Koalas: 스파크에서 쓰는 Pandas API
중고차 가격 데이터를 가지고 Koalas를 이용한 UDF 작성과 머신러닝을 해봅니다.
Pandas는 보통 데이터 분석을 배울 때 가장 먼저 접하는 도구 중 하나입니다. 자고로 데이터 분석 기초 코스의 맨 첫 줄이라면 타이타닉 데이터셋을 pd.read_csv 로 불러오는 것 아니겠어요? 그렇게 Pandas 데이터프레임이 어떻게 생겼는지 살펴보고, 인덱싱을 하거나 칼럼을 추가하거나 하는 데이터를 전처리 하는 방법 등을 이어서 배우게 되고요. 타이타닉 이후로도 공부를 하거나 작은 수준의 프로젝트를 할 때도 pandas는 좋은 친구가 됩니다.
문제는, 저의 경험을 들어 이야기해보면, 예전에는 그다지 큰 데이터셋을 접할 일이 없었다는 것입니다. 하지만 회사에 오니 다루는 데이터의 크기가 커졌고 스파크를 만나게 되었습니다. 지금은 뭐 매일 쓰니까 pyspark가 편하지만 처음 접했을 때는 확실히 익숙해지는 데 시간이 걸렸던 것으로 기억합니다.
Koalas는 이런 경우에 유용하게 쓸 수 있는 라이브러리로, 스파크에서 Pandas API를 제공하기 위해 만들어졌습니다. 오늘은 Koalas 를 간단히 사용해보겠습니다.
개인적으로는 스파크 데이터프레임을 다루는 데에 별 불편함이 없거나, 이전에 Pandas가 익숙하지 않았다면 Koalas 는 필수는 아닌 것 같습니다. 하지만 만약 Pandas를 잘 쓰고 있던 사람이라면 새로운 프레임워크에 대한 습득 비용 없이 분산 처리 환경으로 쉽게 넘어갈 수 있는 지름길이 될 수 있을 것이라 생각합니다.
 인자한 미소의 코알라…:)
인자한 미소의 코알라…:)
Koalas는 이렇습니다.
- 모든 Pandas API 중 80% 이상을 커버한다. *안 되는것도 있어서
PandasNotImplementedError가 뜰 수도 있다 (그래도 잠깐 써보면서내가 쓸 줄 알았던Pandas 의 기능은 대부분 된다는 인상을 받았다) - Koalas 데이터프레임은 내부적으로는 pyspark 데이터프레임 위에서 만들어졌고(따라서 lazy하다), 이 라이브러리는 Pandas API를 SPark SQL의 플랜으로 변환하는 역할을 한다.
- Spark 3.0, Python 3.8, spark accessor, 새로운 Type Hint를 지원한다.
써보기
pip install koalas 로 설치해주고, 다음과 같이 불러오면 됩니다.
1
import databricks.koalas as ks
중고차 가격 데이터를 써 봤습니다. 별로 크기가 크진 않지만 빠르게 살펴보는 데 의의를 두겠습니다. 스파크 데이터프레임에서 시작해보겠습니다.
- 대충 생긴 모양은 이렇다. 원본 데이터에는 몇몇 변수에 단위가 붙어 있었는데
F.split(column, ' ')[0]으로 단위를 제거하고.cast()로 수치형으로 변환했다.1 2 3 4 5 6 7 8 9 10
sdf.show(3) >> +--------------------+--------+----+-----------------+---------+------------+----------+-------+------+-----+-----+---------+-----+-------+ | Name|Location|Year|Kilometers_Driven|Fuel_Type|Transmission|Owner_Type|Mileage|Engine|Power|Seats|New_Price|Price| Name2| +--------------------+--------+----+-----------------+---------+------------+----------+-------+------+-----+-----+---------+-----+-------+ |Maruti Wagon R LX...| Mumbai|2010| 72000.0| CNG| Manual| First| 26.6| 998.0|58.16| 5.0| null| 1.75| Maruti| |Hyundai Creta 1.6...| Pune|2015| 41000.0| Diesel| Manual| First| 19.67|1582.0|126.2| 5.0| null| 12.5|Hyundai| | Honda Jazz V| Chennai|2011| 46000.0| Petrol| Manual| First| 18.2|1199.0| 88.7| 5.0|8.61 Lakh| 4.5| Honda| +--------------------+--------+----+-----------------+---------+------------+----------+-------+------+-----+-----+---------+-----+-------+ only showing top 3 rows
- spark 데이터프레임으로부터 koalas 데이터프레임 생성하기
1
2
3
kdf = sdf.to_koalas()
type(kdf)
>> Out[18]: databricks.koalas.frame.DataFrame
- 다시 돌려놓기
1
sdf_from_koalas = kdf.to_spark()
- 물론 pandas 데이터프레임으로부터도 마찬가지로 왔다갔다 가능하다.
1
2
3
pdf = sdf.toPandas() #pandas DF로
kdf_from_pandas = ks.from_pandas(pdf)
pdf_from_koalas = kdf.toPandas() #다시 돌려놓기
저장된 파일로부터 불러올 경우 pandas와 동일하게
read_csv로 불러올 수 있으며 parquet 도 동일하게 가능, 저장할 때도 마찬가지 - 즉to_csv/read_parquet/to_parquet편한 대로 쓰면 된다.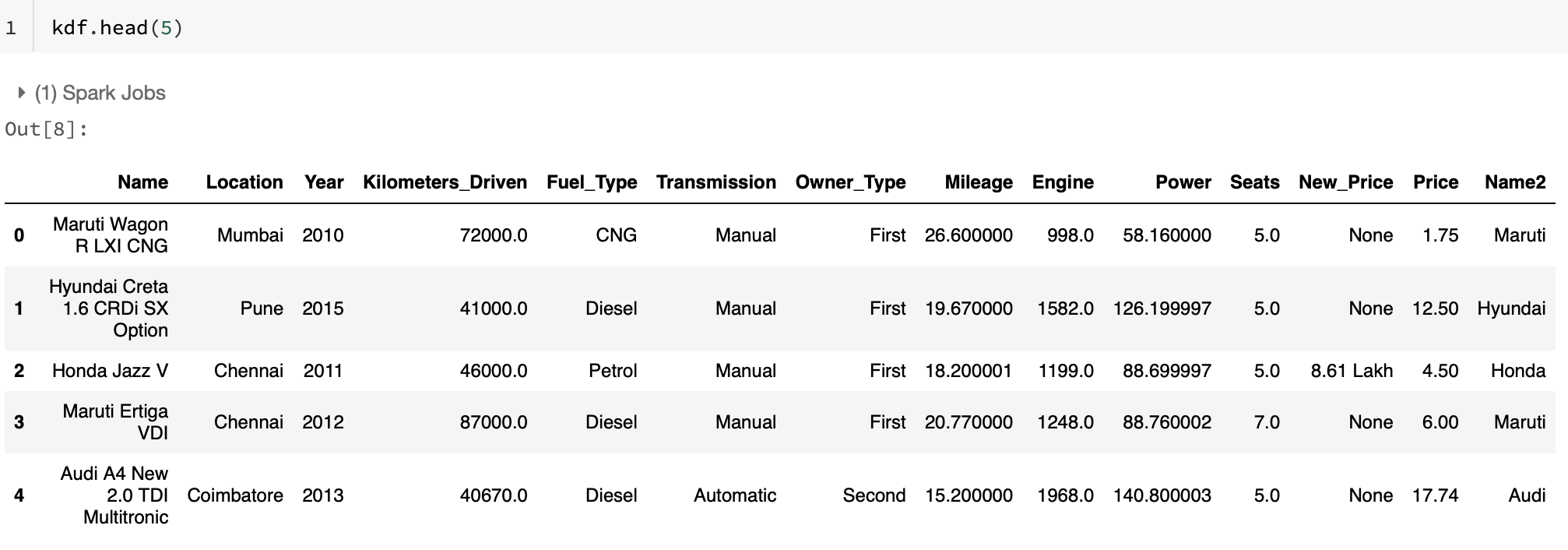 이렇게 얻은 koalas 데이터프레임을 살펴보면, 그냥 많이 보던 그 모습입니다. pandas 데이터프레임을 호출했을 때와 똑같이 생겼죠. 다른 것들도 똑같이 할 수 있는지 봅시다.
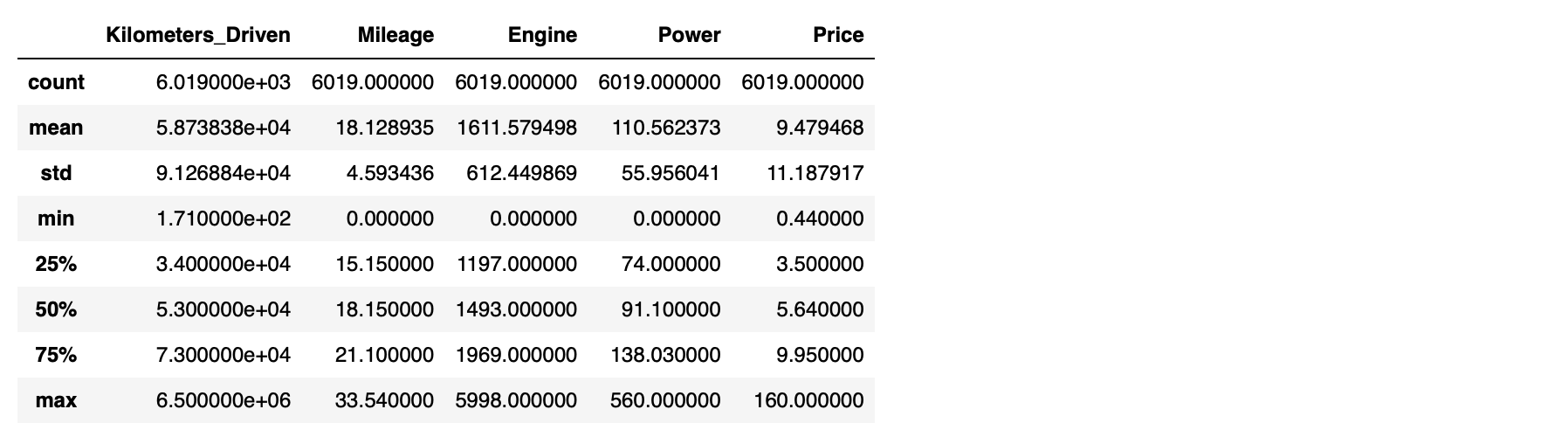
이렇게 얻은 koalas 데이터프레임을 살펴보면, 그냥 많이 보던 그 모습입니다. pandas 데이터프레임을 호출했을 때와 똑같이 생겼죠. 다른 것들도 똑같이 할 수 있는지 봅시다.df.describe()으로 수치형 변수들의 분포 살펴보기1
kdf.describe()
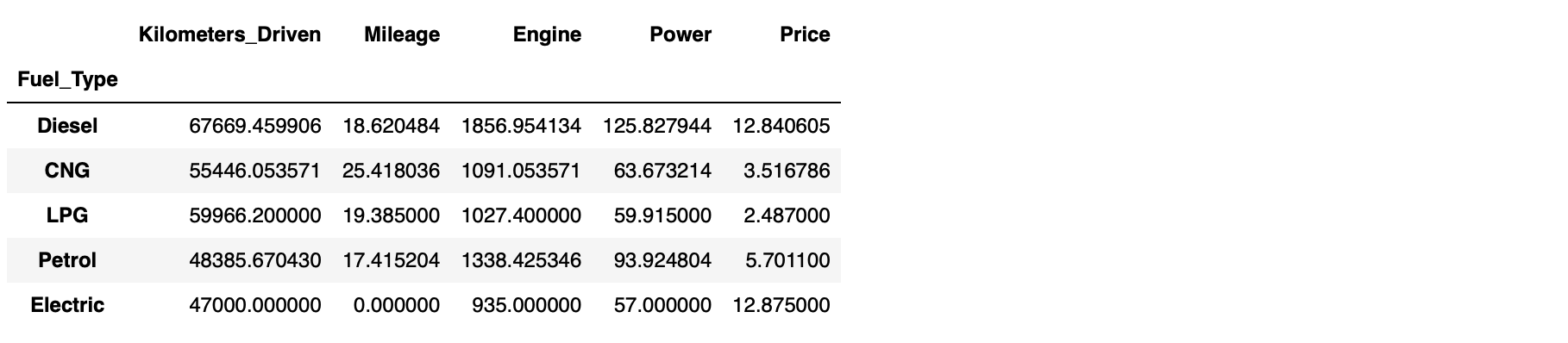
groupby()집계 후 통계치 구하기 - Fuel type 에 따른 평균1
kdf.groupby('Fuel_Type').mean()
get_dummies()로 카테고리컬 변수 처리하기1
ks.get_dummies(kdf['Fuel_Type']).head(5)

- 쓰다보니 그냥 다 똑같은 것 같다 😅
sort_index(),sort_values(),.fillna(),value_counts()등 pandas 문법과 동일하게 사용 가능 - 플랏 그리기 - 가격의 분포 히스토그램
1
kdf['Price'].plot.hist()
- 플랏 그리기 2 - 좌석 수에 따른 차의 개수 바 플랏
1
kdf['Seats'].value_counts().plot(kind='barh')

결론: pandas 와 거의 똑같아서 뭐 새롭게 적을 만한 게 없군요! 도입부에 적었듯이 koalas는 pandas를 익숙하게 쓰시는 분들에게 유용할 것입니다. 따라서 이 글도 읽는 분들이 pandas가 편하시다는 가정 하에 쓰고 있습니다. 일단 넘어가 봅시다.
UDF
스파크에서 그룹 단위의 연산을 편하게 해주는 것이 바로 Pandas UDF(User Defined Function; 사용자 정의 함수)입니다. Pandas 데이터프레임을 다루듯이 함수를 작성하고, 이를 sdf.groupBy().apply() 의 형태로 그룹 단위로 스파크 데이터프레임에 적용합니다. 벡터화된 수행이 가능하고, Scala로 작성하지 않아도 빠른 속도의 연산이 가능합니다. Pandas UDF를 한번 작성해보고 동일한 목적으로 koalas 에서는 어떻게 쓰는지 비교해 보겠습니다.
예를 들어 각 자동차 브랜드/회사 별로 데이터 내 4가지 수치형 변수를 독립변수로 하고, 가격을 종속변수로 하는 Ordinary least squares 회귀모형을 만들고 싶다고 합시다. 그리고 그룹별로 변수들의 회귀계수를 얻고자 합니다. 원본 데이터의 차종 칼럼의 맨 앞만 따와서 Name2 로 만들었습니다. (예 - Audi A4 New 2.0 TDI Multitronic → Audi )
1
2
3
4
import statsmodels.api as sm
group_column = 'Name2'
y_column = 'Price'
x_columns = ['Kilometers_Driven','Mileage','Engine','Power']
- pandas UDF
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.types as T
schema = StructType([
StructField("Name2", T.StringType()),
StructField("Kilometers_Driven", T.FloatType()),
StructField("Power", T.FloatType()),
StructField("Engine", T.FloatType()),
StructField("Milegae,", T.FloatType())
])
@pandas_udf(schema, PandasUDFType.GROUPED_MAP)
def ols_pandasudf(pdf):
group_key = pdf[group_column].iloc[0]
y = pdf[y_column]
X = pdf[x_columns]
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
return pd.DataFrame([[group_key] + [model.params[i] for i in x_columns]], columns=[group_column] + x_columns)
beta = car.groupBy(group_column).apply(ols_pandasudf)
- koalas
1
2
3
4
5
6
7
8
9
10
def ols_ks( df ) -> ks.DataFrame[ 'Name2': str, 'Kilometers_Driven':float, 'Mileage':float, 'Engine':float , 'Power':float]:
group_key = df[group_column].iloc[0]
y = df[y_column]
X = df[x_columns]
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
return pd.DataFrame([[group_key] + [model.params[i] for i in x_columns]])
beta_ks= kdf.groupby(group_column).apply(ols_ks)
pandas UDF 사용 시 가장 중요한 점은 인풋과 아웃풋이 모두 pandas 데이터프레임이 되도록 작성하는 것이고, 스키마를 선 지정해줘야 한다는 것입니다. 반면 koalas 버전의 경우 함수 작성 시 아웃풋 koalas 데이터프레임에 대한 type hinting을 하는 부분이 눈에 띕니다. 이때 -> ks.DataFrame[ str,float, float, float , float] 이런 식으로 type만 지정해줄 수도 있지만 그러면 리턴되는 데이터프레임에 컬럼 명이 설정되지 않으니 유의해야 합니다. ks.DataFrame[zip(x.columns, x.dtypes)] 이런 식으로 설정해도 됩니다.
따로 코드를 첨부하지 않았지만 그냥 pandas로 하려면 koalas나 spark dataframe을 toPandas() 로 변환 후 저 ols 함수 내의 내용을 그대로 실행해주면 될 것입니다.
어떤 방식을 이용하든 얻게 되는 계수 데이터프레임은 똑같습니다.
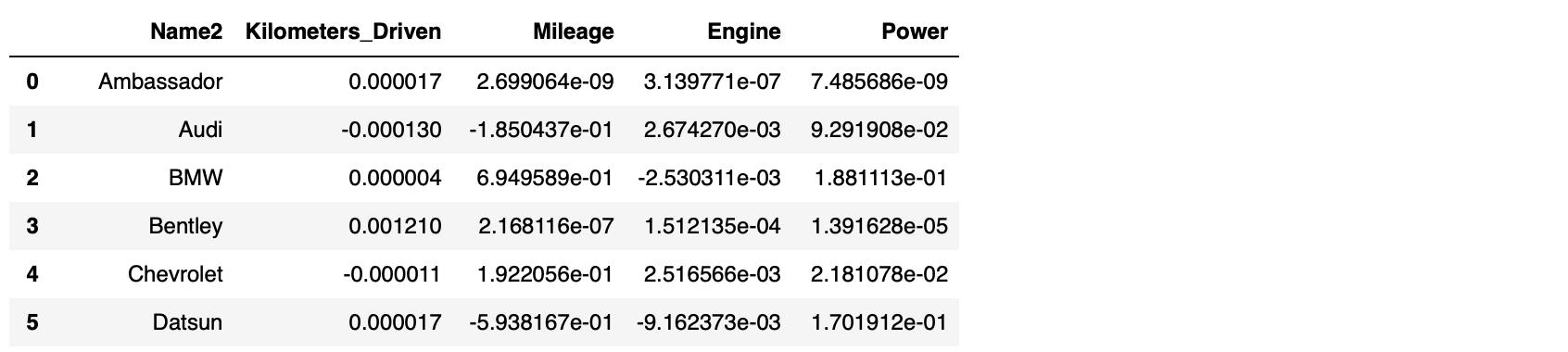
여기까지 해보고 나니 속도 차이가 궁금하네요. 우리가 지금 사용하는 데이터는 크기가 정해져 있으니 이 글 을 참고해 보겠습니다. 데이터의 크기에 따라 pandas 와 pyspark, koalas가 일반 함수와 UDF 작성 시 각각 걸리는 시간이 어떻게 달라지는지 실험한 내용입니다. 실험 조건은 다음과 같고요.
- Spark driver node : 8 CPU cores, 61GB RAM
- 15 Spark worker nodes: 4CPU cores, 30.5GB RAM each (sum: 60CPUs / 457.5GB )
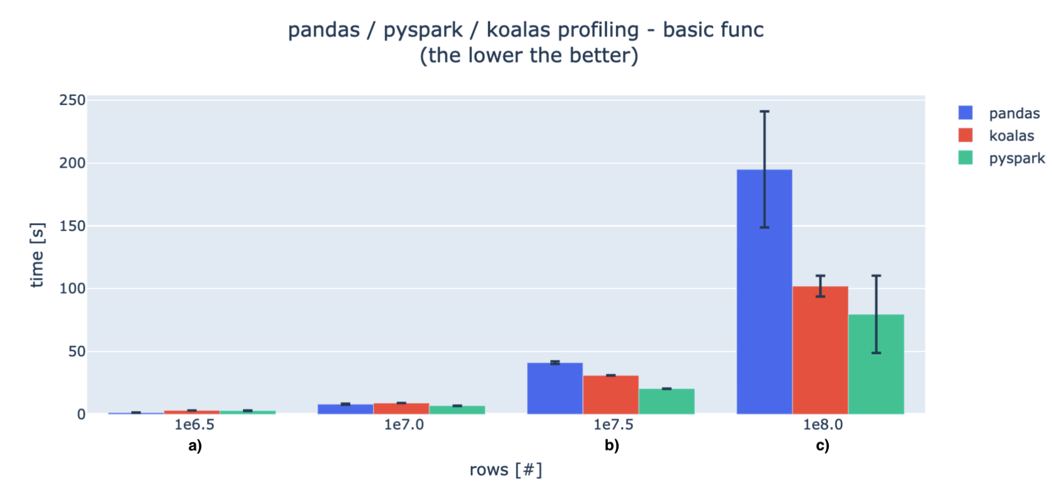
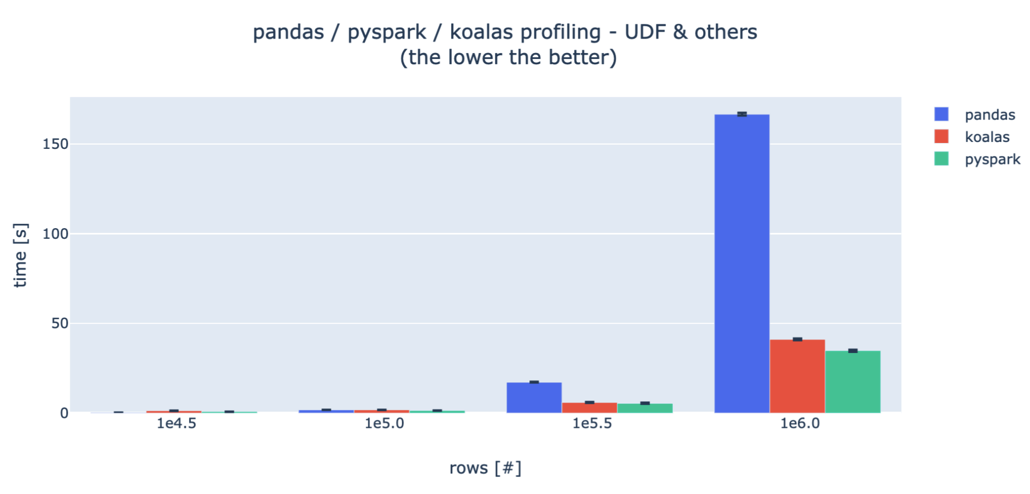
걸린 시간이므로 짧을수록 좋습니다. 데이터 수가 적을 때는 pandas가 빠릅니다. 다만 데이터의 행 개수가 늘어날수록 pyspark이 월등히 빨라지고, koalas는 그보단 조금 못하지만 거의 비슷한 수준의 시간을 보여줍니다.
머신러닝
마지막으로 중고차 가격을 예측하는 회귀 모델을 적합시켜보겠습니다. koalas 데이터프레임으로 주어진 데이터에 대해 머신러닝을 해볼 수 있는 방법은 일단 두 가지 정도가 있는 것 같습니다.
1) 훈련된 모델을 MLflow로 저장하고 불러와서 Koalas 데이터프레임에 대한 predictor로 사용한다.
MLflow는 (마찬가지로 데이터브릭스에서 만든) 머신러닝 라이프사이클을 위한 오픈소스 플랫폼입니다. 스케일링 후 데이터를 트레이닝/테스트 셋으로 나누고, sklearn의 선형회귀 모델을 훈련시키고, 모델을 저장해 둡니다. 수치형 변수들 4개만 사용해 봤습니다.
1
2
3
4
5
6
7
8
from mlflow.tracking import MlflowClient, set_tracking_uri
import mlflow.sklearn
from tempfile import mkdtemp
d = mkdtemp("koalas_mlflow")
set_tracking_uri("file:%s"%d)
client = MlflowClient()
exp = mlflow.create_experiment("r_experiment")
mlflow.set_experiment("r_experiment")
우선 이렇게 MLflow 환경을 초기화해줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
import numpy as np
import mlflow.sklearn
import mlflow
data = kdf.to_pandas()
scaler_x = StandardScaler()
scaler_y = StandardScaler()
X = data[['Kilometers_Driven','Mileage','Engine','Power']].values
X = scaler_x.fit_transform(X)
Y = data[['Price']].values
Y = scaler_y.fit_transform(Y)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.25, random_state=0)
def train_and_score_model():
with mlflow.start_run():
regressor = LinearRegression()
regressor.fit(x_train,y_train)
score = regressor.score(X=x_test, y=y_test)
# log run the model result to mlflow
mlflow.sklearn.log_model(regressor, artifact_path="model")
mlflow.log_metric("r2", score)
return score
train_and_score_model()
0.59 정도의 R2 스코어를 확인했습니다. koalas.mlflow는 이 저장된 모델을 불러올 수 있도록 지원합니다. 아래는 모델을 불러온 후, 새로운 예측 데이터(koalas 데이터프레임)을 생성하여 예측값을 얻어 보는 부분입니다.
1
2
3
4
5
6
7
from databricks.koalas.mlflow import load_model
run_info = client.list_run_infos(exp)[-1]
model = load_model("runs:/{run_id}/model".format(run_id=run_info.run_uuid))
prediction_df = ks.DataFrame({'Kilometers_Driven':[5000],'Mileage':[266.6],'Engine':[1200],'Power': [58]})
prediction_df["prediction"] = model.predict(prediction_df)
prediction_df
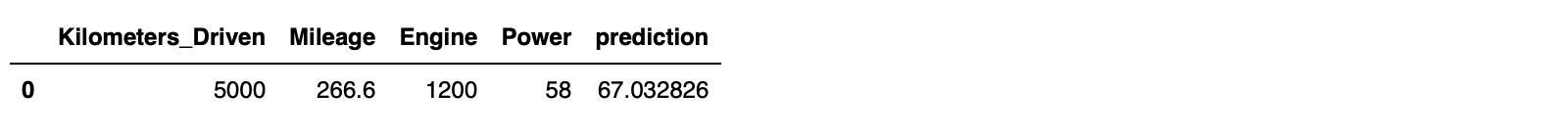
2) 그냥 SparkML을 쓴다.
간편하게 스파크 데이터프레임으로 변환 가능하므로 그냥 SparkML을 쓰는 것도 방법입니다. 스파크의 머신러닝 라이브러리로, 다양한 피쳐엔지니어링 기능과 회귀, 분류, 클러스터링 등 ML 알고리즘이 지원됩니다. 이번에는 그래디언트 부스팅 회귀 모델을 적합시켜보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.regression import GBTRegressor
sdf = kdf.to_spark()
vectorAssembler = VectorAssembler(inputCols =['Kilometers_Driven','Mileage','Engine','Power'], outputCol = "features")
vdata = vectorAssembler.transform(sdf)
splits = vdata.randomSplit([0.7,0.3])
train_df = splits[0]
test_df = splits[1]
gbt = GBTRegressor(featuresCol="features", labelCol="Price")
gbt_model = gbt.fit(train_df)
gbt_predictions = gbt_model.transform(test_df)
Evaluator를 활용해서 R2 score 확인 결과 0.75입니다.
1
2
3
gbt_evaluator = RegressionEvaluator(labelCol="Price", predictionCol="prediction", metricName="r2")
gbt_r2 = gbt_evaluator.evaluate(gbt_predictions)
print(gbt_r2)
.transform() 메소드로 만들어진 prediction 데이터프레임은 기존 정보들을 그대로 보존한 채로 prediction 만 추가한 형태이므로 이를 다시 koalas 데이터프레임으로 돌려주면 아래와 같이 예측 결과를 확인할 수 있습니다.
1
2
kdf_predictions = ks.DataFrame(gbt_predictions)
kdf_predictions.head(3)
