차별하지 않는 분류 모델 만들기
머신러닝 모델의 공정성(Fairness)에 대한 튜토리얼을 목적으로 작성된 글입니다. 공정성 논의가 등장한 배경, 정의, 완화 기법을 살펴보고 관련 툴킷인 AIF 360을 대출 승인 예측 모델에 사용해 봅니다.
공정한 모델은 왜 필요할까?
COMPAS라는 소프트웨어는 각 피고에 대해 성별, 나이, 인종, 전과, 사는 지역, 사회경제적 수준 등 다양한 데이터를 기반으로 이 사람이 다시 범행을 저지를지 아닐지를 예측하여, 재판 과정에서 형량이나 가석방 여부에 대한 결정을 보조해 줍니다. 머신 러닝 분류 모델을 개인의 인생에 큰 영향을 미치는 의사결정 수단으로 사용하는 전형적인 예시라고 할 수 있겠습니다.
 알고리즘이 재범하지 않을 것으로 예측했으나 이후 3번이나 동일 범죄로 체포된 경우와 높은 위험으로 예측되었으나 재범하지 않은 경우 출처
알고리즘이 재범하지 않을 것으로 예측했으나 이후 3번이나 동일 범죄로 체포된 경우와 높은 위험으로 예측되었으나 재범하지 않은 경우 출처
미국의 여러 주에서 실제로 법정에서 활용되던 이 소프트웨어는 2016년에 일관되게 흑인 피고들에게 불리한 결론을 내 온 것이 프로퍼블리카지에 의해 폭로되어 비난 받게 됩니다. 그리고 지금처럼 위험한 AI의 예시로 두고두고 쓰이게 되었죠. 폭로 기사에 따르면 당시 COMPAS는 피고가 흑인일 경우 이후 그 사람이 실제로 재범하지 않았음에도 판결 시 재범 위험이 높은 것으로 예측한 경우가 많았는데, 이 FPR(거짓 양성 비율)이 무려 45%에 달했다고 합니다. 백인의 경우 반대 케이스인, 낮은 위험으로 예측했으나 다시 범죄를 저지른 경우가 그만큼 많았고요.
왜 이런 현상(Bias)이 발생할까요? 그건 데이터가 불균형하기 때문일 수도, 혹은 실제로 사회에 존재하는 편향이 데이터 자체에 포함되어 있기 때문일 수도 있습니다. 머신러닝 모델의 편향의 근원에 대해서는 또다른 아주 많은 얘기가 따라올 수 있어 이번 글에서는 자세히 다루지 않겠습니다.
위험은 이 특정 분야에만 있는 게 아니며, 수치형 데이터에 기반한 분류기에만 한정된 이슈도 아닙니다. 2015년에 구글 포토가 흑인의 얼굴을 고릴라로 분류해서 구글이 사과하는 사건이 있었고, 그 이후로도 안면인식 모델이 소수 인종에 대해서만 유달리 낮은 정확도를 보인다는 문제제기는 지속되고 있습니다. 2018년에는 아마존이 채용 시 사용하는 이력서 스크리닝 알고리즘을 개발했으나, “여성 체스 클럽”처럼 지원자가 여성임을 암시하는 단어가 포함되기만 해도 낮은 점수를 주어 개발을 중단했다고 알려졌습니다.
 구글에 Racist AI를 검색하면 나오는 수많은 사진 중 하나 - 저화질 이미지를 복구해주는 PULSE(StyleGAN 기반)가 누가 봐도 미국의 첫 흑인 대통령의 얼굴인 사진을 받아 백인 남자의 얼굴을 내놓았다 출처
구글에 Racist AI를 검색하면 나오는 수많은 사진 중 하나 - 저화질 이미지를 복구해주는 PULSE(StyleGAN 기반)가 누가 봐도 미국의 첫 흑인 대통령의 얼굴인 사진을 받아 백인 남자의 얼굴을 내놓았다 출처
모델의 성능이 좋고 얼마나 놀라운 일을 해내는지와는 별개로 그 결과물을 우리 사회에서 사용하려면 특정 인구 집단에 대해 차별적이지 않아야 합니다. 이 부분에 대한 사회적인 신뢰와 합의가 보장되지 않는다면, 아무리 날고 기는 모델이라도 신용 평가, 정책, 치안, 입시, 채용, 의료 분야에서 실제 중요한 결정을 내리는 데 쓰기는 어렵겠죠. 아무도 내 실제 능력과 무관하게 변경할 수 없는 어떤 특성 때문에 대출을 받지 못하거나, 좋은 채용 기회를 놓치거나, 심지어 불필요한 옥살이를 하고 싶지는 않을 테니까요. (그리고 현재까지의 사례들을 보면 백인 남성을 제외한 대부분의 인구 집단은 그런 걱정에서 자유롭지 못할 것 같네요.)
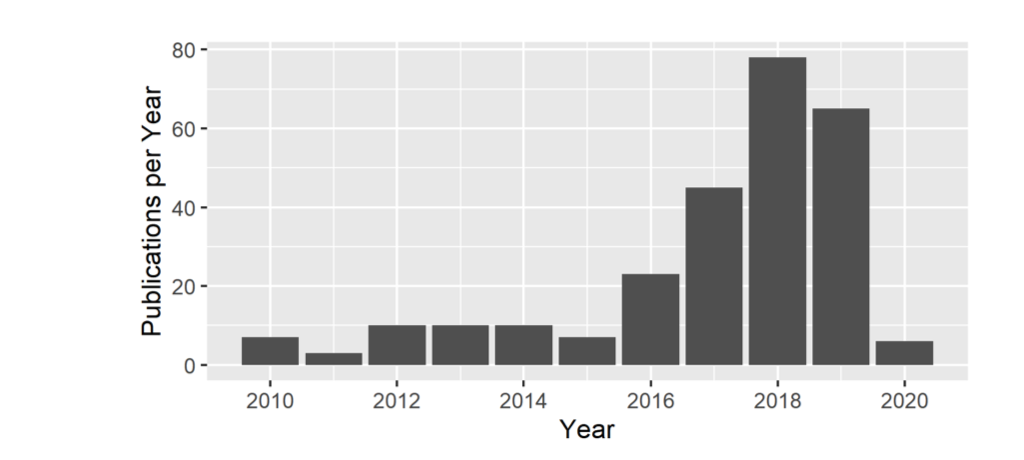 학계에서도 최근 5년 간 상당히 주목 받는 주제 중 하나로, ML Fairness를 다룬 논문들의 수는 해마다 증가하고 있다. 이 차트가 2020년 중간에 그려졌기 때문에 2020년 값은 빼고 보자 출처
학계에서도 최근 5년 간 상당히 주목 받는 주제 중 하나로, ML Fairness를 다룬 논문들의 수는 해마다 증가하고 있다. 이 차트가 2020년 중간에 그려졌기 때문에 2020년 값은 빼고 보자 출처
공정하게 대출을 승인해주는 분류 모델을 만들어보자 (f. AIF 360)
공정한 모델을 어떻게 얻을 수 있을까요? 잠시 법정에서 은행으로 영역을 이동해 보겠습니다. 우리는 대출을 신청한 사람들의 각종 개인 정보와 은행에서 실제로 빌려주었는지 여부를 포함한 데이터를 가지고 있습니다. 이 데이터를 통해 새로운 신청자에게 빌려줄까 말까를 스스로 판단하는 분류기를 학습시키려고 합니다.
사용 데이터와 Baseline 모델
캐글에서 받아왔습니다.
- 대출을 신청한 개인 $i$의 각종 특성들: $X_i \in \mathbb{R}^n$
- 성별, 결혼 여부, 부양가족 수, 교육 수준(
Graduate/Not Graduate), 자영업 여부, 신용 점수 과락 통과 여부, 지역(Urban/Rural/Semiurban), 본인 수입, 공동 신청자의 수입, 신청 금액
- 성별, 결혼 여부, 부양가족 수, 교육 수준(
- 예측하고자 하는 값: 실제 대출의 승인 여부 $Y_i = { 0,1 }$
- 모델, 결정 규칙 $d$ : $d(X_i) = 1$ 이면 빌려주자.
대부분의 공정성 논의에서는 모델이 차별하지 않고자 하는, 즉 상식 상 혹은 특정 맥락에서 만약 차별이 있다면 한 집단이 다른 집단에 비해 이득을 볼 것으로 생각되는 어떤 변수를 선 지정하게 됩니다. 제가 위에서 언급했던 사건들에서는 인종이나 성별이 해당되겠죠. 문헌에서는 주로 이를 민감한 속성(sensitive attributes) 혹은 보호 속성(protected attributes)라는 이름으로 부르는데요. 우리는 전자를 골라 아래처럼 표기하고, 교육 수준이라는 변수를 선택해보겠습니다.
- 차별하지 않고자 하는 민감한 속성: $X_s \subset X$
- 교육 수준(고등학교 졸업 여부)
오늘 함께 사용할 AI Fiarness 360 (AIF 360)은 머신러닝 모델의 편향을 테스트하고 완화하는 다양한 테크닉들을 포함한 오픈소스 툴킷으로, 파이썬과 R을 둘 다 지원합니다.
저는 파이썬을 사용하도록 하겠습니다. 우선 보통 많이 사용하는 Pandas 데이터프레임 형태에서 다음과 같이 AIF 360이 잘 받아먹을 수 있는 StandardDataset으로 변경할 것인데, 거의 유사하지만 공정성 판단에 필요한 정보(민감한 속성과 이득을 보는 집단, 그리고 예측 라벨 중에 무엇이 이득인지)을 지정해준 버전의 데이터프레임이라고 생각하면 됩니다. 이 데이터셋을 가지고 모델 학습도 하고(Scikit-learn과 호환성이 꽤 괜찮습니다) AIF360 이 제공하는 각종 테스트와 완화 기법을 적용할 겁니다.
1
2
3
4
5
data = StandardDataset(df, label_name='Loan_Status',
favorable_classes=[1],
protected_attribute_names = ['Education'],
privileged_classes=[0])
#df는 아래 모델학습 단계 중 최소한의 전처리를 마친 Pandas dataframe
favorable_classes: 예측 라벨인Loan_Status중 무엇이 이득인지 (여기서는 1=대출 승인)protected_attribute_names: 미리 정한 민감한 속성 (여기서는 교육수준)privileged_classes: 민감한 속성 변수의 라벨 중 중 차별이 있다면 이득을 볼 것으로 생각되는 집단 (여기서는 0=고등학교 졸업자)
우선 아무것도 하지 않고 모델 학습을 진행해 보겠습니다.
- 최소한의 전처리
- 결측치 최빈값 또는 평균으로 imputation
- 카테고리컬 변수(성별, 결혼여부, 교육, 자영업 여부, 신용점수의 과락 통과 여부, 지역)의 인코딩
- 수치형 변수(본인 수입, 공동 신청자의 수입, 신청 금액, 부양가족 수)의 스케일링
- 학습, 테스트 셋 7:3으로 분리
1
2
#StandardDataset은 바로 split 메서드를 지원, sklearn과 달리 트레이닝 셋의 비율을 입력한다.
train, test = data.split([0.7], shuffle=True)
- 모델 학습
- RandomForestClassifier 사용
1
2
3
4
5
6
7
8
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score
base_rf = RandomForestClassifier().fit(train.features, train.labels.ravel(),
sample_weight=train.instance_weights)
base_rf_pred = base_rf.predict(test.features)
print('Accuracy Score: ', accuracy_score(base_rf_pred, test.labels.ravel()))
print('F1 Score: ', f1_score(base_rf_pred, test.labels.ravel()))

데이터 크기가 600개 남짓인 데다 아무것도 안 한 것 치고는 뭐 그럭저럭인 것 같습니다. 어차피 성능을 높이는 건 이 글의 주안점이 아니니 넘어갑시다.
그 다음에 가장 먼저 해야 할 일은 과연 우리의 분류기가 공정한지 테스트부터 해보는 것입니다. 문제가 없는데 해결할 수는 없는 법, 의외로 문제가 없을 수도 있지 않을까요?
‘공정한’ 게 뭔데?
테스트를 해보자니 당연히 공정함이 대체 뭔데? 라는 의문이 먼저 들 것입니다. 단순히 백인을 10명 가석방시키는 동안 소수인종을 10명 가석방시키면 공정할까요? 입사 점수가 동일하면서 불합격한 인원의 비율이 남녀 간 차이가 없으면 공정할까요? 이런 질문에 일반적인 답을 하려면 왠지 엄청난 철학 공부가 필요할 것 같은 기분이 드는데요, 제가 그쪽의 능력은 전혀 없고요. 아마 머신러닝 모델도 아직 그럴 능력은 없을 겁니다. 모델이 이해하려면 수식으로 쓰인 정의가 필요하죠. 다만 정의가 수식이라는 것보다 더 중요한 사실은, 정의가 여러 가지라는 것입니다.
의외의 사실은 아니겠지만 무엇이 공정한 모델이냐는 질문에는 여러 가지의 답이 있고 그에 따른 여러 가지의 정의와 여러 가지의 수식이 있습니다. 이 분야가 처음 주목받기 시작한 이래로 여러 학자들이 너도나도 각자 자신이 생각하는 공정함의 정의를 들고 왔고, 심지어 어떤 논문은 남이 들고 온 정의들의 양립 불가능성(얘가 주장한 A랑 쟤가 주장한 B랑 동시에 만족하는 건 수학적으로 불가능해!)을 증명하기도 했습니다.
결국 완벽하게 합의된 정의는 없습니다. 만약 모델을 만들고 사용하는 누군가가 공정한 모델을 원한다면 그 모델의 사회적 활용의 방향성과 본인의 주관에 따라 적절한 정의를 선택해야 하는 상황이 되겠습니다. 이제 제가 왜 위 소제목에서 ‘공정한’에 따옴표를 쳤는지 알겠죠(공정함은 당신 마음 속에 🌟).
AIF360의 ClassificationMetric 클래스를 이용하면 이진분류 모델을 받아 기본적인 분류모델의 성능 관련된 수치들과 각종 공정성 관련 평가지표들을 쉽게 알아볼 수 있습니다. (문서)
1
2
3
4
5
6
7
8
9
10
11
12
pgroup = [ {'Education':data.privileged_protected_attributes[0]} ]
upgroup = [ {'Education':data.unprivileged_protected_attributes[0]} ]
test_pred = test.copy()
test_pred.labels = base_rf_pred
metrics = ClassificationMetric(dataset = test,
classified_dataset = test_pred,
privileged_groups = pgroup,
unprivileged_groups = upgroup
)
#(un)previleged_groups에는 각 민감한 속성:이익/불이익 집단을 딕셔너리화하여 리스트로 합쳐서 넣어주면 된다
그 중에서 우리는 다음 4가지의 지표를 살펴보겠습니다. 이때 앞서 언급한 $X$, $Y$, $d(X)=\hat Y,$ $X_S \subset X$ 의 노테이션은 그대로 사용합니다. $X_S=0$ 이 고등학교 졸업자, $Y=1$이 대출 승인입니다.
- Statistical Parity Difference
- 양성 예측 비율(Positive rate)이 집단 간 동일하면 공정한 모델이라고 본다. 즉, 고등학교 졸업자 중 갚을 것이라고 예측한 사람의 비율과 비졸업자 중 갚을 것이라고 예측한 사람의 비율이 같으면 된다.
불공정의 정도는 아래와 같이 차이를 구해서 사용 → 불공정할수록 더 작은 (음수) 값이며, 0이 이상적
\[P_{X_S=0}[d(X)=1] - P_{X_S=1}[d(X)=1]\]
- Error Rate Difference
- 정확도(Accuracy)이 집단 간 동일하면 공정한 모델이라고 본다. 고등학교 졸업자에 대한 예측 정확도와 비졸업자에 대한 예측 정확도가 동일하면 된다.
불공정의 정도는 아래와 같이 차이를 구해서 사용 → 불공정할수록 더 큰 값이며, 0이 이상적
\[P_{X_S=1}[d(X) \neq Y] - P_{X_S=1}[d(X) \neq Y], Y \in \{0,1\}\]
- False Positive Rate Difference
- 거짓 양성 비율(False Positive Rate)이 집단 간 동일하면, 즉 예측과 민감한 속성이 라벨에 대해 조건부 독립이면 공정한 모델이라고 본다.
불공정의 정도는 아래와 같이 차이를 구해서 사용 → 불공정할수록 더 큰 값이며, 0이 이상적
\[P_{X_S=1}[d(X) =1 \vert Y=0] - P_{X_S=0}[d(X)=1 \vert Y=0]\]
- False Discovery Rate Difference
- 거짓 발견 비율(False Discovery Rate)이 집단 간 동일하면, 즉 모델의 라벨과 민감한 속성이 예측이 주어졌을 때 조건부 독립이면 공정한 모델이라고 본다.
- 불공정의 정도는 아래와 같이 차이를 구해서 사용 → 불공정할수록 더 큰 값이며, 0이 이상적
이 외에도 많은 정의들이 있지만, 정답은 뭐다? 각자의 마음속에 있다… 다만 어떤 정의들의 한계는 명확히 보입니다. 예를 들어 양성 비율만 보는 경우, $Y$와 $X_S$의 상관을 완전히 무시하게 되죠. 또 만약 어떤 집단에서는 진짜 능력 있는 사람만 1로 예측하고 다른 집단에서는 랜덤하게 아무나 1로 예측한다면 이는 상식적으로 불공정하지만 비율만 같으면 이 기준에서는 공정하게 보일 것입니다. 반면 정확도만 본다면, 한 집단의 FPR과 다른 집단의 FNR 간의 trade가 발생할 수 있습니다. 어떤 경우 한 집단의 능력 있는 사람을 거절하는 비율을 높이고, 다른 집단의 능력 없는 사람에게 대출을 해주는 방식으로 정확도가 동일하게 유지될 수 있는 위험이 있죠.
어쨌든 우리의 막 만든 모델에 대해 4가지 값을 확인해 보면 이렇습니다.
1
2
3
4
5
print('Statistical Parity Difference: ', -metrics.statistical_parity_difference())
print('Error Rate Difference: ', metrics.error_rate_difference())
print('False Positive Rate Difference: ', metrics.false_positive_rate_difference())
print('False Discovery Rate Difference: ', metrics.false_discovery_rate_difference())

metrics의 모든 수치는 일정하게 (비졸업자 수치 - 졸업자 수치)라 다른 건(Error, FPR, FDR) 다 높을수록 불공정한 거지만 statistical parity만 반대라서 헷갈리지 않도록 부호를 바꿔, 다른 메트릭과 동일하게 클수록 불공정하도록 했습니다.
단순 양성 비율만 보는 지표를 제외한 나머지 지표들에서는 우리의 베이스라인 모델이 고등학교를 나온 사람에게 유리한 결정을 내리고 있다는 사실을 알 수 있습니다. 특히 COMPAS 케이스처럼 FPR의 차이가 38%대로 눈에 띕니다.
신기한 점은 양성 비율만 봤을 때는 고등학교를 졸업하지 않은 사람의 양성 비율이 8% 정도 더 높다는 것입니다. 즉 같은 모델인데도 어떤 지표를 보면 불공정하고 다른 지표를 보면 별 문제 없어 보인다는 것, 그래서 모델을 만들고 데이터를 사용하는 사람의 주관적 결정이 중요하다는 것이 결론이 되기도 하겠습니다.
어떻게 해결하지?
위의 등장한 정의들은 일종의 메트릭입니다. 그리고 방금 제 모델이 그랬듯 아무런 조치 없이 모델을 훈련시킨다면 아마 공정의 정의를 무엇으로 선택하든 만족하지 못할 확률이 높을 겁니다. 그러면 이제, 이 불공정한 모델을 어떻게 고쳐볼까의 질문으로 넘어가 봅시다.
공정함의 조건을 만족하지 못하는, 즉 편향이 있는 모델에 대해 편향을 완화(mitigation)시키는 테크닉들은 크게 어떤 단계에서 행하느냐에 따라 전처리, 학습, 사후 처리 이렇게 3가지로 나뉩니다. 요약해 보면 다음과 같습니다.
- 전처리를 통한 편향 완화 (Pre-Processing)
- 모델의 인풋 데이터를 잘 고쳐보자!
- 데이터를 리샘플링하거나 가중치를 잘 분배해보기
- 집단 간 클래스 라벨을 뒤집어보기
- 민감한 특성을 아예 생략해보기
- 특정 공정함 조건을 만족시키도록 인풋 데이터를 변형시키는 모델 또는 함수를 학습시키기
- 모델의 인풋 데이터를 잘 고쳐보자!
- 학습 시 편향 완화 (In-Processing)
- 모델 학습 방식을 바꿔서 정확도와 공정함을 모두 목표로 하도록 모델을 훈련시켜보자!
- 적대적 학습을 이용(타겟 데이터를 예측하는 모델 ↔ 그 모델로 민감한 특성을 예측하는 모델, 후자가 민감한 특성을 예측할 수 없도록)
- Loss function에 공정함 관련 제약 값(constraint) 을 추가하기
- 모델 학습 방식을 바꿔서 정확도와 공정함을 모두 목표로 하도록 모델을 훈련시켜보자!
- 사후 처리를 통한 편향 완화 (Post-Processing)
- 데이터와 모델은 그대로 유지하고, 최종 아웃풋만 잘 조정해보자!
- 특정 공정함 조건을 만족시키도록 그룹 별로 최종 분류 threshold를 최적화하기
- 특정 공정함 조건을 만족시키도록 아웃풋 데이터를 변형시키는 모델 또는 함수를 학습시키기
- 데이터와 모델은 그대로 유지하고, 최종 아웃풋만 잘 조정해보자!
AIF 360은 각 단계별로 여러 가지의 편향 완화 알고리즘을 제공해주고 있습니다. 문서에서 세어봤는데요, 전처리에서 4개, 학습 시 7개, 사후처리 3개가 있네요.
글이 너무 길어지고 있으므로 각 단계별로 1개씩만 사용해보고 베이스 모델과 성능 및 공정성 지표를 비교해볼 것입니다. 우선 각 기법의 접근방식을 요약하고 코드 및 논문을 함께 달아두겠습니다. 각 방법이 더 궁금하다면 링크된 논문을, 그 외의 다른 기법들이 궁금하다면 AIF 360 문서에서 확인할 수 있습니다.
[전처리] Reweighing
- Data preprocessing techniques for classification without discrimination
- 민감한 속성과 라벨 조합 별로 다르게 가중치를 두어 학습하는데, 차별이 존재하는 방향과 일치하는(일반적인 편견에 부합하는) 데이터는 가중치를 낮게 주고 반대는 높게 준다.
- 즉 대출을 승인받은 고등학교 비졸업자는 대출을 승인받지 못한 고등학교 비졸업자보다 높은 가중치를 부여하고, 반대로 대출을 승인받지 못한 고등학교 졸업자 데이터에 대출을 승인받은 고등학교 졸업자보다 높은 가중치를 부여한다.
1
2
3
4
5
6
RW = Reweighing(unprivileged_groups=upgroup, privileged_groups=pgroup)
rw_train = RW.fit_transform(train)
rw_rf = RandomForestClassifier().fit(rw_train.features,
rw_train.labels.ravel(),
sample_weight = rw_train.instance_weights)
rw_test = RW.transform(test)
[학습] Adversarial Debiasing
- Mitigating Unwanted Biases with Adversarial Learning
- 예측변수(대출 승인 여부)를 예측하는 모델과 민감한 속성(교육 수준)을 예측하는 적대적 모델을 만들어 전자의 성능을 최대화, 후자의 성능을 최소화하도록 학습한다.
- 즉 이 방식의 목표는 그 예측 결과만 보고 민감한 속성 여부를 예측하기 어려운 모델을 만드는 것.
1
2
3
4
5
6
7
8
9
10
sess = tf.Session()
tf.disable_eager_execution()
ad = AdversarialDebiasing(privileged_groups = pgroup,
unprivileged_groups = upgroup,
scope_name='debiased_classifier',
num_epochs=10,
debias=True,
sess=sess)
ad.fit(train)
ad_pred = ad.predict(test)
[사후처리] Reject Option Classification
- Decision Theory for Discrimination-Aware Classification
- 모델은 예측 결과에 대해 확신이 있을 때가 아니라 헷갈릴 때 차별을 하게 된다고 본다. 예를 들면 결정 경계(decision boundary)가 0.5일 때, 어떤 데이터가 0.1이나 0.9이면 문제 없이 예측하지만 0.49나 0.51이라면 예측 불확실성이 높아지는데, 그래도 최대한 예측을 잘 하기 위해 일반적으로 이득을 보는 집단에게 더 좋은 결과(ex. 대출 승인)을 주게 된다는 것이다. 사람도 정확한 정보만으로 판단하기 애매한 케이스가 주어지면 편견에 따라 행동할 수 있다는 점을 생각하면 오..그러네..🤔? 하게 되는 아이디어.
- 따라서 이 방법은 학습이 완료된 모델의 예측 데이터를 가지고 결정 경계 근처의, 불확실성이 가장 높은 데이터만 고등학교 졸업자는 거절, 비졸업자는 승인으로 바꿔준다.
1
2
3
4
5
ROC = RejectOptionClassification(privileged_groups = pgroup,
unprivileged_groups = upgroup)
ROC = ROC.fit(test, base_test_pred)
roc_test_pred = ROC.predict(base_test_pred)
완화 처리의 효과는?
이제 제일 처음 학습시켰던 베이스 모델과 저 3가지 테크닉을 각자 적용한 추가 3개의 모델을 비교해볼 것입니다.
이전에 확인했던 4개의 공정성 지표가 얼마나 달라졌는지도 궁금하지만, 일반적으로 편향을 제거하기 위한 조치를 취하면 모델 성능은 떨어질 것 같은데 과연 그럴지도 궁금합니다.
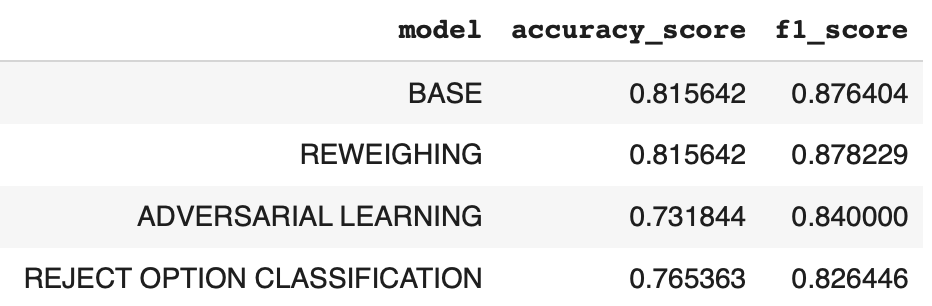
우선 성능부터 보면, Reweighing 외 다른 2개의 기법은 기존 모델에 비해 성능이 감소했음을 알 수 있습니다. 사실 공정성을 위해 보정하다 보면 성능이 떨어진다는 것은 이 공정성 논의에서 항상 당연한 것처럼 언급이 되었던 사실입니다. 다만 최근에는 trade-off 가 무조건 발생하는 것이 아니며, 항상 정확도와 공정성 간의 이상적인 최적 지점을 찾을 수 있다는 것을 이론적으로 증명하는 논문도 나오고 했더라고요.
이제 각 공정성 지표의 모델별 차이를 보겠습니다.
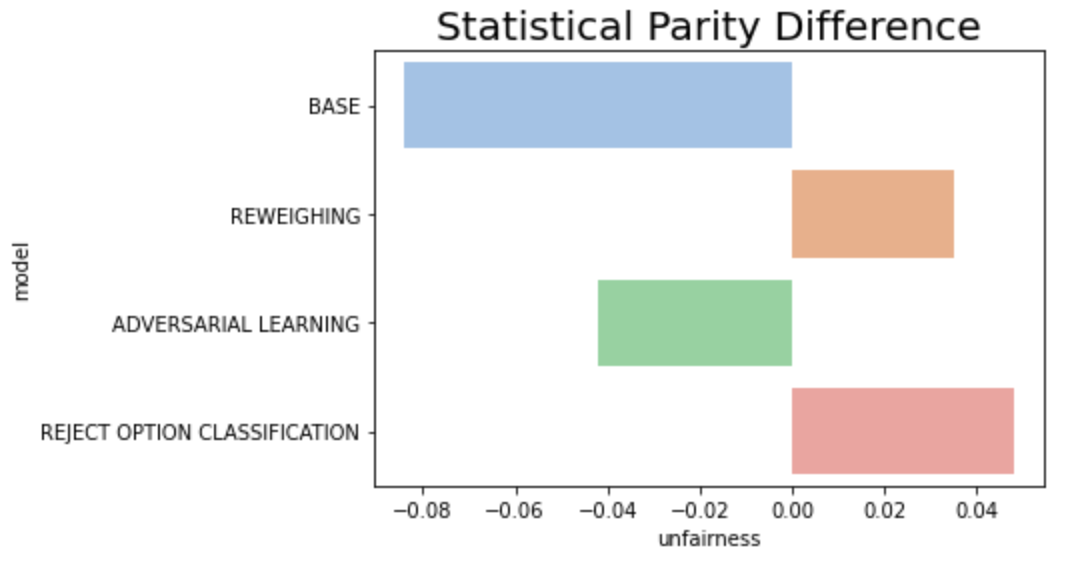
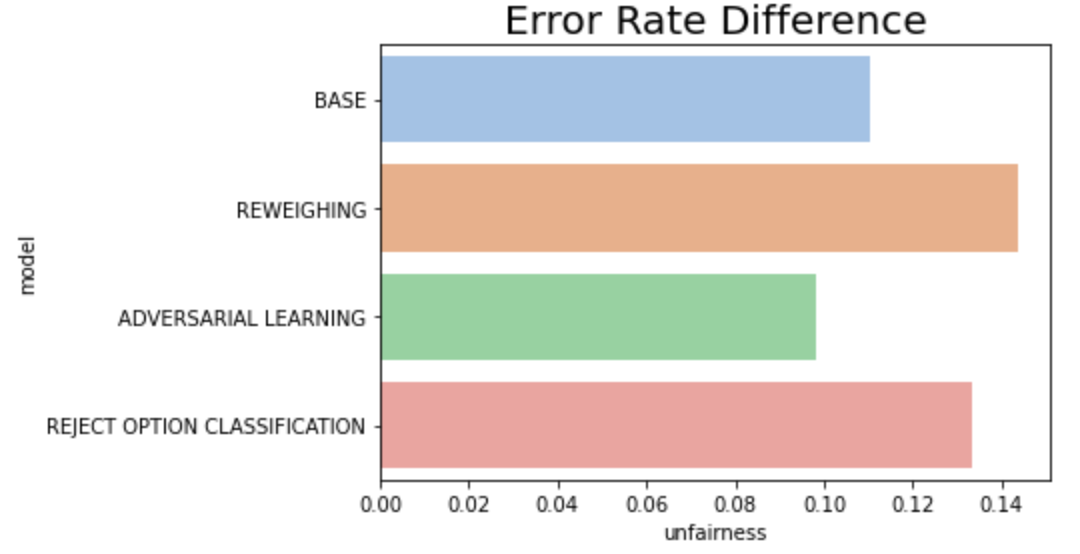
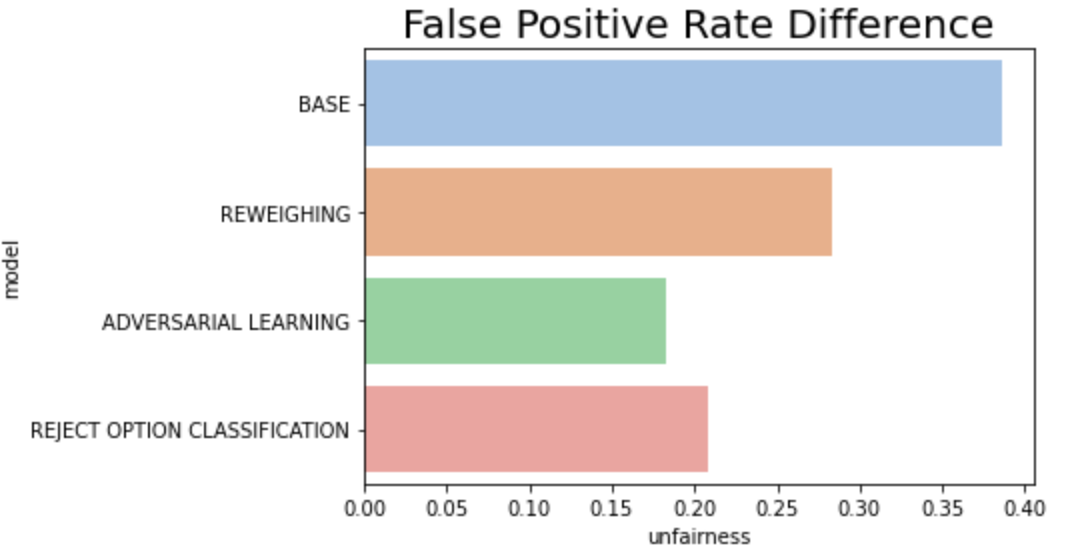
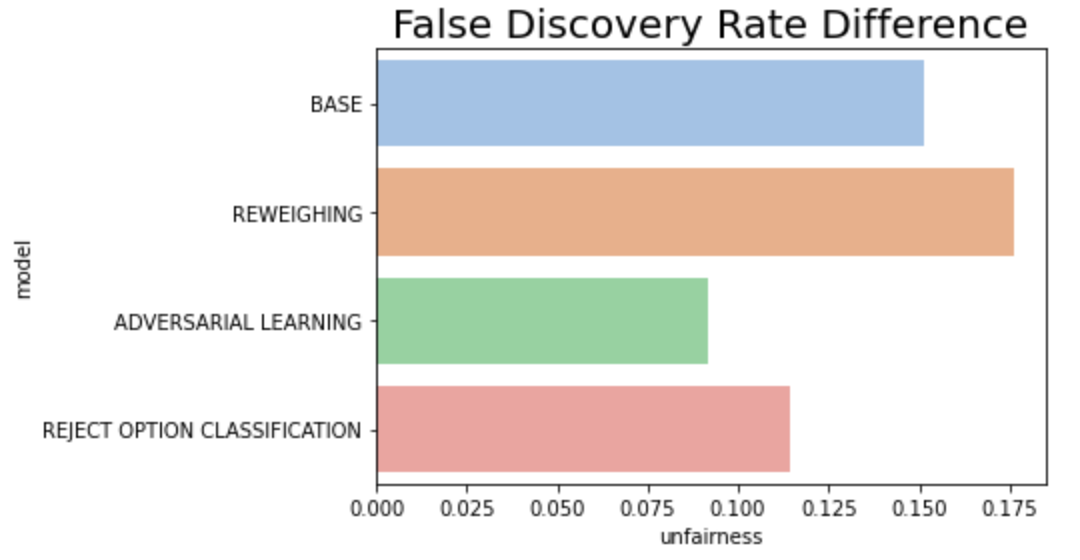
- 가장 차이가 심각했던 FPR 지표의 경우 3개의 완화 기법 모두 어느 정도 성공적으로 낮추었고, Adversarial Learning이 가장 효과가 좋다.
- Statistical Parity의 경우는 각 모델 별로 불공정의 방향성이 다른데, 모두 5% 미만대로 큰 수치는 아니라 의미가 없어 보인다.
- Error Rate이나 FDR의 경우, 일부 모델은 오히려 불공정 정도가 베이스 모델에 비해 심화되었다.
- 모델 기준으로 종합해보면 Adversarial Learning이 모든 지표를 상당 수준 이하 감소시켰으나 성능 또한 가장 큰 폭으로 감소한 기법이었다. Reweighing의 경우 성능은 유지되었으나 FPR 외의 다른 지표에서 편향을 완화하지 못했고 오히려 더 증폭하는 영향이 있었다.
여기까지 보았을 때 결론은 어떤 지표를 공정성의 정의로 사용하느냐에 따라 선택할 수 있는 완화 기법도 크게 달라질 수 있다는 것, 그리고 어떤 정의와 모델을 택하든 (최적 포인트를 찾지 못하면) 공정성과 성능 간 trade-off가 존재할 가능성이 있다는 것이 되겠습니다.