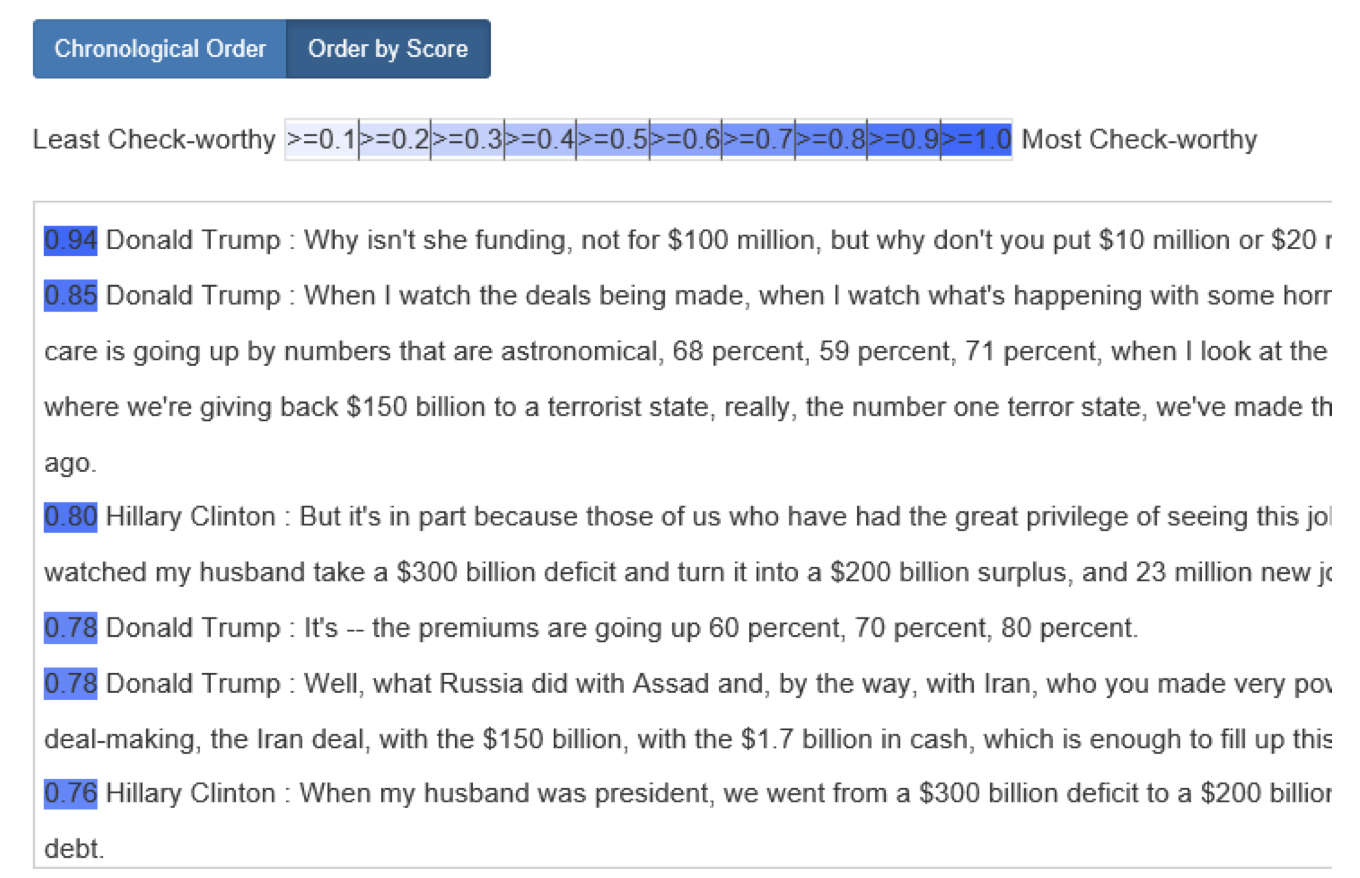 위 그림처럼 모델은 2016년 당시 각 대선 후보의 발언에 대해 검증할 만한(check-worthy) 문장들만 추려서 보여 줍니다. SVM을 사용했고, 미국 예비선거에 적용한 결과 검증 가치 있는 사실 문장 클래스에 대해 74%의 재현율, 79%의 정밀도라는 결과를 얻었다고 합니다(실제 CNN, Factcheck.org와 Politifact의 전문가 결과와 비교).
위 그림처럼 모델은 2016년 당시 각 대선 후보의 발언에 대해 검증할 만한(check-worthy) 문장들만 추려서 보여 줍니다. SVM을 사용했고, 미국 예비선거에 적용한 결과 검증 가치 있는 사실 문장 클래스에 대해 74%의 재현율, 79%의 정밀도라는 결과를 얻었다고 합니다(실제 CNN, Factcheck.org와 Politifact의 전문가 결과와 비교).
✨ 주장 발견에서 발생하는 빈도 편향을 완화하기 @ ACL2020
Masking Actor Information Leads to Fairer Political Claims Detection 는 주장 발견하기 단계에서 발생할 수 있는 편향을 완화하는 방법을 제시한 연구입니다. 사실 이 연구 자체보다도 (2016년 말고) 최근에 이 태스크에서 가장 성능이 좋은 모델은 뭔지 궁금해서 그 부분부터 봤는데, 동 저자의 이 연구가 현재 베스트라고 하고, 동일하게 BERT+소프트맥스 분류기(문장 단위로 분류)를 썼네요.
아무튼 이 논문의 주요 기여점은 다음과 같습니다. 정치적 주장을 발견한다는 것은 1) 행위자 2) 주장 3) 행위자와 주장의 관계를 찾아내는 것을 의미하는데요(예컨대 “어제 베를린의 국무회의에서 앙겔라 메르켈은 신속한 감세를 요구했다.“라는 문장이 있다면 행위자는 메르켈, 주장은 신속한 감세, 관계는 지지함으로 볼 수 있습니다). 문제는 행위자가 얼마나 자주 등장하는 사람인지에 따라 모델의 성능 차이가 난다는 것입니다. 즉 데이터에 자주 등장하는 사람, 예컨대 유명한 정치인이나 장관, 국무총리의 발언만 잘 인식한다는 것이죠. 이 연구는 모델 훈련 시에 행위자나 행위자를 지칭하는 대명사를 마스킹함으로써 큰 성능의 감소 없이 이러한 편향을 줄일 수 있다는 것을 보여주었습니다. 특히 마스킹 모델이 다른 도메인의 텍스트(예를 들면 이민 관련 토론 → 핵 에너지 관련 토론)에 적용해도 일반화 성능이 좋다고 합니다.
어떻게? : 주장 검증하기
팩트 체킹해 볼 가치가 있는 주장들을 성공적으로 추출해냈다면, 이제 이 주장들을 검증해 봅시다.
기존에 검증 완료된 사실과 매칭: 이미 다른 기관이나 전문가가 팩트 체킹을 완료한 주장이라면 새로 들어왔을 때 굳이 그 주장을 다시 검증할 필요는 없을 것입니다. 따라서 검증의 가장 쉬운 방법은 이미 기존에 누군가가 이걸 검증한 적이 있는지를 확인하는 것이죠. 정보 검색(retrieval)과 텍스트 유사도 판단의 영역일 것으로 보입니다.
✨이미 진실/거짓임이 알려져 있는 주장 찾기 #ACL2020
That is a Known Lie: Detecting Previously Fact-Checked Claims 는 이 분야의 가장 최신 연구인데요, 이 논문에서는 이 태스크가 실질적으로 팩트 체킹에 가장 큰 도움을 줄 수 있는데도 불구하고(“정치인들은 참이든 거짓이든 자기가 좋아하는 말을 반복해서 하는 경향이 있다”) 그간 연구가 많이 진행이 안 되었다고 하네요. 이 연구는 검증 완료된 주장들을 가지고 있는 상태에서 검증이 필요한 문장을 인풋으로 받아, 인풋 문장을 검증하는 데 도움이 되는 문장의 순위를 매기는 것을 주요 태스크로 정의했습니다. 팩트 체킹 웹사이트인 Politifact와 Snopes에서 검증 완료된 주장들을 가져와 새로운 데이터셋을 만들어 공개했고요. 최근 정보 검색 분야에서 가장 높은 성능을 내고 있는 방식인 1) BM25를 이용한 검색 2) BERT류 모델 기반 코사인 유사도를 계산 후 re-ranking을 하는 방식을 택하고 있습니다.
그래프 기반 접근 : 위키피디아와 같은 문서를 기반으로 모든 진술에 대해 주어를 노드로, 서술어를 엣지로 보아 일종의 지식 그래프를 구축하는 방식입니다. 자세히 살펴보면, 특정 주장이 들어오면 해당 그래프 내에서 등장하는 개념들 간 최단거리를 측정합니다. 두 개념의 노드 간 거리가 가깝고 그 사이의 노드들에 많은 엣지가 연결되어 있지 않을수록(보편적이지 않은 개념) 해당 주장이 진실일 확률이 크다고 봅니다.

예를 들어 “버락 오바마는 무슬림이다”라는 주장은, 오바마 노드와 이슬람 노드 간에 위와 같은 수많은 노드들이 있는 데다가 중간의 캐나다 같은 경우는 너무 많은 엣지와 연결되어 있어 그 연결이 의미 있다고 보기 어렵습니다. 즉 높은 확률로 사실이 아닐 것입니다.
공식적인 출처의 증거 기반 접근 : 사실 또는 증거라고 부를 수 있는 데이터셋을 수집, 구축해서 이를 기반으로 주장의 사실성을 예측하는 것입니다. 이런 접근은 데이터셋 구축 자체가 매우 어렵고 여러 면에서 한계가 발생하기 쉬울 것 같은데요. 이런 연구가 이 접근의 예시인데, 가장 잘 나온 모델의 매크로 F1 스코어가 0.49 (!) 였다네요…💦
✨설명 가능한 팩트 체킹 #ACL2020
Generating Fact Checking Explanations 는 이처럼 증거 기반으로 팩트 체킹을 할 때, 인풋 주장에 대해 단순히 사실성을 예측만 하는 것이 아니라, 왜 사실 또는 거짓으로 판단되는지 근거가 되는 증거(즉 팩트 체킹의 설명)을 함께 제공하는 것을 목적으로 이루어진 연구입니다. 사전훈련된 DistilBERT 기반으로 1) 설명을 추출하는 모델 2) 사실성을 예측하는 모델 3) 두 모델의 joint 모델을 훈련시켰고, 멀티 태스크 모델이 단순히 추출 모델보다 훨씬 더 설명 시스템의 질이 좋았다고 합니다.
 예시 - 주장에 대한 판단결과(label), 각 모델이 제공하는 설명
예시 - 주장에 대한 판단결과(label), 각 모델이 제공하는 설명
완전한 자동화가 가능할까?
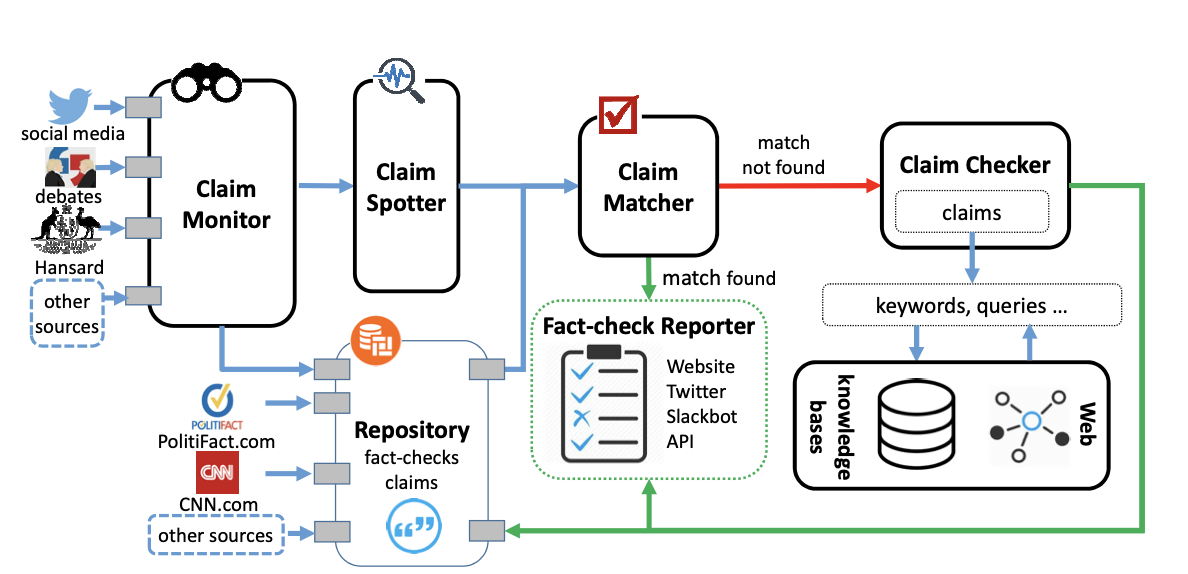
다양한 접근이 있지만, end-to-end로 온전히 자동화된 팩트 체킹 시스템은 현재까지는 갈 길이 먼 것으로 보입니다. 팩트 체킹을 할 만한 문장들을 추려 주거나 이미 기존에 검증된 주장을 찾아주는 등, 지금까지 자연어처리 기반 AFC 기술은 팩트 체킹 전문가의 시간을 절약해주는 보조 역할에 그치고 있습니다. 지식그래프 같은 비구조적 접근이 흥미롭기는 하지만, 이 또한 맥락이 없는 명확하고 간단한 진술문을 인풋으로 요구하기 때문에 한계가 있고요. 그래도 클레임버스터 등 많은 자동화 도구들이 완전한 시스템을 목표로 개발하고 있으니 계속 지켜봐도 좋을 것 같습니다. 한 번의 클릭으로 너무 쉽게 정보가 퍼질 수 있는 시대에 자동화된 팩트 체킹은 활용성이 무궁무진한 영역이니까요.